



A personalized learning platform is not a chatbot bolted onto a fixed syllabus. It is three systems working together: a learner-state model that updates after every interaction, a content engine grounded in your curriculum, and an analytics loop that puts the right five students in front of a teacher this week. Ship all three and the outcome gains are real but honest: effect sizes around g 0.3–0.7 in peer-reviewed studies, not the mythical two-sigma. Ship only the chatbot and you get a demo that impresses a boardroom and moves no test scores. We’ve shipped adaptive learning products since 2005, and this is the build we actually recommend to clients in 2026, covering architecture, costs, model choices, and the compliance calls that decide who wins a district contract.
Key takeaways
• Three layers, not one. A learner-state model, a grounded content engine, and an educator analytics loop. Drop any one and outcomes collapse in production.
• The effect is real, the hype is not. Peer-reviewed adaptive-learning effect sizes sit near g 0.29–0.70, not Bloom’s two-sigma. Design for the honest number.
• Grounding beats model choice. Retrieval against your curriculum plus structured output plus a golden-set eval matters more than which flagship LLM you pick.
• Costs are approachable. A standalone platform runs roughly $250K–$450K to build; inference lands near $0.04–$0.12 per active learner per month with caching.
• Compliance is the moat. FERPA, COPPA (22 Apr 2026), GDPR, and the EU AI Act decide district and enterprise procurement. Design it on day one.
Why Fora Soft wrote this playbook
We’ve been building multimedia and AI products since 2005 — 250+ projects, a 50-person team, and a hiring funnel tuned for engineers who can reason about learning-state models, LLM grounding, and education-sector data contracts. Personalized learning is not a side interest for us; it is one of the places our video, real-time, and AI work overlaps.
On the edtech side we built Scholarly, an AI learning platform now serving roughly 15,000 users, and ALDA, an AI Learning Assistant that professors across U.S. colleges use to generate syllabi, lecture outlines, and assessment banks — grounded in each institution’s approved curriculum, not the model’s open-web memory. We also shipped the platform behind BrainCert, now a $10M/year e-learning business with 100,000+ customers and 500M+ minutes delivered. What follows is the 2026 version of what we tell those clients, with the arithmetic shown.

Figure 1. The three subsystems inside a personalized learning platform and how learner signals, curriculum, and the LLM connect.
Planning an adaptive learning product?
Book a 30-minute architecture review with our edtech lead. You’ll leave with a build-vs-buy call, a rough cost band, and a shortlist of LLM and eval stacks that fit your curriculum.
What a personalized learning platform actually is
A personalized learning platform is software that adapts what each learner sees (the next lesson, question, hint, and pace) based on a live model of what that specific learner already knows and how they learn best. The key word is adapts: a course that shows everyone the same 40 videos in the same order is not personalized, no matter how much AI sits in the marketing copy.
Three properties separate a real platform from a recommendation widget. First, it holds per-learner state that changes after every interaction, not just at quiz boundaries. Second, it generates or selects content against that state, grounded in an approved curriculum. Third, it closes the loop with the human in charge — a teacher, an instructional designer, an L&D manager — because in any institutional sale that human is the buyer. The rest of this guide builds each property in turn.
The market has moved fast. The AI-powered personalized-learning segment was about $4.66B in 2025 and is tracking toward $6B in 2026 (roughly 29% annual growth, per 2026 industry estimates). Khanmigo alone went from 40,000 to 700,000 users in one school year. Demand is not the question in 2026; execution is.
Does personalized learning actually work?
Yes, but treat the size of the effect honestly. Peer-reviewed studies put adaptive-learning gains around a g 0.29–0.70 effect size — meaningful, roughly a third to two-thirds of a standard deviation, but well short of the two-sigma ceiling that gets quoted in pitch decks. A platform sold on "2x outcomes" is selling the ceiling; a platform designed around g 0.5 ships something that survives a district’s own evaluation.
Where does two-sigma come from? Benjamin Bloom’s 1984 finding that one-to-one mastery tutoring beat conventional group instruction by about two standard deviations. That is the aspiration. Software has not reproduced it at scale. A meta-analysis of AI-enabled adaptive learning from 2010–2022 (Wang and colleagues, 2024) found cognitive-outcome gains near g 0.70; a global reading-literacy meta-analysis put the number closer to g 0.29; and a 2025 meta-analysis of AI-enabled STEM personalization pooled 99 effect sizes across 32 randomized trials. The honest read: real, repeatable, and worth building — if you design for the true number instead of the marketing one.
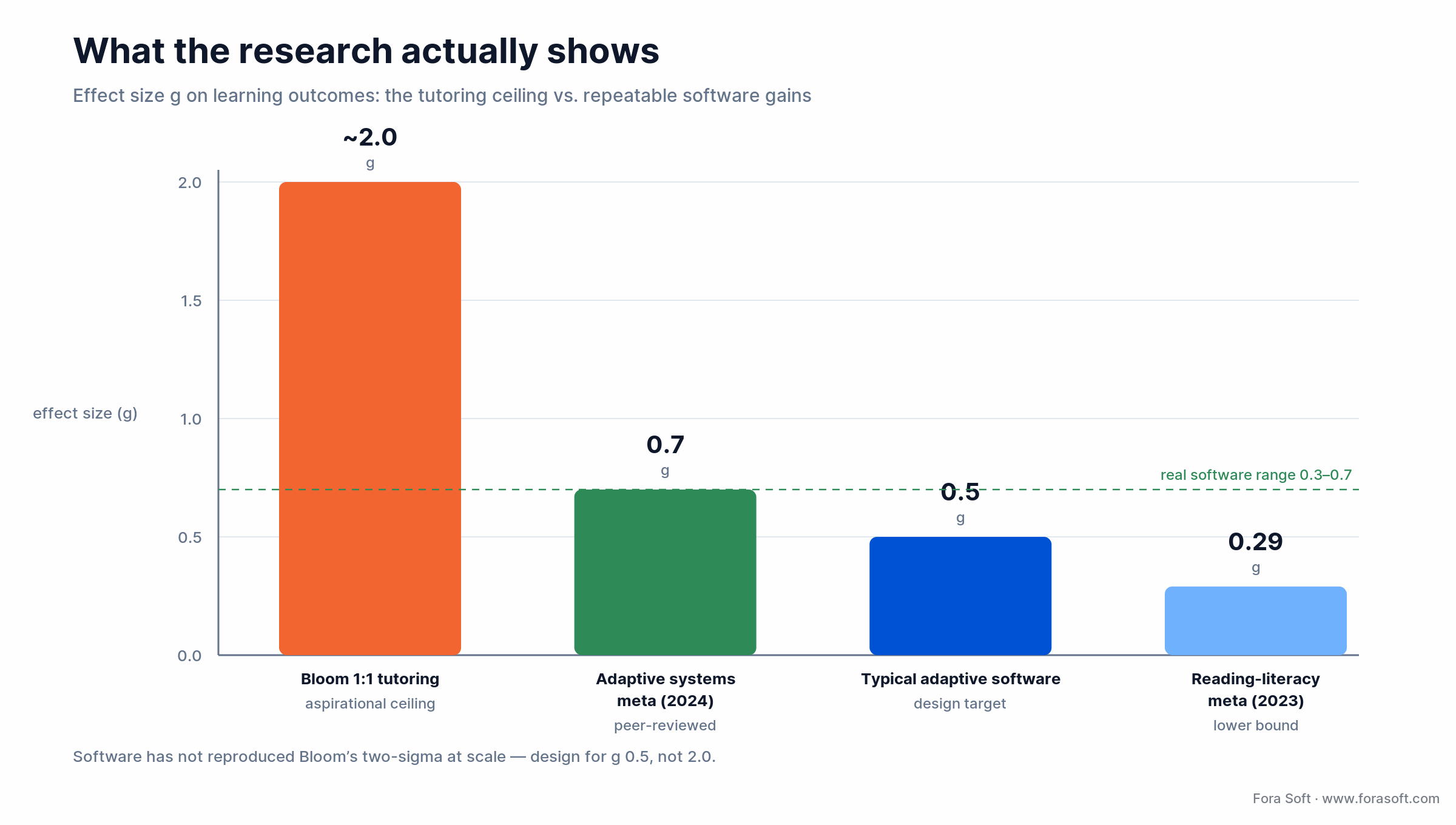
Figure 2. What the research actually shows: the two-sigma tutoring ceiling versus repeatable software effect sizes.
Reach for adaptive content when: you have more than ~1,000 active learners and real outcome data. Below that, the personalization signal is too noisy to beat a well-designed linear course.
The three-layer adaptive stack in 2026
A modern platform has three layers that must ship together. Think of them as sense, generate, and intervene. The learner-state model senses where each student is. The content engine generates the right next thing. The analytics loop routes an intervention to the human who can act on it. Skip the first and your LLM guesses blind; skip the third and no teacher trusts the output.
| Layer | Job | Core tech | Fails when |
|---|---|---|---|
| 1. Learner-state model | Track mastery, pace, engagement, at-risk signal | BKT / DKT / IRT over a feature store | You let the LLM "infer" mastery from chat |
| 2. Grounded content engine | Generate lessons, quizzes, hints on state | RAG + structured output + evals | Ungrounded generation; experts reject items |
| 3. Educator analytics loop | Rank at-risk learners, trigger action | Ranked lists + one-tap remediation | 40-chart dashboard nobody opens |
Layer 1: build the learner-state model
The foundation is a live per-learner representation — a vector of signals that updates after every meaningful action: an answered question, a completed video, a requested hint, time-on-section, a re-read. This model is the contract between your product and every LLM call. Without it, the model is guessing. Our reference schema tracks five things:
1. Mastery per concept. A 0–1 probability per skill, decayed weekly, updated with Bayesian Knowledge Tracing or a Deep Knowledge Tracing model. Item Response Theory works well when your item bank is calibrated.
2. Pace. Time-to-mastery relative to the cohort on a rolling 14-day window, so the platform can tell "moving slowly" from "stuck."
3. Engagement. Session frequency times depth. A two-minute skim is not 20 minutes with completed exercises, and your model should not treat them the same.
4. Modality preference. Which resource types produce the fastest mastery for this learner — inferred from behavior, never from a self-report survey, which correlates poorly with results.
5. At-risk composite. A drop-off probability over the next 14 days, computed from the four signals above. This is the number the analytics loop ranks on.
Implementation note: do not start by training your own sequence model. In 2026 the baseline is a managed feature store (a lightweight Postgres + Redis + pgvector or Qdrant combination) plus an open-source DKT implementation fine-tuned on your first ~10,000 learner-sessions. Build a custom model only once you have data that proves the baseline is the bottleneck.
Layer 2: the grounded content engine
This is the layer teams overbuild and underground. The pattern that ships in 2026 is four steps, and the order matters.
1. Curriculum as a corpus. Ingest textbooks, lesson plans, approved readings, and rubrics into a vector store. Chunk by learning objective, not by page — retrieval quality lives or dies on chunk boundaries.
2. Retrieve on state, not just on the question. When you generate a hint for a struggling learner, the retrieval query combines the question with that learner’s current misconception probabilities. The hint then targets the specific gap, not the generic topic.
3. Constrain the output. Use JSON-schema or tool-calling so every generated quiz item carries a stem, distractors, a correct answer, a concept tag, a difficulty estimate, and a citation pointer. Structured output is what makes teacher review and regression testing tractable.
4. Eval before every deploy. Run a golden set of 200–500 state/question pairs through each new model or prompt and score against a graded answer key. Teams that skip this ship regressions silently, then wonder why approval rates drop.
Here is the shape of a constrained quiz-item response — the schema is the point, not the wording:
{
"concept_tag": "fractions.add_unlike_denominators",
"difficulty": 0.62,
"stem": "What is 1/3 + 1/4 ?",
"distractors": ["2/7", "1/7", "2/12"],
"answer": "7/12",
"citation": "grade5_math_unit3_p14",
"targets_misconception": "adds numerators and denominators"
}
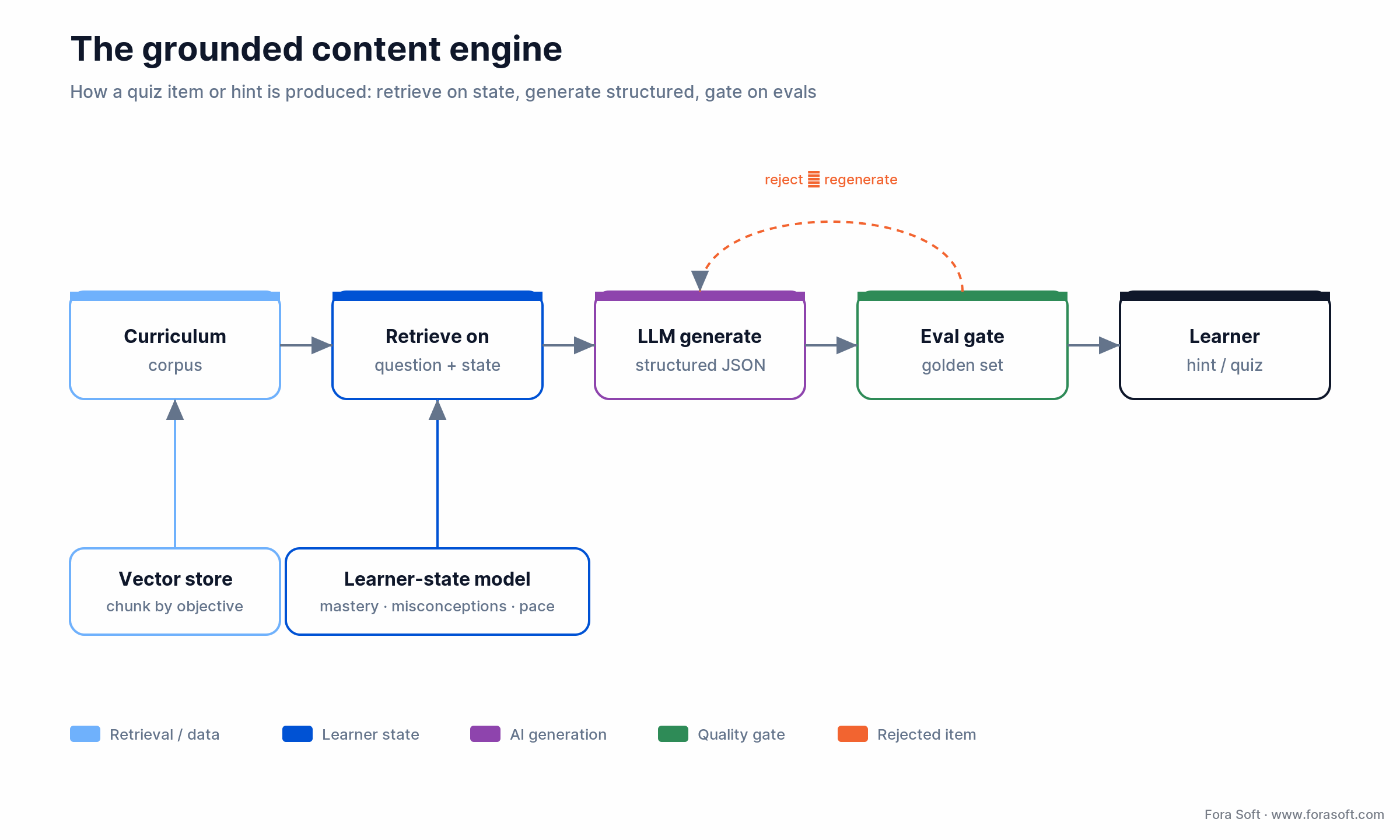
Figure 3. The generation path: curriculum retrieval combined with learner state, structured output, and an eval gate before anything reaches a student.
Reach for retrieval-grounded generation when: your subject-matter experts reject more than ~10% of ungrounded quiz items. Grounding turns rejection into a review queue you can actually clear.
Need a grounded LLM stack reviewed?
We’ve shipped RAG systems on GPT, Claude, and self-hosted open-weights for education, healthcare, and enterprise. Bring your curriculum; we’ll walk the architecture trade-offs with you.
Layer 3: close the loop with educator analytics
Most platforms fail here — not on the math, on the design. A teacher dashboard with 40 charts is worse than a ranked list of five learners, each with one flagged misconception. The rules we use with clients:
Rank, don’t visualize. The default view is a prioritized list sorted by at-risk composite, with the specific concept gap in one sentence per learner. Charts are for the curious; the ranked list is for the busy.
One-tap intervention. Every row has a "send remediation" action that generates a micro-lesson scoped to that gap. The teacher approves or edits before it goes out — human-in-the-loop is the trust layer, not a bottleneck.
Five-to-seven-day signal-to-action. If the delay between an at-risk flag and a teacher response passes a week, the learner has usually already checked out. Track this gap as a product KPI, not a system metric.
Weekly cohort digest. A Friday email with three numbers per class (mastery trend, engagement trend, at-risk count) drives more adoption in our experience than any in-app dashboard. Meet teachers where they already are.
Which LLM to use in 2026
The answer is almost always "two of them." Route roughly 80% of generations to a cheap, fast model and reserve a flagship for the hard 20% — the tricky hints, the multi-step feedback, the long-context retrieval over a full textbook. Pricing below is approximate as of July 2026 and moves often; validate against the provider’s current page before you budget.
| Model (Jul 2026) | Tier | ~Price /1M (in/out) | Where it wins |
|---|---|---|---|
| GPT-5.4 | Flagship | ~$2.50 / $15 | Instruction-following, structured output |
| Claude Sonnet 5 | Flagship | ~$3 / $15 | Long-context grounding, full-textbook RAG |
| Gemini 3.1 Pro | Flagship | ~$2 / $12 | Multimodal, diagram and image tasks |
| Gemini 3 Flash-Lite / mini class | Fast / cheap | ~$0.20–0.30 / $1.00–1.50 | The 80% of routine generations |
| Self-hosted open-weights (70B) | On-prem | Infra cost only | Under-13 K-12, EU data residency |
For any product serving under-13 learners or an EU data-residency requirement, self-host an open-weights model (Llama-class 70B) behind vLLM. The policy surface for routing student data to a hyperscaler is still rough, and self-hosting removes the question rather than answering it repeatedly in procurement.
Reach for self-hosted open-weights when: your buyer is a K-12 district or an EU public body. Data residency and a signed sub-processor list win those deals more often than raw model quality.
Personalized learning platform examples — what good looks like
Before you build, study what already works. Each platform below solved the personalization problem differently, and each teaches one lesson worth stealing.
| Platform | Approach | Lesson to steal |
|---|---|---|
| Khanmigo | LLM tutor + teacher tools, free for U.S. teachers | Teacher tools drive adoption, not learner UX alone |
| DreamBox | K-12 math, continuous adjustment on behavior | Adapt on how a learner answers, not just right/wrong |
| Squirrel AI | Fine-grained knowledge-graph decomposition | Small concept nodes give precise remediation |
| ALEKS | Knowledge-Space Theory, assessment-driven map | A clean prerequisite graph beats a flat skill list |
| Duolingo | Birdbrain difficulty model + LLM features | A tuned difficulty model carries most of the value |
The common thread: none of these won on the language model. They won on the layer underneath it — a knowledge graph, a difficulty model, a teacher workflow. Copy the layer, not the chatbot.
Build, buy, hybrid, or open-source
Four paths, and the right one depends on your team size, regulatory surface, and time-to-value target — not on which sounds most ambitious. Pick the row that matches your constraints.
| Path | Best for | Time-to-value | Main risk |
|---|---|---|---|
| Buy SaaS | Small team, generic use case | 1–2 weeks | Lock-in, no differentiation |
| Hybrid (SaaS + custom) | Mid-market, mixed use cases | 1–3 months | Integration debt, two systems |
| Build in-house | Unique data or compliance needs | 6–9 months | Velocity, talent retention |
| Open-source self-hosted | Cost-sensitive, technical team | 3–6 months | Ops burden, security patching |

Figure 4. A four-outcome decision tree for choosing your path by team size, compliance surface, and time-to-value.
Reach for build-in-house when: your curriculum, data, or compliance surface is genuinely unusual and off-the-shelf tools force you to compromise the learner-state model. Otherwise start hybrid.
What it costs to build in 2026
Two numbers decide the budget: the one-time build and the per-learner inference cost. We use Agent Engineering internally, so our build bands come in below the market-typical figures — but the shape below holds regardless of who builds it.
The inference math is worth doing out loud, because it is the number that scares founders and shouldn’t. Assume ~40 LLM calls per active learner per month, averaging 1,500 input and 600 output tokens, with 80% on a cheap model and 20% on a flagship:
Cheap tier (32 calls): 32 x (1500 x $0.20 + 600 x $1.00) / 1e6 = $0.029 Flagship ( 8 calls): 8 x (1500 x $2.50 + 600 x $12.0) / 1e6 = $0.088 ------------------------------------------------------------------- Per active learner / month ~= $0.12 (before caching) With aggressive caching on grounded content ~= $0.04 - $0.12

Figure 5. The per-learner inference math and one-time build bands at a glance.
At 10,000 active learners, that is roughly $400–$1,200 a month in model spend — a rounding error next to the team building the product. The build itself is the real line item:
| Scope | Build band | Timeline | Included |
|---|---|---|---|
| Adaptive module in existing LMS | $120K–$200K | 4–5 months | Learner-state + RAG + basic dashboard, via LTI 1.3 |
| Standalone 3-layer platform | $250K–$450K | 6–9 months | All three layers + auth, billing, mobile, FERPA groundwork |
| Curriculum content-ops | +15–25% of build | Ongoing | Normalizing and tagging your corpus — the line most budgets miss |
The biggest variance is not engineering. It is how much curriculum you have to normalize and tag before the retrieval layer is useful. Budget for content operations explicitly, or it eats your timeline quietly.
Want a cost band for your curriculum?
Send us your subject scope and learner count. We’ll come back with a build band, an inference estimate, and the content-ops line other quotes leave out.
Mini-case: Scholarly and ALDA
Situation. A university partner wanted faculty to generate personalized course content (syllabi, lecture outlines, assessment banks) from a one-line prompt, without letting a general model invent facts outside the department’s approved reading list. Free-form ChatGPT had already produced material that three professors rejected on sight, and trust was the blocker.
Plan. We built ALDA on three decisions that mirror this whole guide. Every prompt is grounded against the institution’s curriculum via a vector store, so output stays inside what each department will accept. Output is structured, not free-form (week, learning objective, readings, activities, assessment), which lets the LMS render it and lets us regression-test it. And professor edits to a generated draft become few-shot examples for that instructor’s next generation, so personalization compounds across a single semester. The same pattern powers Scholarly for its ~15,000 users.
Result. Grounding plus structured output moved faculty from rejecting drafts to editing them — a different relationship with the tool entirely. The lesson generalizes past education: ground the model in your domain documents, constrain the output shape, and let corrections train the next call. Want a similar assessment for your platform? Book a 30-minute review and we’ll sketch the architecture for your curriculum.
Compliance in 2026: FERPA, COPPA, GDPR, EU AI Act
Compliance is not the boring part; it is the part that wins or loses the deal. In any institutional sale, the security review happens before the feature demo matters. Design these on day one — retrofitting privacy architecture costs three-to-five times more than building it in.
FERPA (US). Segregate directory data from education records, sign a data-processor agreement with every LLM vendor in the pipeline, and keep student PII inside your VPC unless a signed exception covers it. The U.S. Department of Education’s Student Privacy office publishes the school-official exception rules (34 CFR 99.31) you will be held to.
COPPA (US, under-13). The FTC’s amended rule reaches full compliance on 22 April 2026 and now treats biometric identifiers, including voiceprints, as personal information. If any learner might be under 13, verifiable parental consent is a day-one requirement, not a launch-week scramble.
GDPR (EU). Use EU-region or self-hosted models for data residency, capture explicit consent, and make sure right-to-erasure cascades all the way to your feature store and vector database — a deletion that leaves embeddings behind is not a deletion.
EU AI Act. Education systems are classified high-risk under Annex III. The November 2025 Digital Omnibus deferred the high-risk obligations to 2 December 2027 (AI embedded in regulated products follows on 2 August 2028), but the Article 50 transparency duty, disclosing AI-generated content to users, applies from 2 August 2026. The official Act tracker is the reference to watch as dates firm up.
Skip teacher-less generation when: your audience is K-12 or otherwise regulated. Teacher-in-the-loop review is the trust layer that carries you through a district’s security check.
A decision framework in five questions
Before you commit a budget, answer these five in order. The answers usually pick the path for you.
Q1. Do you have more than 1,000 active learners with outcome data? No: buy or run a linear course first; you lack the signal to personalize. Yes: continue.
Q2. Is your curriculum unusual enough that off-the-shelf tools force a compromise? No: hybrid. Yes: lean toward build.
Q3. Do you serve under-13 learners or an EU public body? Yes: plan self-hosted models and consent flows from day one. No: a hosted flagship is fine.
Q4. Who is the buyer — the learner, or a teacher/admin? If it’s the institution, your teacher dashboard is as important as your learner UX. Fund it accordingly.
Q5. Can you staff content operations? If nobody owns curriculum normalization and tagging, your retrieval layer will underperform no matter how good the model is. If not, that’s the first hire — or the reason to bring in a team that has done it.
Five pitfalls we watch clients hit
1. Skipping the learner-state model. "We’ll let the model figure out what the student knows from the conversation." It works in a demo and collapses in production. The learner-state model is the contract between your product and every LLM call — write it first.
2. No offline eval suite. Ship a golden set on day one. Without it you cannot safely upgrade models, rewrite prompts, or trust your own numbers. Models change monthly now.
3. Under-grounding. Teams lean on a model’s base knowledge instead of their curriculum, then wonder why experts reject a third of generated items. Retrieval against approved sources is not optional for educational content.
4. Privacy retrofitted, not designed. FERPA, COPPA, and GDPR decisions (PII segregation, residency, processor contracts, opt-out flows) cost far more to bolt on later. For K-12, treat COPPA as a day-one constraint.
5. Teacher UX as an afterthought. Platforms that nail learner UX and ship a weak teacher dashboard churn on the teacher side — and the teacher is the buyer. Give the dashboard a real designer, not a leftover sprint.
KPIs: what to actually measure
Learning KPIs. Mastery gain per concept (pre/post), time-to-mastery, and item-level approval rate from your subject-matter reviewers. If reviewers approve fewer than ~90% of generated items, your grounding needs work before your model does.
Product KPIs. Signal-to-intervention time (target under five days), weekly active teachers, and remediation acceptance rate — how often a teacher sends the AI-suggested micro-lesson without heavy edits. That last one measures whether your generation is actually trusted.
Reliability KPIs. Generation latency at p95, eval-suite pass rate on every deploy, and cache hit rate on grounded content — the number that keeps inference cost near $0.04 rather than $0.18 per learner.
When not to build a personalized learning platform
Honesty sells better than a pitch, so here is when the answer is no. If you have fewer than a thousand active learners, the personalization signal is too noisy — a well-sequenced linear course will beat a thin adaptive one, and it costs a fraction to build. If your content changes weekly (news, fast-moving compliance), the tagging overhead may never pay back. And if nobody on your side can own curriculum content operations, hold off: the retrieval layer will disappoint no matter how good the model, and you’ll blame the AI for a data problem.
In those cases, start with a strong linear course plus a light recommendation layer, gather outcome data for a semester, and revisit personalization once the signal is real. We’ll tell you that on a call rather than sell you a build you don’t need yet.
Prioritize output format when: you can only build one thing well. Interactive practice and video beat generated text for retention in most subjects. Personalize the practice before you personalize the prose.
FAQ
What is a personalized learning platform?
It is software that adapts the next lesson, question, hint, and pace to each learner based on a live model of what they know and how they learn. A real platform has three parts: a learner-state model, a curriculum-grounded content engine, and an educator analytics loop. A fixed course with an AI chatbot on top is not personalized.
What is the best personalized learning platform for teachers?
For classroom use, Khanmigo leads on teacher tools and is free for U.S. educators; DreamBox is strong for K-12 math; ALEKS suits higher-ed math. The "best" one depends on subject and grade band. If you need it to match your own curriculum and data rules, a custom or hybrid build usually beats any off-the-shelf option.
How much does it cost to build a personalized learning platform?
An adaptive module inside an existing LMS runs about $120K–$200K over 4–5 months; a standalone three-layer platform is roughly $250K–$450K over 6–9 months. Add 15–25% for curriculum content operations. Inference lands near $0.04–$0.12 per active learner per month with caching.
Does personalized learning actually improve outcomes?
Peer-reviewed studies show real but moderate gains — effect sizes roughly g 0.29–0.70 depending on subject and design. That is meaningful, but short of Bloom’s two-sigma tutoring ceiling, which software has not reproduced at scale. Design for the honest number and outcomes hold up under a district’s own evaluation.
Which LLM is best for a personalized learning platform?
Use two. Route ~80% of routine generations to a cheap, fast model (a Gemini 3 Flash-Lite or mini-class model) and reserve a flagship (GPT-5.4, Claude Sonnet 5, or Gemini 3.1 Pro) for the hard 20%. For under-13 or EU-residency products, self-host an open-weights 70B model via vLLM.
How do we keep AI-generated content aligned with curriculum standards?
Ground generation in a vector store of approved curriculum documents, enforce structured output with a citation field, and run a golden-set eval against a subject-matter expert’s answer key before every deploy. Retrieval plus structured output plus evals is what keeps output inside state standards or your institution’s objectives.
Can it integrate with Canvas, Moodle, or Google Classroom?
Yes. LTI 1.3 is the standard path for Canvas, Moodle, Schoology, and Blackboard; Google Classroom and Microsoft Teams for Education expose their own APIs. Ship the adaptive module as an LTI 1.3 tool first, then add grade passback, roster sync, and deep linking based on customer demand.
What privacy rules apply in 2026?
FERPA governs U.S. education records; COPPA reaches full compliance on 22 April 2026 for under-13 users and now covers voiceprints; GDPR governs EU data with residency and right-to-erasure duties; and the EU AI Act classifies education as high-risk, with transparency duties from 2 August 2026 and high-risk obligations deferred to 2 December 2027. Architect all four on day one.
What to read next
Adaptive learning
AI Tutor and Adaptive Learning: 2026 Build Playbook
The tutoring companion to this guide — mastery models and student-facing design.
Case study
AI Learning Platform: Build Lessons from Scholarly
What 15,000 users taught us about shipping an AI learning platform.
Content engine
Educational Content Creation with AI: 2026 Build Guide
A deeper look at the RAG-plus-evals pattern behind Layer 2.
Buyer’s guide
AI Video Platforms for E-Learning: 2026 Buyer’s Guide
Tools, costs, and compliance for the video layer of your platform.
Ready to build your personalized learning platform?
A personalized learning platform is three layers, not one: a learner-state model that senses, a grounded content engine that generates, and an analytics loop that puts an intervention in front of a teacher inside a week. Ship all three and the outcome gains are real (g 0.3–0.7, honestly), and the costs are approachable: roughly $250K–$450K to build a standalone platform and cents per learner to run it. Skip a layer and you get a demo that impresses and a product that stalls.
The teams that win spend their effort on the unglamorous parts — curriculum normalization, offline eval suites, and privacy architecture designed on day one. That is exactly the work we’ve done since 2005, on Scholarly, ALDA, and BrainCert. Bring us your curriculum and learner count, and we’ll come back with an architecture and a number.
Scope your adaptive learning build in 30 minutes
We’ll sketch the three-layer architecture for your curriculum, flag the compliance blockers for your market, and give you a cost band before you hire a team.








