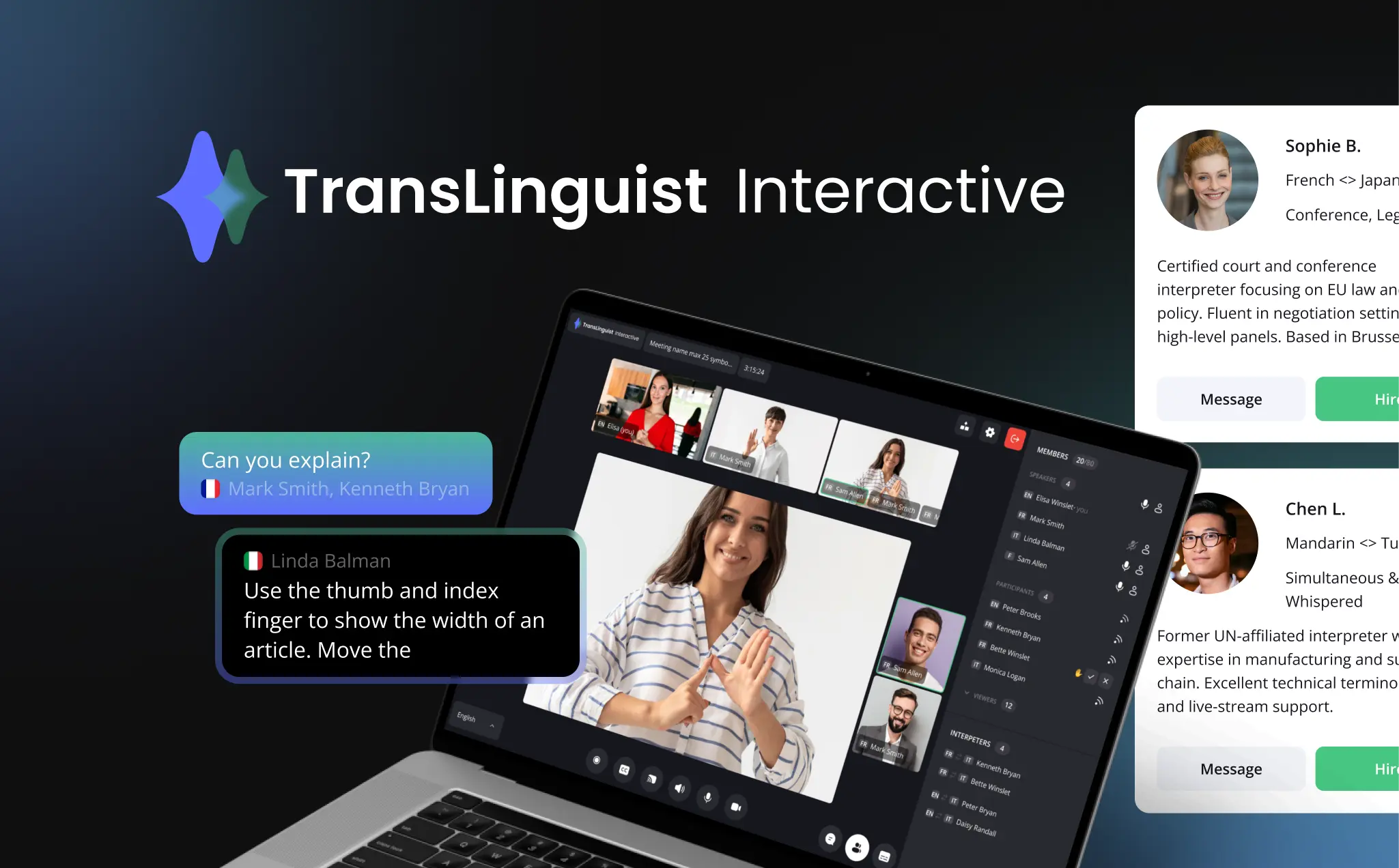
Neural voices. Branded speech. Scalable APIs. Built by a team that's shipped real-time audio for 20+ years, including NHS-grade systems supporting 62 languages.
Off-the-shelf TTS gives you a generic voice that sounds like every other app. We build speech engines tuned to your brand, your domain, and your users with the quality and reliability your product actually needs.
We develop custom TTS systems powered by modern neural AI models — fine-tuned to match your brand voice, handle your domain's vocabulary, and scale with your product.
From standalone speech engines to full streaming APIs, we handle the full build: architecture, model training, integration, and ongoing support.
Our TTS work sits inside a broader specialization in real-time audio and video. That means the same team that's built sub-second voice pipelines for live interpretation platforms is building your speech engine — not a generalist shop learning TTS on your budget.
Neural models that produce natural rhythm, emotion, and appropriate emphasis. SSML support for fine-grained control. Multiple speaking styles per voice. Ideal for assistants, accessibility tools, media, and e-learning.
Voices trained on your audio samples — from short recordings to full datasets. Clone a specific voice or build an original branded one. Control pitch, tone, speed, and style. Built for announcements, narration, product assistants, and IVR.
40+ languages, custom pronunciation dictionaries, and dialect support. Batch processing for high-volume workloads. Real-time and async generation. Web, mobile, desktop, and IoT deployment.

Most custom TTS projects fail at the same points: unclear voice requirements, models that don't generalize to real-world text, and APIs that can't handle production load.
Our process is designed to avoid all three.
We align on your use case, voice requirements, languages, latency targets, and deployment environment. We'll tell you directly if something isn't feasible.
We select or train the right neural model for your needs. If you're cloning a voice, we assess your recordings and define the training pipeline.
We train on your domain data, evaluate against held-out test sets, and iterate. You see accuracy numbers at each checkpoint — not after 3 months.
The trained model ships as a clean REST or WebSocket API, containerized for your infrastructure. We handle CI/CD setup, monitoring hooks, and fallback logic.
Go live on your schedule. We support post-launch monitoring, retraining pipelines, and incremental improvements as your audio data grows.
The result: a speech system that handles your actual content, under your actual load, sounding the way your brand should.
We choose technologies based on your requirements — not on what we're most comfortable selling.
That said, most TTS systems we build share a common architecture:
Start with an MVP and scale to enterprise-grade systems with millions of concurrent streams. Reach out for free roadmap and SRS →
Generic TTS works fine for basic read-aloud. Custom TTS is what you need when the voice is part of the product — when it needs to sound right, feel right, and hold up under production conditions.
Custom TTS software development for every stage. Secure, scalable, and built by engineers who've shipped real-world audio systems — not just demos.
![[background image] image of logistics control room (for a trucking company)](https://cdn.prod.website-files.com/64e8910adc5a63966a68acc1/68e7dfd17638aaf511162f7a_f841ed23dc31eb8a94e23195c64f4acb_develop.webp)
Have an idea and need the full build? We'll take it from requirements and architecture through development, testing, and launch.
You get a production-ready system, not a prototype you have to rebuild.

Existing TTS that sounds robotic, can't handle your domain's vocabulary, or doesn't scale to your current load?
We'll assess what's worth keeping and what needs replacing — then make it work properly.
![[digital project] image of a showcased project (for a ai robotics and automation)](https://cdn.prod.website-files.com/64e8910adc5a63966a68acc1/68e7e04abb8f1a3770a8625e_fix.webp)
Inherited a TTS project that's stalled, broken, or not performing as promised?
We step in, audit the codebase, identify what's actually wrong, and get it back on track. No solutionizing until we understand the problem.
Startup 💡
Neural TTS foundation, 1-2 natural voices, core language support, REST API integration, basic SSML
from
$10,000
from 6 weeks
Growth 🚀
Custom-trained voices, multilingual support (10+ languages), streaming API, pronunciation dictionaries, performance tuning
from
$24,000
from 3 months
Enterprise 🏢
Full custom TTS engine, voice cloning, offline/on-device deployment, enterprise security, compliance support, dedicated infrastructure
from
$40,000
from 6 months
Ready for a realistic timeline and cost breakdown tailored to your TTS & Voice Cloning needs? We offer free SRS and a code audit for existing projects.
Perfecting complex real-time video & audio software since day one – reliable custom solutions that deliver real value.
Senior developers, QA, UI/UX designers, analytics – all in-house. We think like product owners, not just coders.
Over 600 completed projects, 100% Upwork Success rate, and 400+ honest clients' reviews. Results you can trust.
Get the scoop on real-time video/audio, latency & scalability – straight talk from the top devs
Custom TTS development means building a speech synthesis system tailored to your product: your voices, your languages, your API structure, and your deployment environment, rather than integrating a third-party service with a generic voice. The result is a system you own and control, optimized for your specific use case and content domain.
Yes. We build custom voice cloning systems trained on your audio recordings. Quality depends on the dataset: high-quality clones typically need 30-60 minutes of clean audio, but lighter approximations work with less. We'll assess your recordings and set realistic expectations before starting.
Modern neural TTS, using architectures like VITS or Tortoise, produces speech that's often indistinguishable from human recording in controlled conditions. Real-world quality depends on your content domain, the model's training data, and how well we handle domain-specific vocabulary. We build pronunciation dictionaries for technical, medical, or legal terms that generic models consistently mispronounce.
Yes. We build on-device TTS engines for mobile (iOS/Android), desktop, and embedded/IoT systems where cloud latency or connectivity isn't viable. These use lightweight models optimized for the target hardware.
We deliver a REST API and/or WebSocket streaming endpoint that connects to your web, mobile, backend, or IoT platform. We also provide client SDKs and integration documentation. If you have an existing audio pipeline, we'll design the TTS layer to fit cleanly into it rather than force a redesign.
Projects typically range from ~$10,000 (MVP with one voice and basic API) to $40,000+ (enterprise engine with voice cloning, multilingual support, and on-premise deployment). The main cost drivers are: number of voices, languages supported, whether voice cloning is needed, deployment environment (cloud vs. on-device), and compliance requirements. We give you a detailed breakdown after a discovery call.
We stay available for tuning, new language and voice additions, scaling support, and bug fixes. We don't hand off and disappear. Long-term engagements are common; most our clients come back when their product grows or requirements change.











