



Key takeaways
• Benchmark word error rates do not survive a real call. Microsoft’s NOTSOFAR-1 team measured one meeting corpus at 12.0% error on headset mics, 32.4% on far-field multi-channel and 46.8% on a single far-field mic. Same corpus, same team, three different products.
• Captions become a US legal requirement on 12 January 2027. 47 CFR § 14.21(b)(2)(iv) obliges interoperable video conferencing services to ship at least one captioned mode, verbatim and synchronous; § 14.21(b)(4) adds user controls for caption size, font, position, colour and opacity.
• The “99% accuracy” rule everyone quotes does not exist. It is an arithmetic example inside a voluntary best-practices clause of a television rule. The FCC said in 2014 that its standards are qualitative, not numeric.
• Per-track billing turns one meeting into six invoices. A 60-minute call with six participants is six billable audio hours, not one — and some vendors meter the WebSocket, not the speech.
• Endpointing owns your latency, not the model. Inference is 100–400 ms. Deciding that someone stopped talking is 200–800 ms.
Real time transcription is speech-to-text that emits words while someone is still speaking — typically 0.6 to 2.1 seconds behind the speaker on a video call — instead of processing a finished recording. This guide is how to build it into a video product in 2026: what accuracy really looks like on a call, where the latency goes, what a call costs, and the two regulatory deadlines that now apply.
Why Fora Soft wrote this guide
Most articles about real-time transcription are written by people selling an API. We build the products that consume those APIs, which is a different job and produces a different list of opinions. On VOLO.live we shipped live subtitles for Black Hat Briefings 2025 with over 22,000 attendees scanning a QR code and reading captions on their own phones. No app install, no per-seat licence, and no second chance if the caption rail stalls in front of a room that size.
On TransLinguist we run closed captioning in 22 languages and session transcription in all 75+ supported languages, on a MediaSoup stack, across Google Cloud Speech-to-Text, Deepgram and Speechmatics at the same time. That platform won the NHS (NOE CPC) National Framework for language services across the UK, so its transcripts end up in front of clinicians, councils and police forces. When we say a vendor benchmark does not predict production accuracy, it is because we have watched three of them miss on the same audio in the same week.
Fora Soft has been building video and real-time communication software since 2005 — 250+ projects, 50 in-house engineers. This guide is the internal checklist we hand to a client who has just asked us to put captions on their calls: what the numbers really look like, what the audio path has to do, what it costs per call rather than per hour, and the two regulatory dates that are now on the roadmap whether anyone planned for them or not.
Adding captions to a product that is already live?
Send us the stack and the deadline. We will come back with the audio-path change, the vendor shortlist and the per-call cost before you sign anything.
What real-time transcription actually is
Real time transcription — more usually written real-time transcription — is speech-to-text that emits words while someone is still talking, instead of waiting for the recording to finish. In a video call it runs as a streaming session: audio is sent to a recogniser in small chunks over a WebSocket, and the recogniser sends back two kinds of result. Partial (or interim) results are its best guess so far and they change as more audio arrives. Final results are frozen once the recogniser decides a phrase has ended.
That two-stage output is the whole design problem. Partials arrive fast and look alive; finals arrive late and are correct. Show only finals and your captions lag by a second or more. Show partials on the user-facing rail and words rewrite themselves under the reader’s eyes, which is worse than lag.
Batch transcription is the other mode: upload the recording, get a transcript back minutes later. It is cheaper, more accurate and useless during the call. Most production stacks run both — streaming for the live rail, batch for the stored transcript — and we come back to why that combination is usually the right answer.
| Streaming (real time transcription) | Batch | |
|---|---|---|
| Latency | 0.6–2.1 s from speech to screen | Minutes after the call, longer in a queue |
| Accuracy | Lower — the model commits before the sentence ends | Higher — full context, and you can afford a bigger model |
| Price | $0.12–$1.44 per audio hour across the vendors in this guide | Roughly half that on most vendors; effectively the same on AWS and Deepgram |
| Billing unit | Often the WebSocket session, so idle time can count | Audio duration |
| Use it for | Live captions, accessibility, agent assist, live translation | Stored transcripts, search, summaries, compliance archives |
One naming note, because these terms get used interchangeably and are not the same thing. Real time captioning is the presentation layer — the rail of text on screen, with its line breaks, timing and contrast rules — though the stenography profession uses “realtime captioner” for a person who does both jobs at once. Real time transcription is the recognition layer underneath. And live captioning software normally means a packaged product bundling both plus a UI, which is the buy side of a decision we work through later. You can have excellent transcription and unreadable captions; those are separate failure modes with separate fixes.
Reach for streaming when: a human has to act on the words before the call ends — captions, accessibility, live translation, agent assist. If the transcript is only read afterwards, batch is cheaper and more accurate, and you should not be paying streaming rates for it.
The demo number is not your number
Every published accuracy figure you have seen for streaming speech recognition was measured on audio that does not resemble a video call. The HuggingFace Open ASR Leaderboard, pulled on 26 July 2026, has its leading English short-form entries at 4.4–4.7% word error rate, with the widely-used open checkpoints landing between 5% and 7%. Those evaluations run on read speech recorded into a good microphone.
Microsoft’s NOTSOFAR-1 dataset is the cleanest counter-example in the literature, because one team measured one meeting corpus across three microphone setups and published all of it: 12.0% on close-talk headsets, 32.4% on multi-channel far-field devices, and 46.8% on a single far-field channel (development set). On the overlap-heavy session subset the far-field numbers reach 38.0% and 54.9%.
Two caveats before you quote those figures. The three pipelines are not literally identical — the multi-channel variant runs a seven-channel separation front end where the single-channel variant runs one, and the close-talk path skips separation altogether. And the metric is tcpWER, which charges you for speaker-attribution and timing errors as well as wrong words. The same paper’s speaker-agnostic metric, tcORC WER, gives 9.3%, 26.7% and 38.5% for the same three conditions. So part of the headline gap is the room and part of it is the difficulty of knowing who said what — which is the pair of problems a captioning product has to solve together anyway.
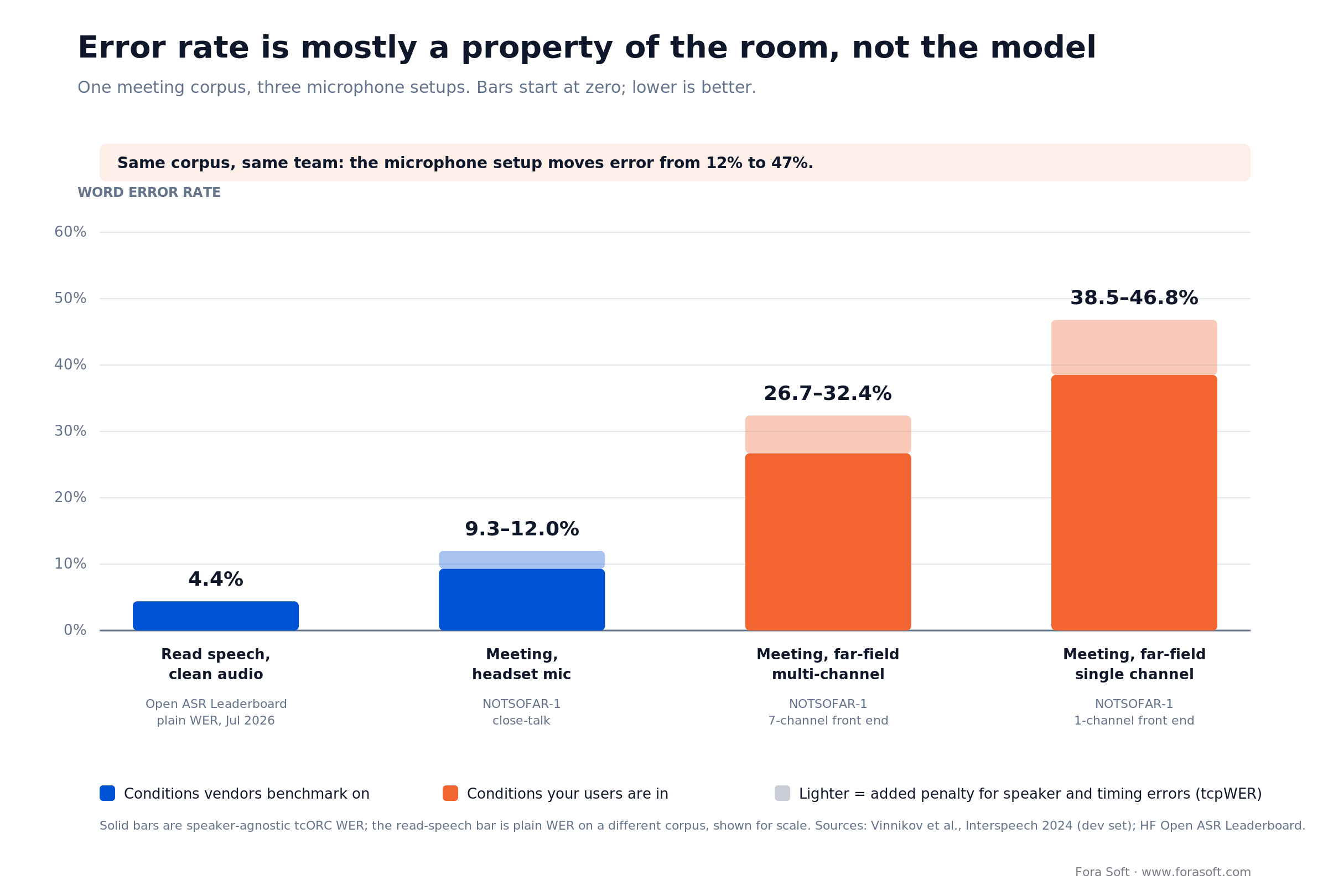
Figure 1. One meeting corpus, three microphone setups. Solid bars are the speaker-agnostic metric; the lighter extension is the extra penalty once speaker attribution and timing are scored too. The read-speech bar is plain word error rate on a different corpus, shown for scale.
The CHiME challenges tell the same story from a different direction. In CHiME-8 DASR (2024) the two official baselines scored 56.5% and 62.6% macro tcpWER on real distant-microphone meetings; the winning submission got to 19.90%. CHiME-9’s MCoRec task, which closed in February 2026, saw a 51.99% baseline and a 30.18% winner. These are the best systems teams could build with months of tuning, on the exact problem your product has. (CHiME-9 ranks entries on a joint error metric; the figures above are the speaker-mean word error rates from the same results table.)
Whisper large-v2’s own paper contains the spread inside a single model, with greedy decoding: 2.7% on LibriSpeech test-clean, 16.9% on AMI headset audio, 36.4% on AMI single distant microphone. A 13.5× difference, same weights. Purpose-built systems close the absolute gap without closing the ratio: the best AMI headset result in the BigSSL study (Zhang et al., IEEE JSTSP 16(6), 2022) is 7.8%, and the best single-distant-microphone result in that same table is 17.7% — still more than two to one apart.
The practical consequence: if you are quoting a vendor’s benchmark to a stakeholder, you are quoting the wrong number by a factor of three to four. Budget for 15–35% word error on real calls with mixed hardware, and treat anything better as a win you earned with good audio capture rather than a good model.
Reach for a headset mandate when: accuracy matters more than convenience — medical dictation, legal proceedings, anything that gets read back later. Moving one conference-room speakerphone to individual headsets is worth more error reduction than any model swap on the market.
Who your recogniser fails first
Speech recognition error is not distributed evenly across your users, and the disparity is large enough to be a product risk rather than a research footnote. Koenecke et al., PNAS 2020 measured five commercial systems against matched recordings and found an aggregate word error rate of 0.35 for Black speakers versus 0.19 for White speakers. The best system of the five scored 0.27 against 0.15; the worst, 0.45 against 0.23.
The number that matters for product decisions is further down the same PNAS paper: if you treat a word error rate above 0.5 as an unusable transcript, then Koenecke et al. found 23% of snippets from Black speakers were unusable against 1.6% from White speakers. That is not a quality gradient. It is a subset of your users for whom the feature does not work at all.
The authors also ran a control on 206 utterances with identical ground-truth text — same words, different speakers — and the gap held, which places the cause in the acoustic model rather than the language model. Retraining the text side will not fix it.
Four more findings worth having on the wall before you write acceptance criteria:
- Whisper, peer-reviewed: 9.52% word error rate for Black or African American speakers against 3.96% for White speakers on Meta AI’s Fair-Speech dataset (Interspeech 2024).
- Accented conversational English: Whisper scores 19.7% on the Edinburgh International Accents of English Corpus against 2.7% on LibriSpeech test-clean (ICASSP 2023) — more than seven times worse.
- US dialects: Whisper-medium measured 0.205 on Standard American English, 0.224 on African American Vernacular English, 0.382 on Chicano English and 0.422 on Spanglish (Findings of EMNLP 2024).
- Impaired speech: the University of Illinois Speech Accessibility Project measured a 36.3% baseline against 3.4% for typical speakers, and in-domain fine-tuning brought it to 23.7% (JSLHR 67(11), 2024). On a later data release the Interspeech 2025 challenge moved Whisper large-v2 from 17.82% zero-shot to 8.11% for the winning system.
Two things follow. First, your evaluation set has to include the accents and speech patterns of your actual user base, not a public benchmark. Second, fine-tuning is the lever that works: on the Speech Accessibility data, in-domain training cut error from 36.3% to 23.7%, and on the later release the challenge winner halved 17.82% to 8.11%. Both are far bigger moves than any vendor switch will give you.
Not sure how your recogniser performs on your users?
We build evaluation sets from real product audio — accents, hardware, packet loss and all — and benchmark vendors against it rather than against a leaderboard.
Where the 99% accuracy myth comes from
There is no FCC rule requiring 99% caption accuracy. The figure is quoted constantly, including by accessibility vendors, and it traces back to a single arithmetic illustration inside a clause that is explicitly voluntary.
Here is the actual chain. 47 CFR § 79.1 sets caption quality standards, and § 79.1(j)(2) requires captions to be “accurate, synchronous, complete, and appropriately placed.” No percentage appears anywhere in the operative text. The number lives in § 79.1(k)(2)(iv), a best-practices subsection, as a worked example: 7,000 total words minus 70 errors equals 0.99, or 99% accuracy. In the order that adopted the rule (FCC 14-12, February 2014) the Commission said its standards were “qualitative rather than quantitative,” declined to adopt any numeric accuracy standard, and explained that it would “focus more on the end result” than on a strict percentage — notwithstanding the numeric rates parties had proposed on the record.
There is a second problem with the citation. § 79.1 is titled “Closed captioning of televised video programming” and its scope provisions limit it to programming distributed for residential use by television stations and cable operators. It has never applied to a video call.
So what numbers are defensible? Two, and both are lower than 99%:
| Figure | What it actually is | Source |
|---|---|---|
| 98% | Threshold for an acceptable live subtitle under the NER model, the assessment framework used by European broadcasters | Romero-Fresco & Pöchhacker, Linguistica Antverpiensia 16 (2017) |
| 96% at 180 wpm | Pass mark for the Certified Realtime Captioner credential (the RPR credential is 95%) | National Court Reporters Association |
| Qualitative | The actual FCC standard: accurate, synchronous, complete, appropriately placed, minus de minimis errors | 47 CFR § 79.1(j)(2)–(3) |
| No figure | WCAG 2.2 SC 1.2.4 Captions (Live), Level AA — requires captions, sets no accuracy or latency number | W3C |
| 4.5 s mean latency | Ofcom’s target for live subtitles; its own four measurement rounds found 5.1–5.6 s in practice | Ofcom Access Services Guidelines, April 2024 |
One more caveat that should change how you set targets at all: Kafle and Huenerfauth (ACM Transactions on Accessible Computing 12(2), 2019) found that word error rate “has been found to have little correlation with human-subject performance for many applications.” A metric weighted by word importance matched deaf and hard-of-hearing viewers’ judgements far better. Dropping the word “not” and dropping the word “the” cost you the same word error rate and are not remotely the same failure.
The latency budget, stage by stage
Caption delay is dominated by the decision that someone stopped speaking, not by the model. Inference on a modern streaming recogniser is 100–400 ms. Endpointing — waiting long enough to be confident the phrase has ended — is 200–800 ms, and it is the one stage where every millisecond you cut costs you accuracy at the phrase boundary. The stage-by-stage ranges below are our own instrumented measurements across MediaSoup, Vonage and LiveKit deployments; no vendor publishes a comparable end-to-end figure, which is itself worth noticing.
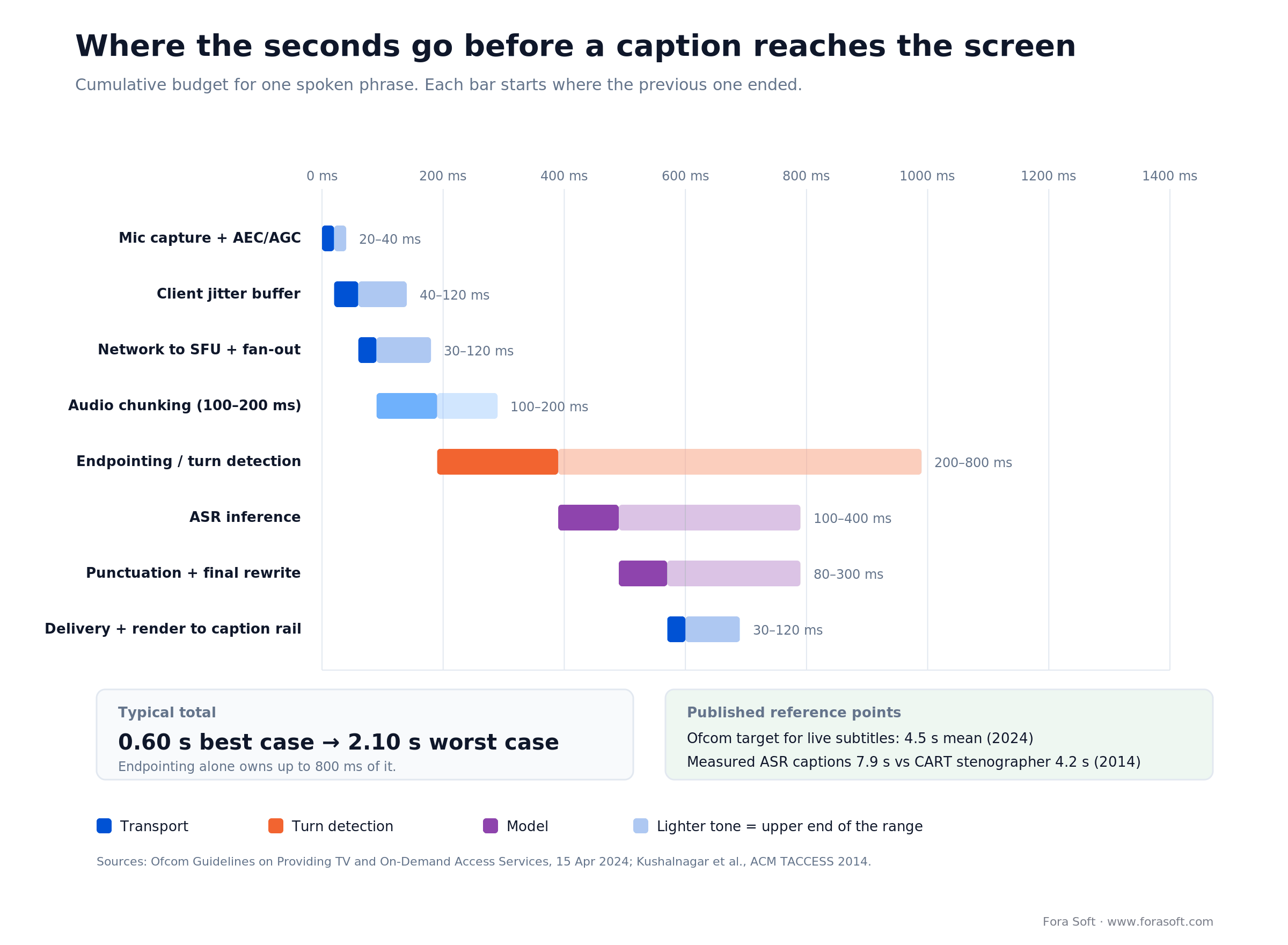
Figure 2. Where the budget goes for one spoken phrase. Turn detection is the largest single line item and the hardest to shrink safely.
Two published reference points to calibrate against. Ofcom’s 2024 access-services guidelines ask broadcasters to “aim for a mean latency of no more than 4.5 seconds” on live subtitles — and Ofcom’s own four measurement rounds recorded 5.4, 5.6, 5.1 and 5.6 seconds. Kushalnagar, Lasecki and Bigham (ACM Transactions on Accessible Computing 5(3), 2014) measured 7.9 s for automatic captions against 4.2 s for a CART stenographer, and put the usability boundary at five seconds: below it, students could keep up with a lecture but still could not reliably join the question-and-answer.
Against that background, a well-built streaming pipeline hitting 0.6–2.1 s end to end is already better than broadcast television. That is the honest framing to give a stakeholder who has just asked why the captions are not instant.
What to measure, and where
Timestamp the audio frame at capture, carry that timestamp through the pipeline, and record the delta at the moment the caption paints. Anything less specific and you will spend a sprint arguing about whose stage is slow. Three percentiles belong on the dashboard: p50 for the felt experience, p95 for the complaints, and p99 for the incident channel.
Reach for native turn detection when: latency is the binding constraint. Deepgram Flux and AssemblyAI’s Universal-3.5 Pro Realtime both fold end-of-turn detection into the model instead of bolting a voice-activity detector on top. Read the two numbers separately, though: Deepgram’s “300 ms or less” is transcription latency, while its published end-of-turn figures are 100–500 ms typical with p90 at 1 s and p95 at 1.5 s. AssemblyAI puts end-of-turn detection around 300 ms. And check the defaults — Speechmatics exposes a max_delay knob accepting 0.7–4 seconds that ships defaulted to 4.
Where to tap the audio in a WebRTC call
Tap the audio at the SFU, one recognition session per participant track. This single decision determines your speaker labels, your bill and your failure modes, and it is the thing almost no published guide gets specific about.
There are three places you can take audio from a call, and only one of them is right for a product:
| Tap point | How it works | Where it wins | Where it breaks |
|---|---|---|---|
| Browser Web Speech API | The browser handles recognition — but Chrome ships the audio to Google’s servers unless you explicitly opt into on-device processing | Zero infrastructure, zero cost, fine for a prototype | Audio leaves to a third party by default, which ends the conversation in any regulated deployment. Chrome also cuts the session at roughly 60 seconds; no diarization; no model control; nothing on the server to store |
| Mixed conference audio | One recognition session on the mixed-down room feed | One session per call, cheapest possible bill | You lose speaker identity entirely and have to reconstruct it with diarization on overlapping speech — the hardest case there is |
| Per-track at the SFU | One recognition session per participant’s audio track | Speaker labels are free because the track already carries identity; per-speaker language selection; you can drop sessions for muted participants | Cost scales with participants, not with meetings; needs connection lifecycle management |
Per-track wins for anything user-facing. The speaker-attribution problem, which is the expensive one, disappears: the SFU already knows whose track it is forwarding. That single fact removes a whole subsystem from your architecture.
The audio format detail that costs a day
Browsers publish Opus at 48 kHz. Nearly every streaming recogniser wants 16-bit linear PCM at 16 kHz, mono. Somebody has to decode and resample, and doing it badly — naive decimation instead of a proper filter — introduces aliasing that shows up as word errors you will spend days blaming on the model. Use a real resampler, and confirm your SFU is not already exporting PCM for you before you write any of it.
// Per-track tap at the SFU: one recogniser session per participant.
// Identity comes from the SFU, so no diarization is needed.
const BACKOFF_CAP_MS = 8000; // reconnect backoff ceiling
const MAX_PENDING = 64000; // bytes queued to the recogniser before we shed
const MUTE_GRACE_MS = 15000; // how long a mute must last before we close
sfu.on('trackPublished', (track) => {
if (track.kind !== 'audio') return;
const speaker = track.participantId;
// 48 kHz Opus -> 16 kHz PCM16. Use a filtered resampler, not decimation.
const pcm = track.pipe(opusDecoder()).pipe(resampleTo16k());
// The buffer must outlast the backoff ceiling, or the replay window is
// already overwritten by the time we reconnect.
const buf = new RingBuffer({ ms: BACKOFF_CAP_MS + 2000 });
let asr = null; // live session, or null
let connecting = false; // in-flight guard: one connect at a time
let stopped = false; // sticky: set by stop(), cleared only on a real restart
let retryTimer = null;
async function connect(replayFrom) {
if (asr || connecting) return; // never two sessions for one track
stopped = false;
connecting = true;
try {
const s = await openRecogniser({ encoding: 'linear16', sample_rate: 16000 });
// The track may have ended while we were awaiting. Do not leak a
// paid socket for a participant who has already left.
if (stopped) { s.close(); return; }
s.on('partial', (t) => captions.preview(speaker, t));
s.on('final', (t) => captions.commit(speaker, t));
s.on('error', () => { if (!stopped) retry(s); });
s.on('close', () => { if (!stopped) retry(s); });
// Failure mode 1: replay what was said while we were disconnected.
// Fall back to the oldest buffered frame, never to Date.now() -- if the
// socket died before acking anything, 'now' would replay nothing.
const from = replayFrom ?? buf.oldestTimestamp();
if (from) buf.since(from).forEach((fr) => s.write(fr));
asr = s;
backoff.reset();
} catch (err) {
metrics.inc('asr.connect_failed');
if (!stopped) retry(null); // retry a failed first attempt, but not
// if the track ended while we were awaiting
} finally {
connecting = false;
}
}
function retry(dead) {
if (dead && dead !== asr) return; // ignore events from a superseded socket
const from = asr?.lastAckTimestamp ?? buf.oldestTimestamp();
dead?.removeAllListeners();
dead?.close(); // a socket that errored may still be open, and billed
asr = null;
clearTimeout(retryTimer);
retryTimer = setTimeout(() => connect(from), backoff.next(BACKOFF_CAP_MS));
}
function stop() { // deliberate close: must never trigger a retry
stopped = true; // stays true until the next connect()
clearTimeout(retryTimer);
retryTimer = null;
asr?.removeAllListeners();
asr?.close();
asr = null;
}
pcm.on('data', (fr) => {
buf.push(fr); // buffer even with no live session
if (!asr) return;
// Failure mode 2: bounded backpressure. Pick a policy and name it.
if (asr.pendingBytes > MAX_PENDING) {
const droppedTs = asr.dropOldest(); // returns the discarded frame's ts
buf.markDropped(droppedTs); // that frame must not come back on replay
metrics.inc('asr.backpressure_drop');
}
asr.write(fr);
});
// Billing and cold start pull in opposite directions. Socket-metered
// vendors (AssemblyAI) charge for idle time, so closing on mute is real
// money -- but reopening pays the cold-start penalty on the first words
// back, and on AWS it re-triggers the 15-second minimum per request.
// Default: close only after a sustained mute, and never cycle on AWS.
let muteTimer = null;
track.on('muted', () => { muteTimer = setTimeout(stop, MUTE_GRACE_MS); });
// A deliberate restart starts clean: replaying the ring buffer here would
// re-send pre-mute audio the previous session already committed.
track.on('unmuted', () => {
clearTimeout(muteTimer);
if (!asr) buf.clear(); // only on a real restart; a live session still needs its tail
connect(null);
});
track.on('ended', () => { clearTimeout(muteTimer); stop(); });
connect(null); // open at join, not at first word (failure mode 3)
});
If you want the architectural context for why the SFU is the right layer to do this at, our guide to P2P versus MCU versus SFU for video conferencing covers what each topology can and cannot expose to a server-side consumer.
Speaker attribution: per-track versus diarization
Diarization is the fallback for when per-track identity is unavailable, not the default approach. Speaker diarization answers “who spoke when” by clustering voice characteristics in a single audio stream. It is genuinely hard, it costs extra, and on a WebRTC call you usually do not need it.
You do need it in exactly one common situation, and it is the one every article skips: four people in a conference room sharing one device. The SFU sees one track and hands you one participant identity. Per-track labelling collapses. This is also the acoustic worst case — far-field microphone, overlapping speech — which is where NOTSOFAR-1 measured 46.8% and 54.9% word error rate. So the moment you need diarization most, your transcript quality is at its worst.
What the vendors actually offer
AssemblyAI labels speakers live during the stream and then runs one re-clustering revision within about half a second of the stream ending, for up to 10 speakers, at +$0.12/hr on top of the streaming rate. Deepgram sells diarization as a +$0.0020/min streaming add-on. Soniox and Gladia bundle it into the base hourly price. That revision pass matters: live labels are provisional, and a UI that renders them as final will reshuffle attributions in front of the user.
Reach for diarization when: you cannot get one track per speaker — shared conference-room hardware, telephony bridges, recorded files, or a mixed feed you do not control. Everywhere else, take the identity the SFU is already giving you for free.
Whichever route you take, ship a correction interface. Users will fix speaker labels during playback if you let them, and those corrections are the cleanest fine-tuning data you will ever get — provided you have consent to use them, which is a separate question we come to below.
Building captions into a conference-room product?
Shared-device rooms are where transcription quality goes to die. We have shipped this on MediaSoup, LiveKit and Vonage — we can tell you in 30 minutes which parts are worth fighting.
Rendering captions people can actually read
Render captions as two rolling lines of about 32 characters, bottom-centre, white on a 70%-opaque black band, with partial results in a separate preview zone rather than the committed line. That sentence is most of the specification, and getting it wrong is how teams lose users who would otherwise keep captions switched on.
A recogniser that is accurate and fast still produces an unusable feature if the text jumps, rewrites itself, or scrolls faster than anyone reads. The full set of rules we hold our own builds to:
| Property | Rule | Why |
|---|---|---|
| Partial results | Render in a separate preview zone, never in the committed caption line | Partials change. Text that rewrites itself under the eye is read as a bug, not a feature |
| Line window | Two lines, rolling; commit the top line only when the bottom fills | Three or more lines cover the video; one line scrolls too fast to re-read |
| Line length | Cap at about 32 characters, break on phrase boundaries | Long lines force horizontal eye movement away from the speaker’s face |
| Placement | Bottom centre by default, draggable, never over an active video tile | 47 CFR § 14.21(b)(4) will require position control from January 2027 |
| Contrast | White on a solid or 70%-opaque black band, not on the video | WCAG contrast cannot be guaranteed against arbitrary video frames |
| Synchronization | Live captions shown within 100 ms of becoming available to the player; recorded captions within 100 ms of their timestamp | EN 301 549 clause 7.1.2. Clause 6.5.4 separately caps audio/video skew at 100 ms and 6.2.4 requires real-time text to transmit within 500 ms |
The user controls you now have to ship
From 12 January 2027, 47 CFR § 14.21(b)(4) requires interoperable video conferencing services to give users control over caption size, font, on-screen location, and the colour and opacity of both the captions and their background, and to support connecting a third-party sign-language interpreter. If your caption rail is currently a fixed-style overlay, that is a roadmap item, not a nice-to-have.
Reach for a dedicated caption UX pass when: you are about to launch. Budget a sprint for it. Every team we have worked with underestimated this and every one of them shipped a second version after user testing.
Streaming ASR vendors compared
Streaming ASR list prices run from $0.12 per hour (Soniox) to $1.44 per hour (AWS Transcribe at its tier-1 headline rate), and only five of the eleven models below publish any latency figure at all — and only one of those puts a percentile behind it. Prices are list prices from each vendor’s own pricing page, read on 26 July 2026. They move, and several are explicitly promotional, so re-check before you model anything. Latency figures are what each vendor publishes about itself; treat them as claims, not measurements, and note how many vendors publish nothing at all.
| Vendor / model | Streaming price | Published latency | Languages | Diarization | BAA / self-host |
|---|---|---|---|---|---|
| Deepgram Nova-3 | $0.0048/min mono, $0.0058 multi — promotional; list is $0.0077/$0.0092 | “300 ms or less” transcription latency in docs | 45–54 depending on which Deepgram page you read | +$0.0020/min | BAA for Enterprise; self-host via Docker, Kubernetes, SageMaker — but the licence server must stay reachable |
| Deepgram Flux | $0.0065/min EN — also promotional, list $0.0077 | End-of-turn 100–500 ms typical, p90 1 s, p95 1.5 s | 10 multilingual | +$0.0020/min | Same as Nova-3 |
| AssemblyAI Universal-3.5 Pro Realtime | $0.45/hr | “around 300 ms” end-of-turn | 18, with mid-sentence code-switching | +$0.12/hr, up to 10 speakers | Self-serve BAA; EU endpoint |
| AssemblyAI Universal-Streaming | $0.15/hr | Not restated for this generation | English only | +$0.12/hr | Same |
| OpenAI gpt-realtime-whisper | $0.017/min | Not published — docs say benchmark it yourself | Not stated for the streaming model | Not documented | No self-host |
| Google Cloud STT v2 (Chirp 3) | $0.016/min to 500k min, down to $0.004/min | Not published | Extensive | Supported | No self-host; billed per channel |
| Azure AI Speech | $1.00/hr standard, $1.20/hr custom | Not published | Extensive | +$0.30/hr add-on | Container deployment available |
| AWS Transcribe | $0.024/min tier 1, $0.0102/min tier 3 | Not published | Extensive | Supported | No self-host; 15-second minimum per request |
| Speechmatics | $0.45/hr Standard, $0.80/hr Enhanced | “<1 s”, no percentile; but max_delay accepts 0.7–4 s and defaults to 4 | 56+ | Supported | Private cloud is Enterprise-only |
| Soniox | $0.12/hr | Not published | 60+ | Included in the hourly rate | Not published |
| Gladia | $0.75/hr, $0.25/hr on commit | “sub-300 ms”, no percentile | 100+ | Included | Advertises HIPAA, SOC 2 Type 2 and ISO 27001; no self-host published |
Three things that table hides and you should know before shortlisting.
1. Vendor benchmarks are marketing. AssemblyAI published a pooled-error comparison in June 2026 putting its own model at 6.99% and Deepgram Flux at 15.58%. Deepgram’s comparison page claims a 30% lower error rate and 40× faster inference with no dataset or methodology named, and states that AssemblyAI is cloud-only with no HIPAA — both of which AssemblyAI’s own documentation contradicts. Neither page is evidence. Run your own bake-off on your own audio.
2. Billing units differ more than prices do. AssemblyAI meters streaming on WebSocket session duration, so an idle connection costs the same as a talking one. AWS bills a 15-second minimum per request — which quietly penalises aggressive session cycling. Google bills each audio channel separately, so a stereo or mixed feed costs double what the headline rate suggests, while AWS includes two channels in its rate. Two vendors at the same headline number can differ by 40% on a real workload.
3. The open-weights option is genuinely competitive — if you pick the right checkpoint. NVIDIA’s parakeet-tdt-0.6b-v3 (25 European languages, CC-BY-4.0, released 14 August 2025) publishes 6.34% average word error rate on the Open ASR Leaderboard on its own model card, with throughput more than an order of magnitude above Whisper’s. That throughput number is easy to misread, though: the leaderboard measures offline batch inference at batch size 64 on an A100, and Parakeet is a full-attention model that swallows up to 24 minutes of audio in one pass. Excellent batch engine, wrong shape for a live caption rail.
For self-hosted streaming, the checkpoint to look at is NVIDIA’s cache-aware nemotron-speech-streaming-en-0.6b. Its model card reports 6.93% average word error rate at a 1.12-second chunk, rising to 7.07% at 0.56 s and 7.67% at 0.16 s — the accuracy-for-latency trade priced out in one table. It publishes no throughput figure, and it is English-only where its offline sibling covers 25 languages. Slightly worse on paper, and built for the job you actually have.
Reach for a self-hosted model when: audio cannot leave your infrastructure, or your volume is high enough that GPU amortisation beats $0.45/hr. Take a cache-aware streaming checkpoint for the live rail and the offline Parakeet or Canary family for the archive. Be honest about the on-call cost: you are taking on a GPU fleet, not adding a dependency.
What a call actually costs
A 60-minute call with six people costs $2.70 at AssemblyAI’s $0.45 per hour — because per-track transcription bills participants, not meetings. That is the single most common budgeting mistake we see, and it is off by the average number of people in a call, usually a factor of four to six.
Six people on a 60-minute call is six billable audio hours, so at AssemblyAI’s $0.45 per hour one call costs $2.70 and 5,000 calls a month cost $13,500. The same workload on Soniox at $0.12 per hour is $0.72 per call and $3,600 a month; on OpenAI’s $0.017 per minute it is $6.12 per call and $30,600 a month. The arithmetic, spelled out:
6 participants x 1.0 hour = 6.0 billable audio hours per call
6.0 h x $0.45/h (AssemblyAI U-3.5) = $2.70 per call
5,000 calls/month x $2.70 = $13,500/month
Same workload on Soniox at $0.12/h = $0.72 per call = $3,600/month
Same workload on OpenAI at $0.017/min = $6.12 per call = $30,600/month
AWS Transcribe is tiered, so do that one the long way:
30,000 h = 1,800,000 min/month
250,000 min x $0.0240 = $6,000
750,000 min x $0.0150 = $11,250
800,000 min x $0.0102 = $8,160
total = $25,410/month (blended $0.0141/min)

Figure 3. Same 30,000 billable hours against ten price points from nine vendors. AWS and Google are charged through their volume tiers; the rest publish none on these meters. Cheapest to dearest is 8.5×.
An 8.5× spread on an identical workload is not a rounding difference, and it is why “we will pick the vendor later” is a bad plan. The ranking also moves with volume: AWS looks like the dearest option at its headline rate and lands in the upper third once its tiers apply, and Google sees its marginal rate fall from $0.016 to $0.008 per minute across this workload, a blended $0.0108, while OpenAI and Azure publish no volume tiers on these meters at all. Three adjustments that move the real number:
- Mute-driven session lifecycle. Most participants are silent most of the time, and the saving is largest exactly where teams assume it is smallest. AssemblyAI is explicit that you are “charged for the entire session — including any time the connection is idle with no audio flowing,” so on socket-metered vendors you have to close the session, not pause it. One caution the other way: AWS bills a 15-second minimum per request, so cycling open and closed on every mute toggle can cost more there than it saves.
- Add-ons stack. Diarization is +$0.12/hr on AssemblyAI, +$0.0020/min on Deepgram and +$0.30/hr on Azure. On the 30,000-hour workload above, diarization alone is $3,600/month — the entire Soniox bill. Keyterm prompting (+$0.0013/min on Deepgram, +$0.05/hr on AssemblyAI), PII redaction (+$0.0020/min on Deepgram) and continuous language identification (+$0.30/hr on Azure) each add another layer.
- Do not pay streaming rates twice. The live rail and the stored transcript are different products with different quality bars, so run the archive through a batch endpoint rather than holding a second streaming session open. Size the saving honestly, though: batch is roughly half the streaming price on AssemblyAI ($0.21 against $0.45/hr), and on AWS and Deepgram batch and streaming are billed at effectively the same rate.
What we do not publish here are project cost estimates. Every number above is a vendor list price you can verify yourself. For the delivery side, our video conferencing app cost guide walks through the full build breakdown, and we would rather quote your scope than a range.
Want the per-call number for your actual traffic?
Send participant counts, average call length and monthly volume. We will model it across the vendor shortlist and tell you which billing unit is about to bite you.
Buy, build, or self-host
Buy a managed API unless call audio legally cannot leave your infrastructure, or you are past roughly 150 concurrent streams at peak. Those two conditions decide most of it. Ask the four questions below in order and stop at the first one that answers yes; most teams arrive here comparing per-minute prices, which is the last thing that should matter.
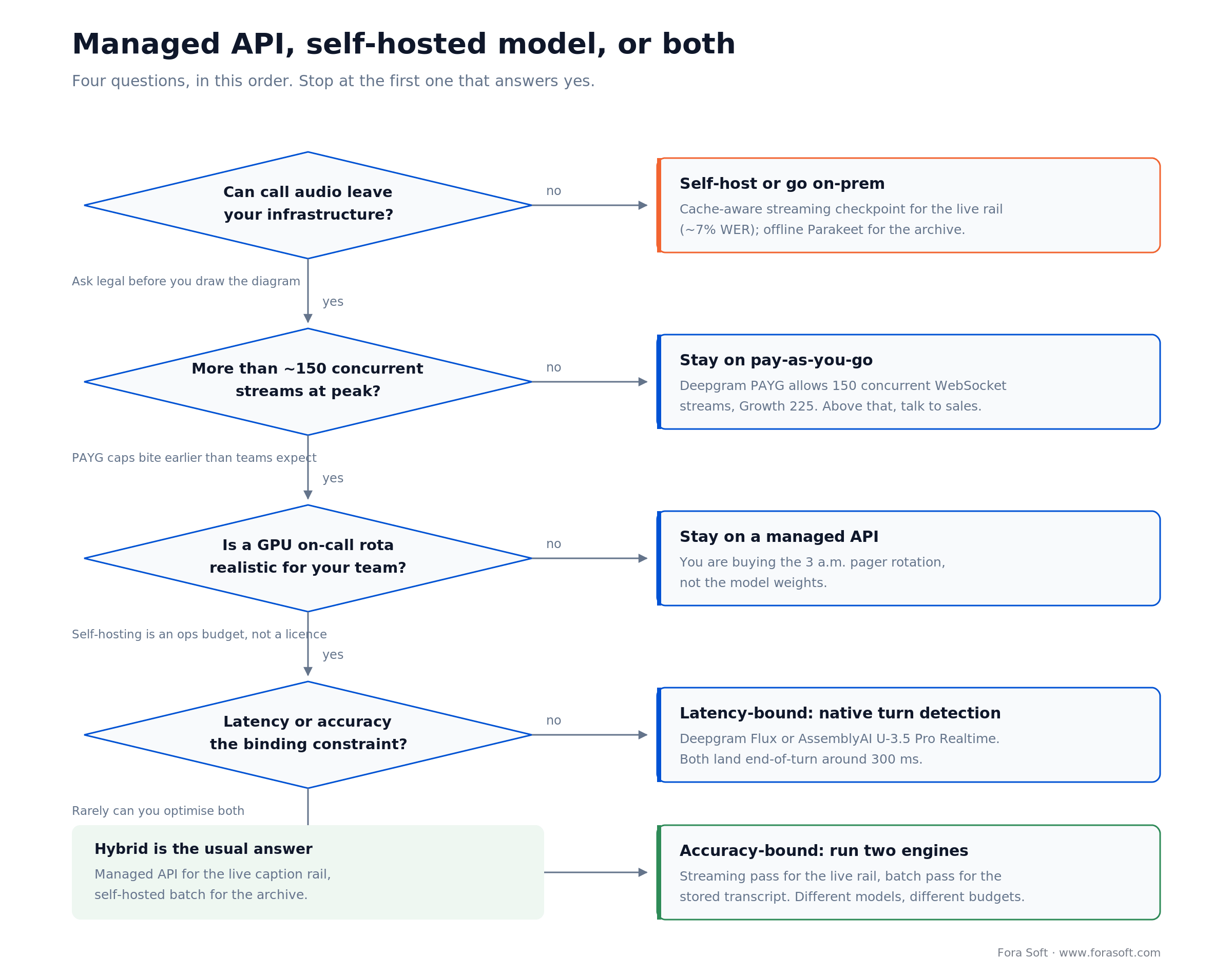
Figure 4. Four questions in order. Data residency and operations capacity decide this long before per-minute price does.
Question 1: can call audio leave your infrastructure
Ask legal before you draw the architecture. If the answer is no — and in healthcare, defence and several public-sector procurements it is — the managed-API branch closes immediately and you are sizing GPUs. Open weights make that survivable in a way it was not two years ago: a cache-aware streaming checkpoint at roughly 7% word error rate for the live rail, an offline Parakeet or Canary pass for the archive, both under commercially usable licences. Check the language list before you commit — the current NVIDIA streaming checkpoint is English-only while the offline one covers 25 European languages.
Question 2: how many concurrent streams at peak
Deepgram’s pay-as-you-go plan allows 150 concurrent WebSocket streams; its Growth plan allows 225. On per-track architecture, 150 streams is 25 six-person calls. Teams discover this cap in production more often than they should.
Question 3: is a GPU on-call rota realistic
Self-hosting is an operations budget, not a licence decision. You are buying model updates, GPU capacity planning, and the three-in-the-morning pager rotation. If your team is four people, the honest answer is usually no, and paying $0.45/hr to make that someone else’s problem is good value.
Question 4: latency or accuracy
You rarely optimise both. If latency binds, take a model with native turn detection. If accuracy binds, run two engines: a streaming pass for the live rail and a batch pass for the stored transcript. The batch pass is cheaper, more accurate and does not have to make the endpointing compromise.
Reach for the hybrid pattern when: you want the live rail and the archive to have different quality bars — which is nearly always. Managed streaming API in the call path, self-hosted or batch for the transcript. Be clear about what that buys: it will not cut the streaming bill and it does add a second one. What you get is a materially better stored transcript without a GPU on the critical path.
Consent, recording law and the EU AI Act
Live transcription is treated as recording under US state wiretap law, and nine states require consent or notice from every party rather than just one. The federal baseline, 18 U.S.C. § 2511(2)(d), is one-party consent. The nine to design for are California, Florida, Illinois, Maryland, Massachusetts, Montana, New Hampshire, Pennsylvania and Washington — and Oregon belongs on the list too for anything that is not a phone call. Other states appear on longer lists for contested reasons; treat these ten as the design constraint and take counsel on the rest.
The details change what you build, not just what your lawyer writes:
- Washington accepts an announcement. RCW 9.73.030 allows “a reasonably effective recorded announcement” — an in-call disclosure can satisfy it, which is why every conferencing product plays one.
- Montana requires knowledge, not consent. MCA § 45-8-213 asks that participants know, which is a lower bar than an affirmative opt-in.
- Massachusetts bans only secret recording. Curtatone v. Barstool Sports (2021) confirmed that open recording is outside the statute.
- Oregon names video calls in the statute. ORS 165.535(1) defines a “conversation” to include “a communication occurring through a video conferencing program,” and ORS 165.540(1)(c) bars obtaining one unless all participants are “specifically informed.” Telephone calls sit on a separate one-party track. The Ninth Circuit, sitting en banc, upheld the provision in January 2025 (Project Veritas v. Schmidt). Most published all-party lists still file Oregon as one-party, which is wrong for the product this article is about.
Does a transcript create a biometric identifier
Illinois BIPA lists “voiceprint” as a biometric identifier, with liquidated damages of $1,000 for negligent and $5,000 for reckless violations. The usual reassurance — that transcription measures words while a voiceprint measures the speaker — is weaker than it looks. In Carpenter v. McDonald’s (N.D. Ill. 2022) the court adopted exactly that distinction from an Illinois Attorney General opinion and then refused to dismiss the § 15(b) claim: it “cannot conclude as a matter of law that Defendant does not collect voiceprints via its AI voice assistant technology,” reasoning that a system which interprets and understands speech “detects and analyzes human speech in a way that a mere recording device does not.”
That reasoning maps straight onto automatic speech recognition, and more directly still onto speaker diarization, which clusters voice characteristics by definition. Our working assumption for Illinois traffic is that this is a live risk, not a settled safe harbour: get written notice and release in place before you turn diarization on, and treat any fine-tuning on voice embeddings as squarely inside the statute.
Separately, the Illinois Eavesdropping Act at 720 ILCS 5/14-2(a)(3) expressly covers the act of transcribing — but liability needs both a private conversation and a surreptitious act. An openly disclosed transcript is not surreptitious. Disclosure is the entire defence, which is another argument for making the in-call indicator loud.
The EU AI Act, precisely
Article 50(2) of Regulation (EU) 2024/1689 requires providers of AI systems generating synthetic audio, image, video or text to mark outputs in a machine-readable format, detectable as artificially generated. It applies from 2 August 2026. Three things about it are widely misreported.
First, the Digital Omnibus did not delay it. Regulation (EU) 2026/1744 of 8 July 2026, published in the Official Journal on 24 July 2026, amends Article 50 at one point only — it replaces paragraph 7, which concerns codes of practice. Paragraphs 50(1) to 50(6) are untouched. What the Omnibus did move were the high-risk obligations, to December 2027 and August 2028.
Second, there is a grandfathering clause almost nobody mentions. The Omnibus added a new Article 111(4): systems generating synthetic content that were placed on the market before 2 August 2026 have until 2 December 2026 to comply with Article 50(2). Ship after 2 August and you comply from day one. The disclosure duties in 50(1), (3), (4) and (5) get no transition at all.
Third, plain transcription may not be caught by 50(2) in the first place. The article carries an explicit carve-out: the marking obligation “shall not apply to the extent the AI systems perform an assistive function for standard editing or do not substantially alter the input data provided by the deployer or the semantics thereof.” A verbatim transcript does not alter the semantics of what was said. A generated summary, a translated dub or a cloned voice plainly does. We read this as: transcripts arguably out, everything downstream of them in. That is our reading, not settled law. The Commission published its Code of Practice on Transparency of AI-Generated Content on 10 June 2026 and adopted its Article 50 guidelines on 20 July 2026, so the guidance here is moving faster than the commentary — take a lawyer’s view on your specific output types before relying on the carve-out.
Reach for a consent ledger when: you have any US traffic. Per-participant, timestamped, with the disclosure text version recorded. It is a week of work and it is the artefact that ends the argument when someone asks who agreed to what.
The FCC deadline nobody is writing about
From 12 January 2027, US law requires interoperable video conferencing services to offer captions. Not accessibility guidance, not a WCAG target — a Federal Communications Commission rule with a compliance date. We surveyed the ten highest-ranking articles on real-time transcription while researching this piece and not one of them mentioned it, including a specialist accessibility vendor whose page is about US video accessibility law.
The rule is 47 CFR § 14.21(b)(2)(iv), added by FCC 24-95 (adopted September 2024, effective January 2025) under the CVAA. It says that from 12 January 2027 a covered service must “provide at least one mode with captions that accurately and synchronously display the spoken communications in a video conference, and enable users to connect with third-party captioning services.”
| What the rule says | What it means for the build |
|---|---|
| “Accurately” is defined in the rule itself: matches the spoken words in the order spoken, verbatim, without summarizing or paraphrasing, sufficiently to enable a user to understand what is being said | A summary-style caption track does not satisfy it. The trailing comprehension clause leaves some room on disfluency removal, but treat “AI-cleaned” captions as a decision with a legal edge, not a purely editorial one |
| “Synchronously”, with no millisecond figure | No hard latency target, but you will be judged against what competitors ship. Budget for under 2 seconds |
| § 14.21(b)(4)(ii)(A): user controls for caption size, font, on-screen location, and the colour and opacity of both the captions and the caption background | Five settings across two layers, plus a persistence layer. This is the part teams miss |
| § 14.21(b)(4): support third-party sign-language interpretation | A way to pin an interpreter’s video tile, and an interoperable route in |
| “Interoperable video conferencing service” is defined at § 14.10(m) as a service providing real-time video communications to enable users to share information of the user’s choosing | Broad. If your product does video calls between users, assume you are in scope |
| The duties are qualified by whether compliance is “achievable” (§ 14.20(b)(1), on the definition at § 14.10(b)) | A real defence for a very small company, and a weak one for anyone with a funding round |
The other dates on the same roadmap
The FCC rule is not alone, and the dates cluster. The European Accessibility Act has applied since 28 June 2025 and covers electronic communications services, which includes number-independent interpersonal communications — standalone video conferencing is in scope. Its Annex I requirement for such services is real-time text alongside voice and “total conversation” where video is offered; the words caption and subtitle do not appear there, which surprises people. Micro-enterprises are exempt — Art. 3(23) defines those as fewer than 10 staff and either turnover or a balance-sheet total not exceeding EUR 2 million.
EN 301 549 is still at V3.2.1 (March 2021) despite widespread references to a V4 — the V4.1 drafts are not published. Its clause 6.2.1.1 mandates two-way real-time text, not captions. Clause 7.1.2 is a synchronization requirement rather than a delivery deadline: captions must appear within 100 ms of becoming available to the player for live content, and within 100 ms of their timestamp for recorded content.
And in the US, the Department of Justice’s ADA Title II web rule moved. An interim final rule published 20 April 2026 pushed the WCAG 2.1 AA compliance dates to 26 April 2027 for public entities serving 50,000 people or more and 26 April 2028 for everyone else. If you sell to universities or municipalities, those are your dates.
What we shipped: VOLO and TransLinguist
The situation. VOLO.live needed live subtitles and voiceover for conference audiences who would not install anything. The constraint was brutal in its simplicity: an attendee scans a QR code, picks a language, and reads captions on their own phone. No app, no login, no support desk. The first real test was Black Hat Briefings 2025 with more than 22,000 participants, followed by HIMSS in 2025 and 2026 and GDC in 2026.
The plan. We built it browser-first on Next.js and NestJS with Vonage for media, Socket.io for the caption channel, and Speechmatics on the recognition side with Google Cloud in support. Speakers switch presentation language mid-session and the subtitle track follows. Overflow streaming carries the same translated feed to remote attendees. The admin panel handles events, QR generation and ad placement, because the operator running the room is not an engineer.
The outcome. It has run at three conference brands across two years without a caption rail failure at scale. On TransLinguist — the interpreter platform we also build — the same discipline produced closed captioning in 22 languages and session transcription in every one of its 75+ languages, running Google Cloud Speech-to-Text, Deepgram and Speechmatics side by side on a MediaSoup stack. That platform won the NHS (NOE CPC) National Framework for language services across the UK and serves a marketplace of over 30,000 certified interpreters.
The transferable lesson is the multi-vendor part. Both products run more than one recogniser, because no single vendor is best across every language and every room, and because the one you standardise on will have an outage during a keynote. If you want the same assessment for your stack, book a 30-minute review and bring your language list.
Five failure modes that take captions down mid-call
1. WebSocket reconnect without an audio buffer. The recogniser connection drops, your client reconnects in 800 ms, and the words spoken in that window are gone forever. Buffer audio locally during reconnect and replay it on the new session. Every production stack needs this and almost no tutorial mentions it.
2. Backpressure when the recogniser falls behind. Under load, inference queues. If you keep pushing audio you build an unbounded backlog and captions drift further behind speech until they are useless. Decide the policy in advance: drop the oldest audio and keep captions current, or drop nothing and let them lag. Both are defensible. Having no policy is not.
3. Cold start on the first utterance. The first words of a call are frequently the worst-transcribed, because the session is still warming and the automatic gain control has not settled. Open the recogniser session when the participant joins, not when they first speak.
4. Single-vendor dependency. Every ASR provider has outages. Route through an abstraction with a second provider configured, even if the fallback is 100 ms slower and slightly worse. We run multi-vendor on both VOLO and TransLinguist and it has earned its keep.
5. Unbounded retention. “We keep transcripts forever” is not a policy, it is a GDPR exposure and a discovery target. Default to 90 days, let customers extend it deliberately, log every deletion, and scrub personally identifiable information before persistence rather than after.
What to measure from day one
Quality. Word error rate on a held-out set built from your own product audio, segmented by device type and by speaker accent — a single aggregate number will hide the disparities in the research above. Track entity error rate separately: names, numbers and product terms are what users notice. Target under 15% aggregate on headset audio, and know your far-field number rather than pretending it is the same.
Experience. Caption latency at p50, p95 and p99, measured from audio capture to paint. Caption enablement rate and, more revealing, the caption abandonment rate — the share of users who switch captions on and then off within the same call. That second metric is the honest verdict on your rendering layer.
Reliability. Recogniser session success rate, reconnect count per call, and time to first caption after join. Alert on time-to-first-caption above three seconds; it is the earliest signal that something upstream has broken, and it fires before users complain.
Pick your stack in five questions
Q1. Where does the audio live? If call audio cannot leave your infrastructure, you are self-hosting and the rest of this list gets easier. If it can, you have nine vendors to choose from and the choice is mostly commercial.
Q2. Can you get one audio track per speaker? If yes, take the SFU’s identity and skip diarization entirely. If no — shared conference-room hardware, telephony bridges — budget for diarization and for the far-field accuracy hit that comes with it.
Q3. Which binds first, latency or accuracy? Latency-bound means native turn detection. Accuracy-bound means two passes, streaming and batch. Trying to have both from one engine is how projects end up disappointed with every vendor they try.
Q4. What is your peak concurrency? Multiply peak concurrent calls by average participants. If that exceeds 150 you are past most pay-as-you-go caps and into a sales conversation, which takes weeks you should schedule now.
Q5. What is your compliance perimeter? Any US traffic means a consent ledger. Any EU traffic means the Article 50 analysis. Any public-sector customer means the ADA Title II dates. Answer this before you pick a vendor, because it eliminates several of them.
If the answers to those five leave you with more questions than a shortlist, that is normal — it is the conversation we have with clients most weeks. We do these as a 30-minute call and you get the shortlist and the per-call cost, not a proposal.
Have a caption deadline and an existing codebase?
January 2027 is closer than a roadmap makes it look. We will map your current audio path to what the rule requires and tell you what actually has to change.
When not to build this
Skip it when your calls are short one-to-ones, when every call comes from a shared conference-room device, or when the transcript carries legal weight. We have advised clients out of all three. The reasoning in each case:
Your calls are one-to-one and short. Two people on a five-minute support call do not need a caption rail. They need good audio. Spend the sprint on echo cancellation and network resilience and you will move satisfaction further than captions will.
Your users are all in shared conference rooms. If every call comes from a single far-field device with four people around it, you are buying into the 46.8% error case with diarization on top. The captions will be bad enough to damage trust in the rest of the product. Fix the audio hardware first; the feature will be worth shipping afterwards.
You need a legal record. Court proceedings, regulated financial conversations and clinical documentation still use human transcriptionists, and the certification numbers explain why — a Certified Realtime Captioner passes at 96% at 180 words per minute, on the hardest audio, with liability attached. Automatic transcription is a draft. If the output has legal weight, it needs a human in the loop, and your product should say so on the screen.
Reach for human captioners when: the transcript carries legal or clinical consequence, or when a specific user has requested accommodation that automatic captions demonstrably fail to provide. The FCC rule itself requires you to let users connect a third-party captioning service — that route exists for a reason.
FAQ
What is real-time transcription?
Real-time transcription is speech-to-text that produces words while someone is still speaking, typically 0.6 to 2.1 seconds behind the speaker on a video call, instead of processing a finished recording. In a video call it runs as a streaming session that returns provisional partial results and then frozen final results for each phrase.
How accurate is real-time transcription on a video call?
Expect 12% word error rate on headset microphones and 30–47% on far-field conference-room audio. Microsoft’s NOTSOFAR-1 evaluation (Interspeech 2024) measured 12.0%, 32.4% and 46.8% on close-talk, multi-channel far-field and single-channel far-field recordings of the same meetings, using its tcpWER metric. Vendor benchmarks of 4–6% are measured on read speech and do not transfer.
Is 99% accuracy an FCC requirement for captions?
No. The 99% figure comes from an arithmetic example inside 47 CFR § 79.1(k)(2)(iv), a voluntary best-practices clause in a rule that applies only to televised programming. In FCC 14-12 the Commission stated its caption quality standards are qualitative rather than quantitative and rejected the numeric proposals it received.
When do video conferencing services have to provide captions in the US?
12 January 2027. 47 CFR § 14.21(b)(2)(iv) requires interoperable video conferencing services to provide at least one mode with captions that accurately and synchronously display spoken communications, and to let users connect third-party captioning services. Section 14.21(b)(4) adds user controls for caption size, font, position, colour and opacity from the same date.
Does the EU AI Act require watermarking of AI captions?
Article 50(2) of Regulation (EU) 2024/1689 requires machine-readable marking of synthetic audio, image, video and text from 2 August 2026, but it exempts systems that perform assistive editing or do not substantially alter the input data or its semantics. A verbatim transcript arguably falls in that exemption; a generated summary, translated dub or cloned voice does not. Systems on the market before 2 August 2026 have until 2 December 2026 under the new Article 111(4).
How much does real-time transcription cost per call?
On per-track architecture, a 60-minute call with six participants is six billable audio hours. At AssemblyAI’s $0.45 per hour that is $2.70 per call; at Soniox’s $0.12 per hour it is $0.72; at AWS Transcribe’s tier-1 rate of $0.024 per minute it is $8.64. Diarization and redaction add-ons stack on top.
Do I need speaker diarization with a per-track SFU setup?
Usually not. If you open one recognition session per participant track, the SFU already tells you who is speaking and diarization adds cost without adding information. You need it when several people share one device, on telephony bridges, and on mixed feeds you do not control.
Which is better for streaming, Deepgram or AssemblyAI?
Read their latency claims carefully: AssemblyAI puts end-of-turn detection around 300 ms, while Deepgram’s “300 ms or less” is transcription latency and its published end-of-turn figures are 100–500 ms typical, p90 1 s, p95 1.5 s. Both sign HIPAA business associate agreements. Deepgram is cheaper per minute and offers self-hosting, though its licence server must stay reachable; AssemblyAI bills per hour of WebSocket session and ships live diarization with a post-stream revision pass. Ignore both companies’ comparison pages — they contradict each other and neither publishes a methodology. Run a bake-off on your own audio.
Is live transcription legally a recording?
In practice yes, for consent purposes. Nine US states require all parties to consent to recording a conversation, and the Illinois Eavesdropping Act at 720 ILCS 5/14-2(a)(3) expressly covers transcribing. Illinois liability additionally requires the act to be surreptitious, so an openly disclosed transcript with a visible in-call indicator is on much safer ground.
Where should I tap audio in a WebRTC call for transcription?
At the SFU, with one recognition session per participant audio track. The SFU already knows whose track it is forwarding, so speaker labels come for free and you can skip diarization entirely. Tapping the mixed conference feed is cheaper per call but throws away speaker identity; the browser Web Speech API sends audio to Google by default and Chrome cuts the session at roughly 60 seconds.
How much caption latency is acceptable?
Under two seconds end to end is a good target for a video call, and a well-built streaming pipeline lands at 0.6 to 2.1 seconds. For context, Ofcom asks UK broadcasters to aim for a 4.5-second mean on live subtitles and measured 5.1 to 5.6 seconds in its own four sampling rounds, so a competent in-call pipeline is already faster than broadcast television.
Can I run real-time transcription without sending audio to a cloud vendor?
Yes, but pick a streaming checkpoint. NVIDIA’s cache-aware nemotron-speech-streaming-en-0.6b reports 6.93% average word error rate at a 1.12-second chunk and is built for live audio, though it is English-only. Its offline sibling parakeet-tdt-0.6b-v3 reports 6.34% across 25 European languages with far higher batch throughput, but it is a full-attention model meant for recorded files rather than a live caption rail. Either way the cost moves from a per-minute bill to GPU capacity and an on-call rota.
What to read next
Translation
7 best video call translation tools compared
Once captions work, translation is the next request. Honest comparison, 2026 pricing.
Streaming
Speech-to-text in live streaming
The one-way broadcast version of this problem: API pricing, latency, integration.
Product
AI video conferencing features in 2026
The wider feature set captions usually arrive with, and what each one costs.
Architecture
P2P vs MCU vs SFU for video conferencing
Why the SFU is the right layer to tap audio from, explained properly.
Case study
TransLinguist: captions in 22 languages
The interpreter platform we build, and the stack behind its caption rail.
Ready to put captions on your calls before January 2027?
The short version of everything above: benchmark accuracy is not your accuracy, endpointing not inference owns your latency, per-track billing multiplies your bill by the size of the room, and two regulatory dates — 2 August 2026 in Europe and 12 January 2027 in the US — have turned this from a differentiator into a requirement.
None of it is hard to build. All of it is easy to build wrong, and the wrong version is the one where users switch captions on once and never again. We have shipped this on Vonage, MediaSoup and LiveKit stacks, for conference halls with 22,000 people and for NHS interpreting sessions with two, and the difference between the good and the bad versions was never the model.
If you want a second opinion on an architecture you already have, we will give you one in half an hour. If you want the work done, we will scope it. Either way, bring your participant counts and your language list — those two numbers decide most of it. Our AI integration and custom software development teams do this together, the speech-to-text development practice is where this particular work lives, and if you need people embedded in your team, that is a dedicated development team conversation instead. Deeper background lives in our AI for video engineering and audio for video courses, our real-time speech translation guide covers the architecture once translation joins the pipeline, and if the requirement is live interpretation rather than captions, that is our language interpretation practice.
Let us look at your audio path
Thirty minutes, your stack, our shortlist. You leave with the vendor comparison, the per-call cost and the compliance dates that apply to you.








