



Key takeaways
• Live real-time translation in teleconferencing is now an end-to-end pipeline of four stages: ASR (speech-to-text), MT (machine translation), TTS (text-to-speech), and optional voice cloning. Target end-to-end latency is < 800 ms for captions and 2–3 s for translated voice.
• The 2026 stack winners are Deepgram Nova-3 + DeepL + ElevenLabs Multilingual. Deepgram delivers ~5–7% WER at ~450 ms streaming latency, DeepL leads on COMET-graded translation quality for European languages, ElevenLabs Flash hits 75 ms TTS latency. The cascaded pipeline still beats end-to-end speech-to-speech models in production.
• Realistic per-minute cost is ~$0.04–$0.06. Roughly $0.009/min ASR + $0.0024 per 100 chars MT + $0.03/min TTS = $2.50–$3.50/hour of translated audio. Add 20–30% for retries, idle stream time and language detection.
• WebRTC architecture choice changes everything. SFU + server-side translation worker is the production-grade pattern. P2P breaks at >3 participants; MCU adds transcoding lag. We covered this in detail in our P2P vs MCU vs SFU piece.
• Build vs buy break-even sits around 2,000 paid calls/month. Below that, off-the-shelf KUDO, Interprefy, Wordly or Zoom AI Companion is cheaper. Above that — or with telehealth, courtroom, broadcast or eSports verticals where data residency or domain glossaries matter — custom WebRTC + translation usually wins.
More on this topic: read our complete guide — 7 Best Video Call Translation Tools Compared (2026).
Why Fora Soft wrote this real-time translation playbook
We’ve been building video and AI products for 19 years and have shipped 450+ video and conferencing systems. Among them is Translinguist — a custom AI-driven live event interpretation platform that combines streaming ASR, real-time MT, multilingual TTS and human interpreter fallback for events where Zoom’s default translated captions don’t cut it.
This playbook is the buyer-and-builder guide we wish more product teams had on day one. We compare the 2026 ASR / MT / TTS stack honestly with WER, BLEU/COMET, latency and price. We walk the WebRTC architecture for piping translated audio back into the call. We give the cost model at scale, the compliance traps for HIPAA / GDPR / FERPA, and the build-vs-buy line. And we end with a five-question framework for picking the right path.
If your product is a webinar platform, telehealth tool, e-learning service, courtroom-recording stack or eSports broadcaster, the rest of this article is for you.
Adding real-time translation to your video product?
A 30-minute scoping call gives you a vendor-neutral architecture, a 2026-grade stack, and a budget for translated captions or full voice translation.
What live real-time translation in teleconferencing actually is
Live real-time translation is the live conversion of one speaker’s audio into another language — as captions, as a translated voice, or as both — with low enough latency that listeners can follow the conversation as it happens. It used to require a human interpreter and an isolation booth. In 2026 it’s a software pipeline you ship inside your video conferencing product.
Two delivery modes coexist. Translated captions show the listener written subtitles in their language; latency target is under 800 ms and accuracy is mostly an ASR + MT problem. Translated voice renders the speaker’s sentences as spoken audio in the listener’s language, optionally in a cloned voice; latency target is 2–3 s end-to-end and the chain adds TTS plus voice-cloning quality risks. Most production deployments ship both, and let the listener pick.

Figure 1. Real-time translation pipeline — from microphone to translated captions and dubbed voice.
The four-stage pipeline — ASR → MT → TTS → voice cloning
A real-time translation pipeline is a chain. Each stage adds latency and accuracy risk; you optimise the chain, not the components.
1. ASR (speech-to-text). Streams the speaker’s audio into partial transcripts. Modern engines (Deepgram Nova-3, AssemblyAI Universal-2, Whisper-large-v3 with streaming wrappers) deliver 100–500 ms latency on streaming endpoints. Word error rate (WER) is the headline accuracy metric — 5–7% on conversational English is the 2026 frontier.
2. MT (machine translation). Converts the transcript into the target language. Cascaded MT (DeepL, Google Cloud Translation, Azure Translator, NLLB-200) typically adds 100–200 ms per sentence. End-to-end speech-to-speech models (Meta Seamless Streaming, Google Translatotron) skip ASR + MT but only ship at scale for a subset of languages and add 1.5–2 s latency in 2026.
3. TTS (text-to-speech). Renders the translated text as audio. ElevenLabs Multilingual (Flash v2.5 hits 75 ms first-token), OpenAI Voice Engine, Microsoft Azure Neural TTS, PlayHT and Resemble AI cover the production-quality range. The trade-off is naturalness vs latency — expressive voices add 200–400 ms.
4. Voice cloning (optional). Renders TTS in the original speaker’s voice. ElevenLabs Multilingual v3, Microsoft VALL-E 2 / Azure Personal Voice and OpenAI Voice Engine all ship this. It’s the quality multiplier that makes a translated meeting feel like the speaker really learned your language. Compliance traps are real: HIPAA and GDPR both treat voice biometrics as sensitive data.
Reach for cascaded ASR → MT → TTS when: you need 100–120 language pairs, debuggability per stage, custom domain glossaries, and the freedom to swap one component without rebuilding the pipeline. End-to-end speech-to-speech is exciting research, not a 2026 production default.
The 2026 ASR engines — what to ship into production
Numbers below are 2025–2026 vendor-published or independently-benchmarked. Re-test on your own audio before you commit; conversational accents, code-switching and background noise change the rankings.
| ASR engine | WER (conv.) | Streaming latency | Languages | Price/min | Use case |
|---|---|---|---|---|---|
| Deepgram Nova-3 | 5.3–6.8% | ~450 ms | 40+ | $0.0092 | General real-time |
| OpenAI Whisper v3 | ~7.4% | batch 30s chunks | 99+ | $0.006 | Wide language support |
| AssemblyAI Universal-2 | ~14% conv. / 2% clean | ~600 ms | English-strong | $0.0025 | Cost-sensitive, alphanumeric |
| Google Cloud STT | 7–10% | ~500 ms | 125+ | $0.016 / vol $0.004 | GCP estates |
| Azure Speech | 7–9% | ~500 ms | 100+ | $0.012 | Microsoft estates, HIPAA |
| NVIDIA Riva (on-prem) | 8–10% | ~300 ms | 12 core + custom | GPU capex | Air-gapped, regulated |
For more on the ASR landscape we put together a deeper review of speech-recognition platforms that goes beyond translation use cases.
The 2026 MT engines — what translates well and fast
DeepL. Quality leader on European languages by COMET and human-judgement studies; 30+ language pairs. Sentence-by-sentence streaming, ~150–200 ms. ~€0.002 per 100 characters. The default for general business meetings in EMEA.
Google Cloud Translation v3. 135 languages. Custom AutoML models. ~$15–$25 per million characters. Wins on language coverage and AutoML domain customisation.
Azure Translator. 70+ languages, deep Microsoft Teams integration, HIPAA/GDPR-attested. The natural pick if you’re embedding translation inside a Teams-native or healthcare workflow.
Meta NLLB-200 + Seamless M4T. 200+ language pairs in NLLB-200, multimodal text+speech in Seamless M4T. Open-source, deployable on-prem. BLEU lags DeepL by 5–10 points on European pairs but wins on low-resource languages and on workloads that can’t leave a private cloud.
GPT-4o / Claude / Gemini for translation. The 2024–2026 wildcard. LLMs translate fluently and handle code-switching beautifully, but cost more (~$10–$30 per million chars), introduce hallucination risk on names and numbers, and add 300–800 ms latency on the API call. Good for high-stakes single-pass translation, less good for hot streaming paths.
TTS and voice cloning — the make-or-break stage for translated voice
Listeners forgive a translated caption that’s slightly clunky; they don’t forgive a translated voice that sounds robotic, mid-sentence, or detached from the speaker. Pick TTS like you’re picking the voice of your product.
ElevenLabs Multilingual v3 + Flash v2.5. First-token latency ~75 ms, expressive voices, 30+ languages, voice cloning from 3–5 minutes of source audio. The 2026 production default for most video products.
Microsoft Azure Neural TTS & Personal Voice. Wider language coverage, HIPAA/GDPR posture out of the box, voice cloning gated behind responsible-AI consent flow. Slightly higher latency (~200 ms first-token) but enterprise-friendly.
OpenAI Voice Engine, PlayHT, Resemble AI, Coqui. Voice Engine is invitation-only at the time of writing; PlayHT and Resemble are credible commercial alternatives; Coqui is the open-source self-host option for teams who can’t use a cloud TTS at all.
For more on how voice cloning works under the hood and what it costs in production, see our voice cloning & synthesis guide.
WebRTC architecture for live translated audio — the production pattern
A translation pipeline is useless if the WebRTC layer can’t pipe the result back into the call without jitter. The 2026 production pattern looks like this:
1. SFU not MCU. An SFU (Selective Forwarding Unit) gives every client a fan-out of the original media plus the option of additional translated audio tracks. An MCU adds transcoding latency and CPU cost that real-time translation can’t afford.
2. Server-side translation worker. The SFU forks a copy of the active speaker’s audio to a translation worker that runs ASR, MT and TTS. Captions return over a WebRTC data channel; translated voice returns as an additional audio track that the listener client can swap in for the original.
3. VAD + speaker labelling. Voice-activity detection chunks the speech into translatable segments without breaking sentences. Speaker labels (diarisation) keep the right voice attached to the right cloned TTS profile when speakers swap mid-call.
4. Latency budget & jitter buffer. Aim for < 800 ms total for captions and 1.5–2.5 s for translated voice. The jitter buffer needs to be tunable per-listener — deaf or hard-of-hearing users on captions only can run with a tighter buffer; voice-mode listeners need a slightly bigger one to absorb TTS variance.
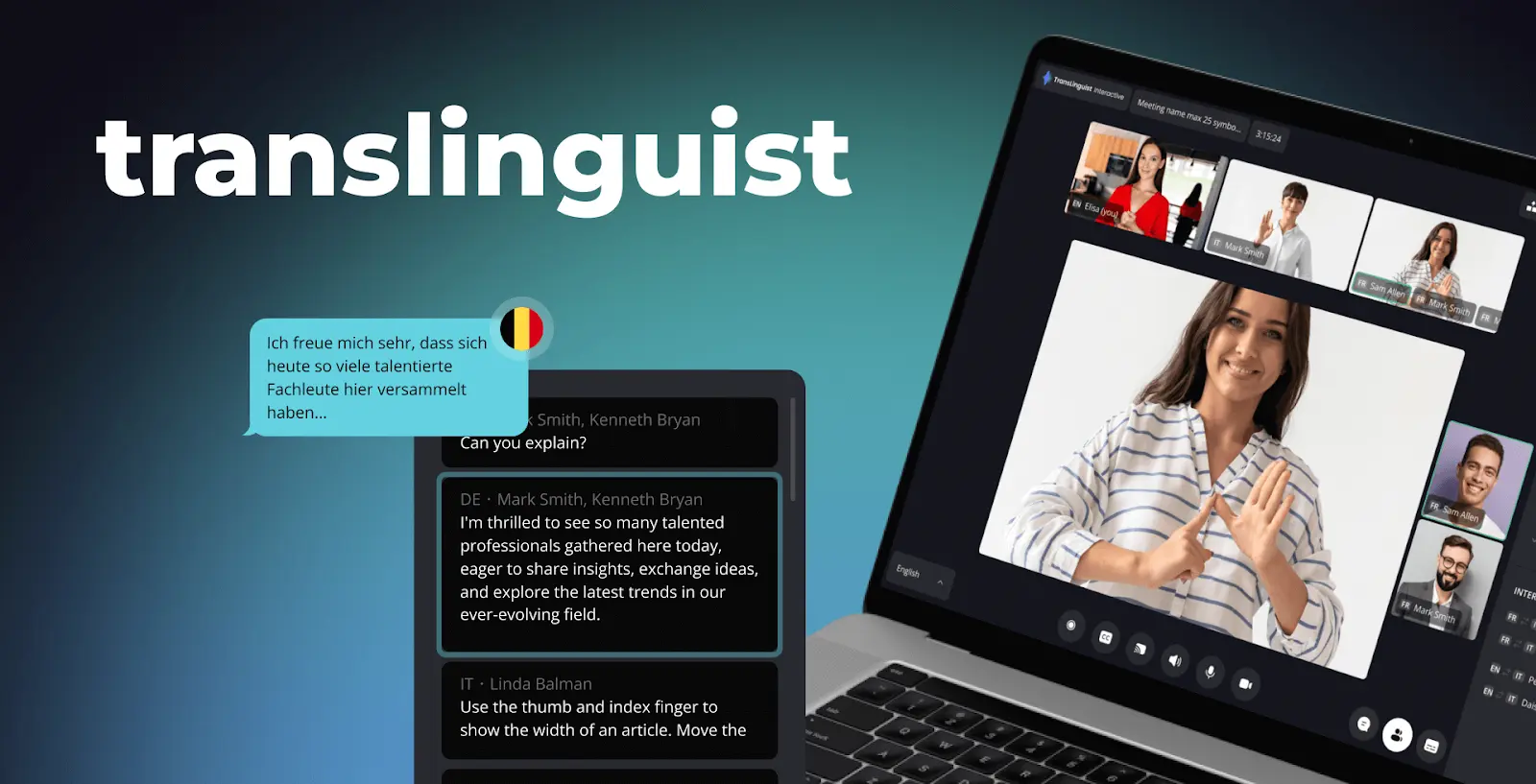
Figure 2. SFU + server-side translation worker — the 2026 production architecture.
Off-the-shelf platforms — what Zoom, Teams, KUDO, Interprefy and Wordly actually deliver
Zoom AI Companion translated captions. Now ships translated captions across 35+ languages on paid plans. Voice translation is in private preview as of 2026. Good for general business meetings; weak on domain glossaries.
Microsoft Teams real-time translated captions & speech. Translated captions in 70+ languages; real-time interpretation feature for events. Best fit if you’re already in the Microsoft 365 estate.
Google Meet real-time translation. Translated captions in major languages; voice mode launching incrementally. The most consumer-friendly default; thinner on enterprise controls.
KUDO AI & Interprefy AI. Specialised event-grade translation platforms with hybrid AI + human-interpreter workflows. Per-event pricing; meant for conferences, governmental meetings, regulated webinars. Strong in language coverage, weak as a developer SDK.
Wordly, Verbit, Maestra, Akkadu, Translanguage. Mid-market simultaneous interpretation as a service; ranges from $400/event to $2,000/event depending on languages and length. Useful at the event tier; rarely embeddable into a third-party product.
Off-the-shelf doesn’t fit your domain?
We built Translinguist for clients whose translation needs Zoom couldn’t cover. We can build the same for you in 12–16 weeks.
Cost model — what live translation actually costs at scale
A simple back-of-envelope per minute of translated audio at 2026 pricing:
- ASR: Deepgram Nova-3 streaming at $0.0092/min
- MT: DeepL at ≈ $0.0024 per 100 chars; ~150 words/min ≈ $0.018/min
- TTS: ElevenLabs Flash at ≈ $0.030 per minute of generated audio
- Subtotal: $0.057/min ≈ $3.42/hour of audio per language pair
- Add 20–30% for VAD retries, idle stream time, language detection, dropped frames — real cost lands at $0.07–$0.075/min
Translated captions only (no TTS) come in at ~$0.027–$0.035/min. Voice + cloning is the same as the cascaded cost above plus an enrollment cost ($1–$5 per cloned voice). Multiply by listener language count: a meeting with 4 active translation languages costs 4× the per-minute number.
Reach for white-label off-the-shelf when: you have < 2,000 translated calls/month, you operate in < 4 language pairs, and your listeners tolerate generic TTS voices. Below that scale the per-call savings of building your own pipeline don’t cover the engineering investment.
Compliance & data residency — HIPAA, GDPR, FERPA, AI Act
Real-time translation routes raw voice and translated text through third-party APIs. That alone breaks several common compliance regimes unless you architect carefully.
HIPAA (US healthcare). Voice of a patient is PHI. Most consumer ASR/MT/TTS APIs aren’t HIPAA-eligible without a signed BAA. The shortlist that signs BAAs in 2026: Microsoft Azure (Speech, Translator, Neural TTS), Google Cloud (STT, Translation), AWS (Transcribe, Translate, Polly), Deepgram (with enterprise plan). Open-source self-hosting on a HIPAA-aligned cloud is the more conservative pattern for telehealth.
GDPR (EU). Translated voice and biometric voice cloning are special-category data. EU-region processing is the safe default; the EU Data Boundary commitments from Microsoft and Google help, but read the fine print. Auto-delete of audio after the call and keeping only the translated transcript is the production pattern.
FERPA (US education). Student voice falls under FERPA when stored as identifiable data. Most off-the-shelf translation platforms don’t document FERPA posture; build-your-own with auto-delete and on-prem ASR is the safer route for K-12 and US higher-ed.
EU AI Act. Voice cloning is now an explicit transparency obligation: listeners must be informed when a translated voice is AI-generated. Bake this into the listener UI, not the legal small print.
Mini case — Translinguist, the live event interpretation platform we built
Situation. An events client needed real-time interpretation for international conferences with 6–10 simultaneous languages, hybrid AI + human-interpreter fallback, custom domain glossaries per event, and a transcript and dubbed-audio archive that holds up in regulated industries. Off-the-shelf platforms covered < 60% of the workflow.
What we built. Translinguist — a WebRTC SFU + server-side translation worker pipeline that combines streaming ASR, neural MT with per-event glossaries, multilingual TTS, voice cloning for branded speaker voices, and a one-click handoff to a human interpreter when AI confidence drops below threshold. Captions go out over a WebRTC data channel; translated voice goes out as a second audio track each listener can swap in.
Outcome. Sub-2 second translated voice latency, sub-800 ms caption latency, 92% AI confidence on rehearsed content with a smooth fallback to human interpreters when needed. The platform now powers multi-language events for clients in finance, education, government and corporate communications.
Build vs buy — when custom translation pays back
Buy off-the-shelf when: < 2,000 translated calls/month, < 4 language pairs, generic content, no domain glossary, listeners tolerate generic voices, and your data-residency story can live with a US/EU cloud vendor.
Build a custom WebRTC + translation pipeline when: you operate > 2,000 calls/month, you need domain glossaries (legal, medical, financial, technical), data residency is a hard constraint (HIPAA, FERPA, EU on-prem), the listener UX has to feel native to your product (your own caption styling, your own voice swap UI), or your business model is selling translation as a feature, not consuming it.
Vertical anchors that force custom every time: courtroom interpretation, telehealth voice dubbing, eSports live broadcast, religious-service interpretation, simultaneous interpretation for live events with regulated speakers, K-12 / FERPA classroom translation. We’ve built or scoped each of these in the last three years.
Honest cost shape. A custom WebRTC + cascaded translation MVP runs from roughly $90–$160K and 12–16 weeks with our team using Agent Engineering acceleration; comparable off-the-shelf integrators tend to quote $250K+ and 6–9 months. Where the scope demands voice cloning, low-resource languages, or full HIPAA/GDPR posture, we scope discovery first instead of guessing at totals.
Decision framework — pick a translation strategy in five questions
Q1. Captions only or full translated voice? Captions are 60% of the value at 30% of the cost and stay below regulatory radar in most jurisdictions. Voice is the conference-grade experience; budget the extra latency, cost and compliance work.
Q2. How many language pairs in the same call? 1–3 pairs → off-the-shelf is fine. 4–10 pairs concurrently → you’re past the sweet spot of every consumer platform; plan a custom SFU with parallel translation workers.
Q3. What’s the latency budget for your audience? Telehealth + 1:1 conversations → tight (< 1.5 s voice). Conference broadcast → relaxed (3–5 s voice acceptable). Recorded webinars → minutes are fine.
Q4. What compliance regime are you in? HIPAA, FERPA, GDPR, MAS, OSFI, SOC 2, AI Act — each adds non-negotiable architecture constraints. Pick the engine vendors that sign the right paper.
Q5. Is translation a product feature or a hidden infrastructure piece? If it’s a product feature you market, custom is almost always the answer. If it’s a hidden infrastructure piece nobody notices, off-the-shelf is fine.
Five pitfalls we see in almost every live translation rollout
1. Optimising for one stage, not the chain. Teams chase Whisper-grade ASR accuracy then plug it into a slow MT and a 400 ms TTS — net latency 4 s, listeners drop. Fix: budget the full pipeline up front and benchmark end-to-end, not stage-by-stage.
2. Ignoring domain vocabulary. Generic ASR misses "tachycardia," "anti-money-laundering," "sovereign immunity" or game-specific terms. WER explodes from 6% to 25% on real content. Fix: per-event glossaries, custom vocabulary, fine-tuned acoustic models for the verticals that need it.
3. Hallucinated names and numbers. LLM-based MT happily invents plausible-but-wrong translations of proper nouns, dates, dosages and dollar amounts. Fix: pre-extract entities and pin them through translation; ground numerics with a separate parsing pass.
4. Voice cloning without consent UX. EU AI Act and several US state laws now require explicit notice when listeners hear an AI-generated voice. Fix: visible "AI voice" badge, opt-out toggle, recording disclosure, signed enrollment for any cloned speaker.
5. Forgetting accessibility for the source language. Translation is for cross-language listeners; live captions in the source language are for hearing-impaired listeners. They’re different features but the same engine. Fix: ship both from day one.
KPIs — how to measure that real-time translation actually works
Quality KPIs. WER on conversational audio (target ≤ 8% for English, ≤ 12% for non-English mainstream); BLEU/COMET against reference translations on rehearsed content (target ≥ 35 BLEU on European pairs); MOS naturalness on TTS output (target ≥ 4.0/5); listener-reported intelligibility on a 5-point scale (target ≥ 4).
Latency KPIs. Caption latency p50 / p95 (< 800 ms / < 1.5 s); translated voice latency p50 / p95 (< 2 s / < 3.5 s); jitter buffer underrun rate (< 1% of seconds); sentence-completion delay (the “wait-k” trade-off, target k = 3 words).
Reliability KPIs. Translation worker uptime (≥ 99.9%); language-pair availability (every supported pair ≥ 99% week-over-week); fallback-to-human-interpreter rate when AI confidence drops (≤ 5% on rehearsed content); audio packet loss compensation success rate (≥ 98%).
When NOT to add live translation
Don’t add translated voice for clinical-decision conversations where mistranslation could cause harm. Captions plus a documented human interpreter SLA is the responsible default for those calls.
Don’t add translation in 12 languages because someone asked for it on a sales call. Each language adds compute cost, support burden and quality variance — ship 2–3 strong languages first, then expand.
Don’t build a custom translation stack to save $2,000/year in vendor licences. Below ~2,000 translated calls/month, the engineering hours don’t pay back; off-the-shelf is the right answer.
Reach for hybrid AI + human interpreter when: the meeting is regulated, recorded, broadcast or contractually consequential. AI handles the bulk of the volume; humans take over the moments that can’t fail.
Want a translation pipeline that’s yours, not a third-party widget?
We’ll scope a custom WebRTC + translation MVP for your video product in 48 hours — latency, languages, compliance, cost.
Streaming protocols and end-to-end speech-to-speech models
Two architectural lanes coexist in 2026. The cascaded ASR → MT → TTS pipeline is the production default for almost every commercial deployment. End-to-end speech-to-speech (S2S) models — Meta’s Seamless Streaming, Google’s Translatotron 3, the i-LAVA voice-to-voice architecture — are research-grade or limited-language as of this writing.
Cascaded streaming wins on debuggability. When a translated line goes wrong you can isolate the failure to ASR, MT or TTS. Custom glossaries, per-event vocabulary, and language-pair-specific tuning all live on the cascaded pipeline. Cost per minute is also better understood and easier to budget.
End-to-end S2S wins on prosody. Where it ships, S2S preserves emotion, emphasis and speaker style across languages in ways that cascaded TTS struggles with. Meta’s Seamless Streaming reaches roughly 100 input languages and 36 output languages for speech, with ~2 s S2S latency. Google’s Translatotron 3 is in research preview. Watch this space, ship cascaded today.
WebRTC delivery options. Translated voice lands as either a second audio track on the existing peer connection (cleanest) or via a dedicated channel (older clients). Captions ride a WebRTC data channel for sub-frame latency. SRT or HLS are options for one-to-many broadcast scenarios where direct WebRTC isn’t viable.
Reach for end-to-end speech-to-speech when: your language pairs are inside Meta Seamless’s coverage, prosody preservation is a marketing feature, you can tolerate ~2 s latency, and your compliance regime allows the model’s data path. For everything else, cascaded is still the answer.
FAQ
What is live real-time translation in teleconferencing?
It’s the live conversion of one speaker’s voice into another language — either as captions, as translated voice, or both — with low enough latency that participants follow the conversation as it happens. The pipeline is ASR + MT + TTS + optional voice cloning, with target latency < 800 ms for captions and 2–3 s for translated voice.
Which ASR engine should I pick in 2026?
Deepgram Nova-3 wins on streaming latency (~450 ms) and cost ($0.0092/min). Whisper-large-v3 wins on language coverage (99+) but isn’t streaming-native. AssemblyAI Universal-2 wins on alphanumeric accuracy and price ($0.0025/min) but is English-strong. Azure Speech wins on enterprise/HIPAA posture. Pick by your dominant language, latency budget and compliance regime.
DeepL vs Google vs Azure for live machine translation?
DeepL leads on COMET-graded quality for European languages and adds ~150–200 ms; Google Translation v3 leads on language coverage (135) and AutoML; Azure Translator wins inside Microsoft 365 estates. NLLB-200 + Seamless M4T are the open-source on-prem option for regulated workloads.
What latency is acceptable for live translation?
Below 800 ms feels real-time for captions; 1.5–2.5 s for translated voice keeps conversational flow; above 4 s breaks turn-taking. Target p95 caption latency < 1.5 s and p95 voice latency < 3.5 s in production.
How much does live translation cost per minute?
Cascaded ASR + MT + TTS at 2026 pricing lands at roughly $0.057/min ($3.42/hour) per language pair. Add 20–30% for VAD retries and idle stream time. Captions-only drops to ~$0.03/min. Multiply by simultaneous listener language count.
When should I build vs buy a translation feature?
Buy off-the-shelf below ~2,000 translated calls/month with < 4 language pairs and generic content. Build custom above that, or when you need domain glossaries, data residency (HIPAA / FERPA / EU on-prem), product-native UX, or voice cloning on regulated content.
Is end-to-end speech-to-speech translation production-ready in 2026?
For research and demos, yes (Meta Seamless Streaming, Google Translatotron). For 100+ language pairs, custom glossaries, debuggability and compliance, no — cascaded ASR + MT + TTS still wins production deployments in 2026.
How do I make live translation HIPAA-compliant?
Use ASR/MT/TTS vendors that sign HIPAA BAAs (Azure, GCP, AWS Transcribe/Translate/Polly, Deepgram Enterprise). Auto-delete raw audio after the call; keep only translated transcripts. Run voice cloning only with documented consent. Or self-host open-source ASR/MT (Whisper, NLLB, Coqui) on your HIPAA-aligned infrastructure.
What to Read Next
Voice cloning
Voice cloning & synthesis: ultimate guide
How modern voice cloning works in production — quality, cost, compliance.
ASR landscape
Top AI speech-recognition software
A deeper review of the ASR engines we shortlist for live translation.
WebRTC
P2P vs MCU vs SFU
The architecture choice that decides whether translation latency works.
Integration guide
Video call with translator: WebRTC integration
A practical walk-through of wiring translation into a WebRTC stack.
Ready to ship live translation in your video product?
Live real-time translation in teleconferencing is no longer the unobtainable feature it was three years ago. The 2026 stack ships with sub-second captions, sub-3-second translated voice, voice cloning that fits the speaker, and a per-minute cost that earns its place in your pricing. The decisions left are which ASR / MT / TTS to combine, which compliance regime to design around, and whether to wrap it in an SFU you own or a third-party widget you rent.
If you’re anywhere on that decision — from "we want translated captions next quarter" to "we’re building the next Translinguist" — we’ve done the work many times. Bring the spec; we’ll bring the architecture, the per-minute math, and a 12–16 week MVP plan.
Talk to the team that built Translinguist
30 minutes with a Fora Soft solutions architect — vendor-neutral, latency-honest, compliance-aware.









.avif)
