



Key takeaways
• Voice assistant development is a four-layer stack. VAD, ASR, LLM/NLU and TTS, stitched by orchestration (LiveKit, Pipecat, Vapi or Retell). Pick by latency budget, languages and compliance envelope, not by brand.
• Budget the round trip. Aim for under 900 ms median speech-to-speech; 700–1,200 ms still feels fine. Alert on P95 over 1,500 ms and treat 1,800 ms as the breakdown line.
• Four metrics predict retention. WER, accent coverage, barge-in handling and endpoint detection, tracked per accent cluster on a golden set, not a single leaderboard number.
• Compliance picks your vendors. HIPAA, PCI DSS, GDPR and EU AI Act Article 50 (live 2 Aug 2026) shape the shortlist more than benchmarks do. On-prem or region-pinned inference is non-negotiable for healthcare, fintech and public sector.
• Ship in 10–12 weeks. Our Agent Engineering practice runs a production voice agent with a 2–3 person team, 30–50% faster than the traditional path, by delegating orchestration glue, telemetry and test scaffolding to AI agents under senior review.
Why Fora Soft wrote this playbook
We’ve been building real-time communication and AI-augmented products since 2005 — 21 years, 250+ shipped projects, a 50-person team. Voice assistants — live captioning, voice translation, AI sales copilots, accessibility narrators — have been part of that work since long before “voice agent” became a venture-capital category.
On Meetric we built an AI sales assistant that transcribes, analyses, and coaches sales calls across Zoom, Google Meet, and Teams — with CRM-grade structured output. On TransLinguist we shipped real-time interpretation across 75+ languages in a marketplace trusted by the UK’s NHS, and on VOLO.live a QR-code-driven browser translator that runs live subtitles and voiceover for in-venue events.
This playbook is what we tell product owners at the first call: the stack that works in 2026, the numbers a CFO will ask about, the compliance traps that kill pilots in procurement, and the rollout sequence that ships cleanly.
Planning a voice agent for your product?
30 minutes: we’ll map vendors, latency budget and compliance envelope against your use case, and tell you where to cut scope.
The four layers of a 2026 voice assistant stack
Every production voice agent is the same four boxes with different vendors in them. Get the shapes right and the vendor choice becomes a spreadsheet exercise.
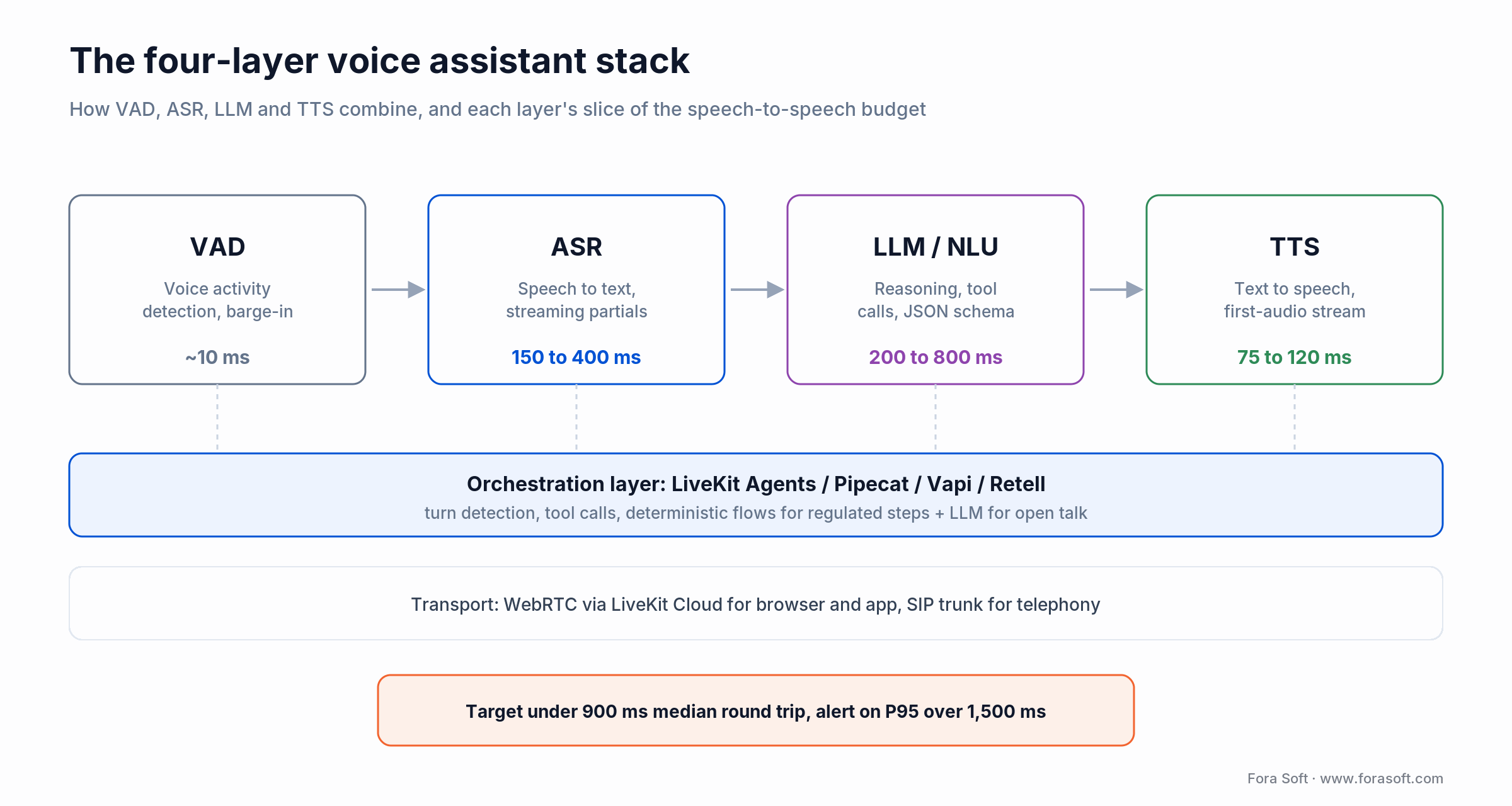
Figure 1. The four layers, plus orchestration and transport, with each layer’s slice of the latency budget.
1. Voice Activity Detection (VAD) — the entry gate
Before any transcription happens, you decide: is the user speaking? Silero VAD and WebRTC VAD are the open baselines. LiveKit Agents ships a turn-detector model on top that cuts false barge-ins by tracking sentence-completion likelihood, not just audio energy. Budget 5–20 ms per decision.
2. Automatic Speech Recognition (ASR / STT)
Open baseline: OpenAI Whisper large-v3-turbo / Parakeet / Canary from NVIDIA NeMo. Cloud vendors: Deepgram Nova-3 (Flux adds native end-of-turn detection at $0.0065/min), Soniox v4, AssemblyAI Universal, Google Chirp 3, Azure Speech, Amazon Nova Sonic. Real-time streaming, word-level timestamps, diarization, code-switching, and on-prem deployment are the four capability axes. Budget 150–400 ms for first-token partial transcripts, 500–900 ms for finalised utterances.
3. LLM / NLU / orchestration
The brain. Gemini 3.1 Flash (Mar 2026), OpenAI gpt-realtime, Claude Sonnet 5 / Haiku 4.5, Llama 4, Mistral Large 3 — pick by reasoning depth vs. latency vs. cost vs. data residency. Structured-output tool calling and strict JSON schemas are the bedrock for reliable voice agent behaviour. Budget 200–800 ms first token on a streaming response.
4. Text-to-Speech (TTS)
ElevenLabs Flash v2.5, Cartesia Sonic-3.5, Rime, OpenAI TTS, Azure Neural, Google Neural2, Amazon Polly Neural, NVIDIA Riva TTS, open models like Kokoro and XTTS. Multilingual coverage, emotion control, voice cloning with consent, and streaming first-audio latency (target under 120 ms) are the four capability axes. ElevenLabs v3 shipped GA but runs 500–800 ms first audio — higher fidelity, not for real-time; stay on Flash v2.5 for live conversation. For healthcare and fintech, Cartesia’s HIPAA/PCI posture or Riva on-prem are the safe defaults.
Latency anchor: total speech-to-speech RTT = VAD (~10 ms) + ASR partial (~300 ms) + LLM first token (~400 ms) + TTS first audio (~120 ms) + network (~60 ms). Target under 900 ms median; watch P95 more than P50.
Vendor comparison — who wins on which axis
Simplified matrix for the layers that drive cost and compliance most. Every vendor has a marketing page claiming the best of everything — run the matrix against your own 50-clip evaluation set before signing.
| Vendor / stack | Strength | Weakness | Typical use |
|---|---|---|---|
| Deepgram Nova-3 | Low-latency streaming, Nova-3 + Flux end-of-turn, multilingual | Cloud-first; on-prem requires enterprise SKU | B2B call centres, sales AI, meeting tools |
| Soniox v4 | 60+ languages, code-switching, speaker detection | Smaller ecosystem than Deepgram | Multilingual agents, live translation |
| AssemblyAI Universal | Industry-leading WER on English, 99+ languages, built-in summarisation | Streaming slightly higher latency than Deepgram | Post-call analytics, compliance transcription |
| NVIDIA Riva | On-prem, GPU-accelerated, ASR + TTS + NMT in one SDK | Requires RTX / Hopper / Blackwell fleet | Healthcare, defence, air-gapped deployments |
| OpenAI gpt-realtime | Unified speech-to-speech GA, top reasoning, ~$0.05–0.10/min cached | Data-residency controls weaker than Azure / on-prem | Consumer agents, prosumer tools, fast pilots |
| Google Gemini 3.1 Live | Multimodal speech + vision, native-audio dialog, EU hosting | Maturing tool-calling ergonomics | EU-regulated products, multimodal agents |
| ElevenLabs Flash v2.5 | ~75 ms first audio, 32 languages, voice cloning | Cloud-only; cost scales with characters | Consumer voice, media, branded assistants |
| Cartesia Sonic-3.5 | 75–90 ms first audio, HIPAA + PCI posture, WebSocket-native | Smaller voice library than ElevenLabs | Healthcare, fintech, regulated voice AI |
| LiveKit Agents | Open-source orchestration, mature WebRTC transport, turn detection | You own ops, observability, eval rig | Owned stacks, on-prem, custom latency tuning |
| Vapi | 100+ languages, 40+ integrations, managed telephony | SaaS lock-in, per-minute pricing | Outbound / inbound call agents at scale |
| Retell AI | ~$0.07/min platform fee, drag-and-drop flows, deep telephony | Less flexibility on custom tool chains | Healthcare, insurance, logistics phone agents |
Designing the latency budget — what “feels human” actually means
Human-to-human phone conversation sits around 200–300 ms of turn-taking lag. Hit that and you’re indistinguishable in most blind tests. Modern voice agents can’t quite get there on the cloud path, but they can stay inside the “natural enough” band.
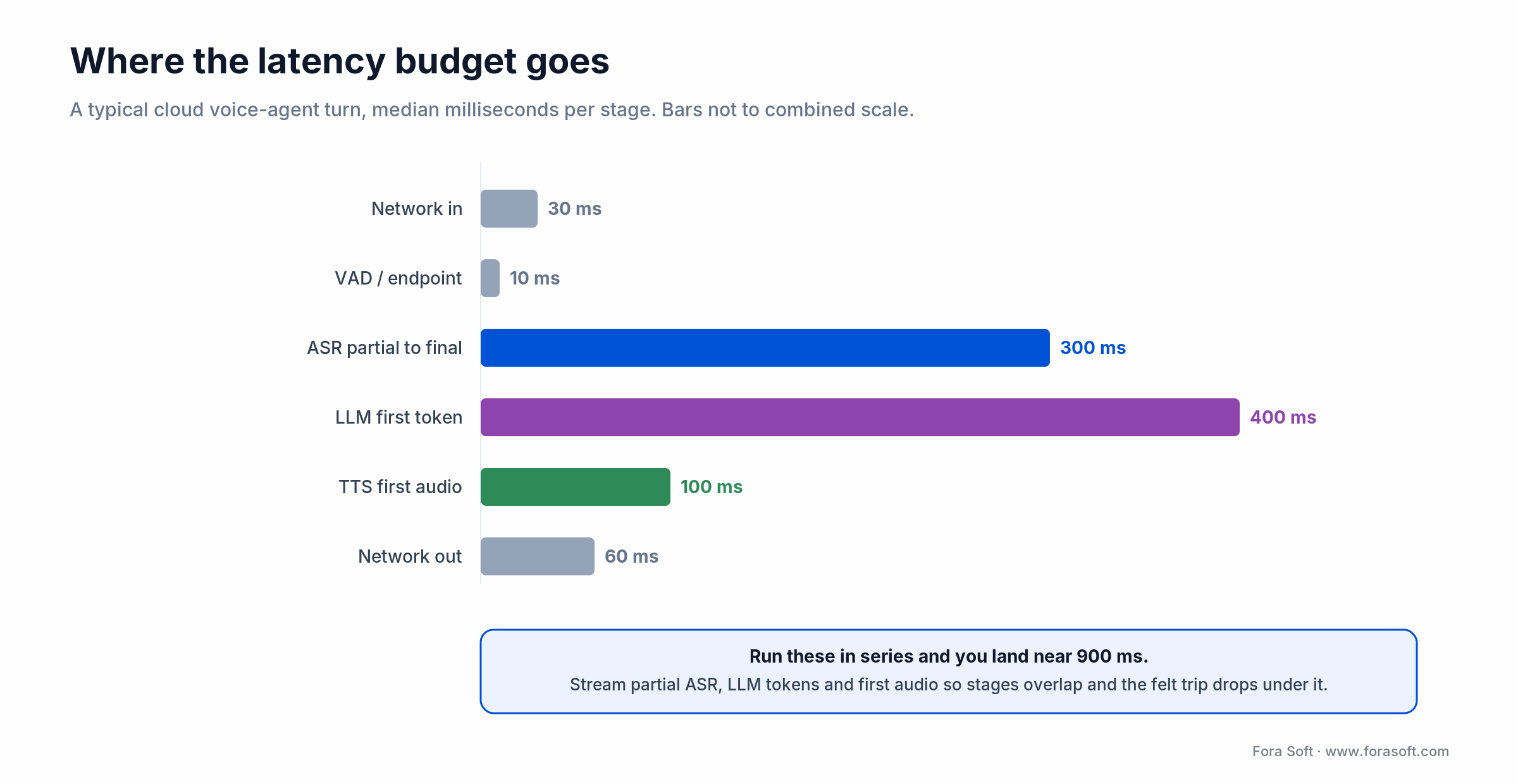
Figure 2. A typical cloud voice-agent turn: stream the stages so the felt round trip stays under 900 ms.
Under 700 ms median speech-to-speech. Feels conversational; users stop noticing the lag. Requires streaming partial transcripts, LLM streaming output, and TTS that starts audio on first token.
700–1,200 ms. Acceptable. Users occasionally interrupt; barge-in handling has to be solid.
1,200–1,800 ms. Feels like an old IVR. Users repeat themselves, start typing instead, or drop.
Above 1,800 ms. Breakdown territory. Retention drops 30%+.
P95 is the real metric. Median latency hides cold starts, slow LLM tokens, and TTS queue jitter. Alert on P95 > 1,500 ms, not P50.
Quality metrics that correlate with retention
Word Error Rate (WER). Primary ASR quality signal. Target < 5% on clean English, < 10% on accented speech, < 15% on noisy phone audio. Track by language, accent cluster, and SNR bucket.
Turn-taking accuracy. False barge-ins, missed user turns, premature endpointing. Measure against a labelled 200-conversation golden set; target < 3% false barge-in rate.
TTS naturalness (MOS / CMOS). Run a 5-point Mean Opinion Score with 20 listeners every time you swap voice models. Below 3.8 MOS, users notice. Below 3.5, they disengage.
Task success rate. End-to-end: did the user complete the task (book the appointment, get the refund, reach the right human)? Correlates directly with LTV; nothing else matters if this is low.
Abandonment before first response. If it takes > 2 seconds from connection to first audio, you lose 15–25% of callers. Measure at the transport layer, not the app layer.
Golden-set rule: record 200 real conversations (with consent) covering every accent cluster, language pair, and task type in your product — and run every model change against the full set before shipping. A regression on a sub-cluster is the #1 silent quality killer.
Reference architecture for a 2026 voice agent
The stack we ship by default on AI integration engagements.
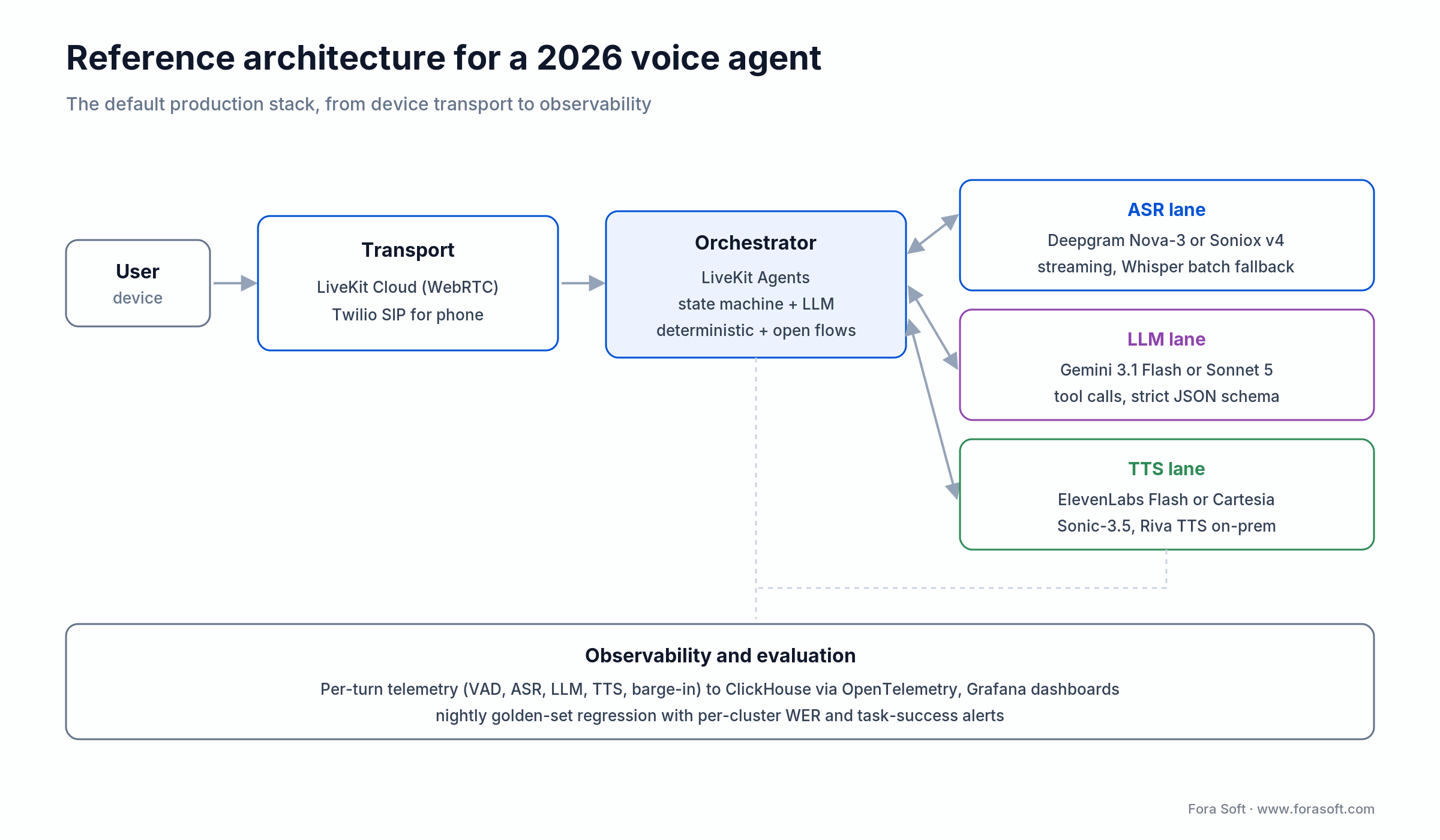
Figure 3. The production stack we ship by default, from device transport to nightly golden-set regression.
Client / transport. LiveKit SDK (web, iOS, Android, Unity) over WebRTC for browser and app — the same open-source transport OpenAI runs ChatGPT’s Advanced Voice on; Twilio Voice + SIP trunk into LiveKit for phone. Echo cancellation, auto gain control, and noise suppression at the capture layer.
Orchestration. LiveKit Agents or Pipecat running on dedicated GPU-backed nodes. State machine + LLM hybrid: deterministic flows for regulated steps (authentication, payment), LLM-driven flows for open conversation. For the deep transport design, see how AI agents work with WebRTC.
ASR lane. Deepgram Nova-3 or Soniox v4 for streaming; Whisper-large-v3-turbo for offline / batch. Fallback routing on rate-limit or region outage.
LLM lane. Gemini 3.1 Flash for latency-sensitive turns; Claude Sonnet 5 or gpt-realtime for reasoning-heavy tasks. Tool calling via strict JSON schemas; every tool call logged with request/response hash.
TTS lane. ElevenLabs Flash v2.5 for consumer, Cartesia Sonic-3.5 for regulated, Riva TTS on-prem for air-gapped. Voice caching for frequent phrases (greetings, disclaimers) to eliminate first-audio latency on those.
Observability. Per-turn telemetry: VAD decision, ASR partial + final, LLM token stream, TTS first audio, barge-in events, turn success. OpenTelemetry traces into a columnar store (ClickHouse or DuckDB); Grafana for dashboards.
Compliance — the envelope that picks your vendors for you
HIPAA (US healthcare). PHI must not leave BAA-covered infrastructure. Cartesia, Deepgram Enterprise, NVIDIA Riva on-prem, and Azure Speech (BAA) are the short list. Cloud consumer APIs without BAA are a no.
PCI DSS (payment voice). Never let raw card data hit ASR. Design dual-tone multi-frequency (DTMF) capture or pause-and-resume recording for the payment step; keep ASR for the non-card conversation only.
GDPR (EU). Data residency, consent records, and right-to-erasure apply. Use EU-hosted endpoints (Gemini Live EU, Azure EU regions) and keep retention policies short; 30 days is a reasonable default for call recordings.
EU AI Act. From 2 August 2026, Article 50 transparency rules apply: any system that talks to a user has to make clear it’s an AI (Art 50(1)). Machine-readable marking of synthetic output (Art 50(2)) has a grace window to 2 December 2026 for systems already live (AI Omnibus, May 2026). Bundling biometric categorisation or emotion recognition escalates the risk class sharply; keep those off by default.
Voice cloning & synthetic-voice anti-fraud. Always obtain explicit written consent before cloning a voice; add audible or watermark-based provenance for agent output where fraud risk is material. C2PA for audio is still maturing but moving fast.
Accents, dialects, and code-switching — the hard middle layer
Most ASR leaderboards publish a single English number. Production users don’t speak leaderboard English. A 4% WER on the Hugging Face Open ASR leaderboard often becomes 12% on Indian English, 18% on thick regional UK, and 25% on code-switched Spanglish or Hinglish. For how we treat evaluation across real-time media, see our AI-for-video engineering notes.
Fix with a multi-model ensemble. Primary model (Deepgram or Soniox) with a fallback on specific accents; route by detected locale + user profile + first-utterance confidence.
Use keyword biasing. All major ASR vendors support custom vocabularies. Feed your product glossary, proper nouns, and domain terminology; WER drops 30–60% on those tokens.
Design for code-switching. Set language to “auto” (Soniox, Google Chirp 3) and prompt the LLM with examples of the target language pair. A user toggling between Spanish and English in one call is a real 2026 requirement, not an edge case.
Mini case — cutting voice-agent handle time 28% in 10 weeks
Situation. A mid-market fintech ran an outbound collections agent on an older Vapi-style stack. Median speech-to-speech RTT was 1,600 ms, task success rate 42%, average handle time 7.2 minutes, agent hand-off rate 34%.
10-week plan. Weeks 1–2: 200-call golden set + baseline telemetry. Weeks 3–5: migrate to LiveKit Agents with Deepgram Nova-3 streaming + Gemini 3.1 Flash + Cartesia Sonic-3.5; build eval rig. Weeks 6–7: tune turn detection, add keyword biasing for payment terminology, implement PCI-compliant DTMF capture. Weeks 8–10: rollout to 20% of traffic, then 100%; observe, iterate.
Outcome. Median RTT 720 ms (P95 1,350 ms). Task success 58%. Average handle time 5.2 minutes (−28%). Hand-off rate 22%. Want a similar read on your stack? Book a 30-min voice-agent review.
Pinning down your latency and vendor picks?
We’ll score your current path against a production reference stack and walk you through the trade-offs in 30 minutes.
Rollout roadmap — the 12-week sequence we ship most often
Don’t swap every layer at once. This is the slot plan that lands cleanly across healthcare, fintech, and SaaS voice-agent projects.
| Weeks | Workstream | Deliverable | Exit criteria |
|---|---|---|---|
| 1–2 | Golden set + telemetry | 200 recorded conversations; per-layer latency baseline | Measurable starting point per metric |
| 3–4 | Core stack spike | LiveKit Agents + ASR + LLM + TTS end-to-end prototype | P50 RTT < 1,000 ms on 10 golden clips |
| 5–6 | Flow + tool-calling | State machine, tool-call JSON schemas, CRM integrations | End-to-end task success > 80% on 50 scripted calls |
| 6–8 | Compliance & accessibility | DTMF payment path, PII redaction, consent flows, WCAG controls | External security review passed |
| 8–10 | Accent & language coverage | Keyword biasing, multi-locale routing, fallback models | No language cluster > 12% WER on golden set |
| 10–11 | Gradual rollout | 5% → 20% → 50% traffic shift with automated rollback | No P1 regression over 72-hour bake |
| 11–12 | GA + observability | Dashboards, alerting, nightly regression run | Zero silent quality regressions for 14 days |
Decision framework — pick your stack in five questions
1. What’s the compliance envelope? HIPAA / PCI / GDPR / on-prem — this removes more vendors than any other factor. Answer this first; everything else is downstream.
2. What’s the latency budget? Consumer conversational under 900 ms; IVR-replacement under 1,500 ms; batch transcription doesn’t care. Pick vendors that hit your P95 not your P50.
3. What languages and accents? English-only is easy; 30+ languages with code-switching narrows you to Soniox v4, Deepgram Nova-3, or Google Chirp 3 streaming.
4. Build vs. SaaS? LiveKit + your vendors gives control, observability, cost at scale; Vapi / Retell / Bland gives fastest time-to-first-call. A 20k-calls-a-month line is roughly the break-even; we break the platforms down in our AI call assistants buyer’s guide.
5. What’s the exit if a vendor disappears? Keep Whisper, Kokoro/XTTS, Llama 4, and Riva in the eval; if your primary vendor doubles prices or gets acquired, you need a one-sprint fallback.
Five pitfalls we see in AI voice assistant projects
1. Optimising median latency, ignoring P95. The median looks great in demos; P95 is what users actually feel. Instrument and alert on P95.
2. Single-vendor lock-in on ASR or TTS. Pricing doubles, region outages, leadership change — the vendor risk is real. Keep a 2-sprint fallback path warm.
3. Letting PCI-regulated data touch ASR. Raw card numbers in ASR logs are a seven-figure remediation. Design DTMF + pause-and-resume from day one.
4. Flat evaluation set. One English test corpus hides regressions on accents, noise, and code-switching. Split by cluster; alert on per-cluster regression, not average.
5. Over-indexing on LLM reasoning. The best voice agents keep the LLM on a short leash: deterministic flows for regulated steps, LLM only for open language. Pure LLM agents drift and hallucinate at scale.
KPIs worth tracking
Quality KPIs. WER per language cluster, turn-taking accuracy, TTS MOS, task success rate. Weekly dashboard; quarterly human-rated reviews.
Latency KPIs. P50 and P95 speech-to-speech RTT, first-audio latency, time-to-first-partial-transcript. Alert thresholds on P95.
Business KPIs. Average handle time, hand-off rate, abandonment before first response, cost per successful task, NPS / CSAT on completed calls.
Reliability KPIs. End-to-end success rate (no transport or service failure), model-version drift, daily regression test pass rate on the golden set.
Agent Engineering — how we cut voice-agent build time 30–50%
A 12-week voice-agent rollout used to need 4–5 senior engineers. With our Agent Engineering practice we run the same scope with a 2–3 person team, because the orchestration boilerplate, tool-call schemas, golden-set scaffolding, evaluation rig, and observability dashboards are drafted by AI agents under engineer supervision.
Where agents do the work. LiveKit Agents boilerplate, Pipecat pipeline composition, vendor SDK glue, WER/MOS evaluation rigs, Grafana dashboards, PII redaction regex catalogues, CI/CD pipelines for voice-model rollouts, load-test rigs, and 70–80% of test fixtures.
What it means commercially. A production voice agent that used to land at 16–20 weeks now lands at 10–12 weeks — with the savings split between calendar (earlier go-live) and fixed-bid pricing.
What it doesn’t change. Architecture choices, vendor due diligence, compliance review, accessibility design, and golden-set curation are still senior-engineer work. Agents amplify the team; they don’t replace the judgment calls.
Pricing check: if a voice-agent partner is charging you by senior engineer-week without an agent-engineering practice, you’re paying a 30–50% premium for capacity that doesn’t need to be human anymore. Ask how much of the stack their agents draft.
Accessibility as a first-class feature
Voice agents that work for everyone pick up a bigger market and also pass public-sector procurement. Budget accessibility as feature work from week one, not retrofit from week ten.
Slow-speech mode. Users with hearing aids, ESL speakers, and older users often ask agents to slow down. Expose TTS rate as a first-class control; persist in the user profile.
Text-to-voice and voice-to-text parity. Let users type at any time instead of speaking, and receive text transcripts alongside audio. This is table stakes for accessibility and quietly helps engagement metrics in noisy environments too.
Screen-reader compatibility. WCAG 2.2 AA on every control; agent status (listening / thinking / speaking) exposed via ARIA live regions so screen readers announce state changes.
Multilingual auto-detect with override. Auto-detect is great until it picks the wrong language. Always expose a manual language picker; persist across sessions.
When not to build a voice assistant
Under 5,000 monthly voice interactions. The infra, eval, and ops overhead won’t pay back. Ship a chat-first product; add voice in year two.
High-stakes decisions with poor fallback. Medical triage, legal advice, major financial decisions — voice agents are fine for intake and routing, bad for the final call. Design a human hand-off that’s always one utterance away.
Pure end-to-end encrypted products. Cloud ASR/TTS requires decrypted streams at the server. If you promised E2EE, either run on-device models and accept the quality trade-off, or don’t ship voice.
Product niches with strong non-voice preference. Legal, enterprise procurement, long-form research — users prefer typing. Measure demand with a text agent first.
Data architecture — what to keep, what to throw away
Raw audio. Only keep if consent, compliance, or fraud evidence demands it. Default retention: 30 days for recordings, 180 days for transcripts.
Structured turn telemetry. Per-turn VAD / ASR / LLM / TTS metrics into a columnar store. ~200 bytes per turn; multi-year retention is cheap and answers every debug question that matters.
Golden set. 200–500 hand-curated conversations across all language clusters and task types, stored in WORM storage. Nightly regression run; alert on per-cluster regression.
Model-version catalogue. Every turn logged with ASR model hash, LLM model version, TTS model hash, and prompt-template version. Required for EU AI Act documentation and silent-regression debugging.
Realistic 2026 cost picture
ASR streaming. $0.005–$0.015 per minute depending on vendor, tier, and language. At 100k minutes/month you’re in the $500–$1,500/month band.
LLM inference. For voice, budget 200–400 tokens in and 80–200 tokens out per turn. Gemini 3.1 Flash and Claude Haiku 4.5 typically cost a fraction of a cent per turn; gpt-realtime tier roughly 3–8× that ($32/$64 per 1M audio tokens, ~$0.05–0.10/min cached).
TTS. ElevenLabs Flash v2.5 and Cartesia Sonic-3.5 price per character. A one-minute response is roughly 1,000 characters; budget $0.01–$0.04 per minute in steady state.
Transport. WebRTC transport via LiveKit Cloud or self-hosted adds $0.001–$0.005 per participant-minute. Managed platforms bundle this: Vapi hosting is ~$0.05/min and Retell ~$0.07/min, but all-in (STT + LLM + TTS + telephony) both land near $0.12–$0.35/min. Telephony (Twilio, Vonage) adds the regulated per-minute fee on top.
All-in benchmark. A medium-complexity voice agent in steady state lands at $0.06–$0.18 per minute of conversation. Compare against a $0.75–$1.80/minute human-agent fully loaded cost; payback is fast at even modest volumes.
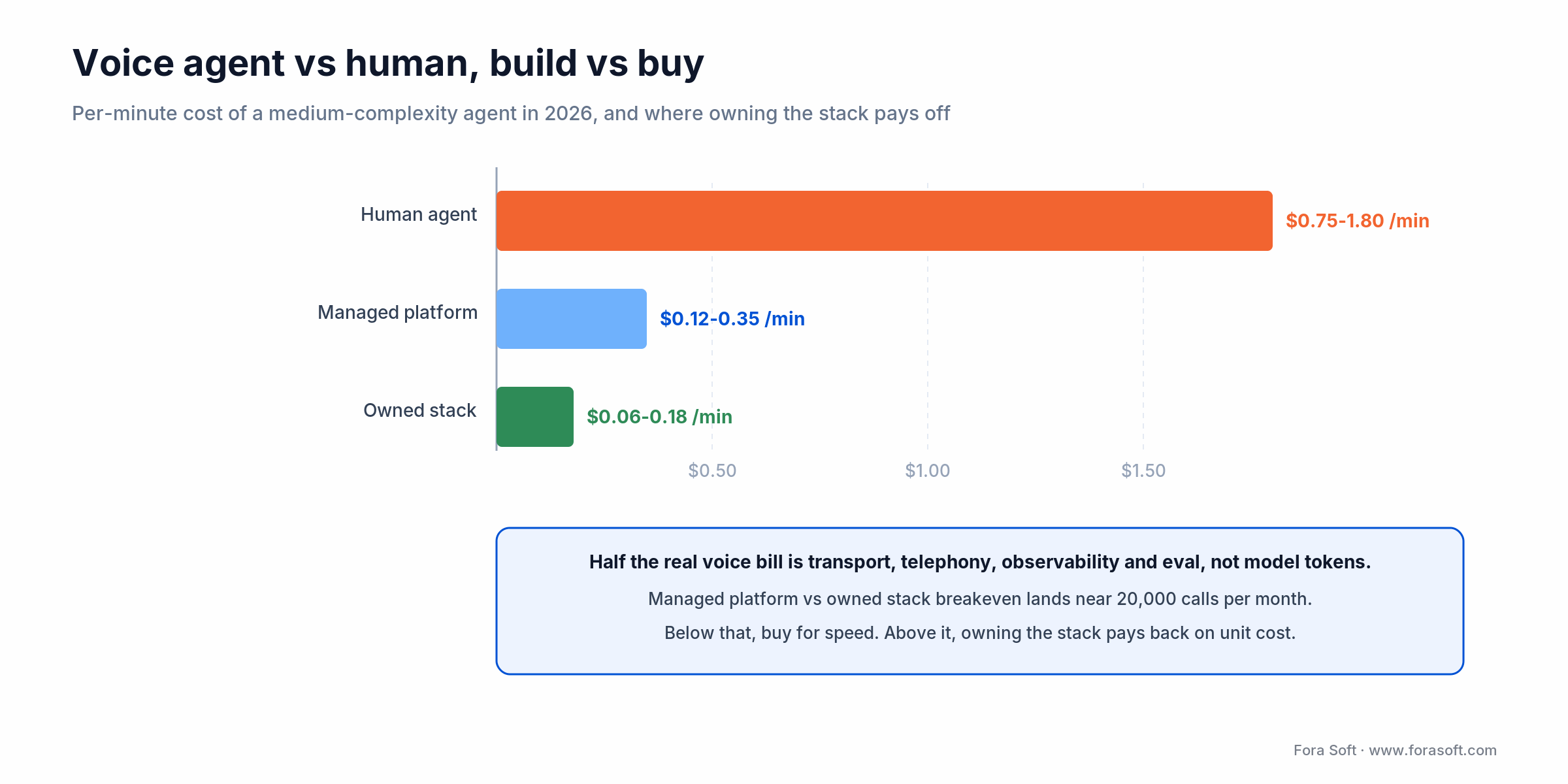
Figure 4. Per-minute economics: an owned voice stack undercuts human agents and, past ~20k calls/month, managed platforms.
Cost anchor: don’t price your voice agent as “AI inference cost × minutes.” Half the real bill is transport, telephony, observability, and evaluation infrastructure — model the whole stack before you forecast unit economics.
Want our fixed-bid voice-agent estimate for your use case?
We’ll scope a 10–12 week plan with the vendor mix, compliance envelope and an honest cost-per-minute forecast. 30 minutes, no deck.
FAQ
What’s a realistic latency target for a production voice agent?
Under 900 ms median speech-to-speech RTT for consumer conversation; under 1,500 ms P95 is the alert threshold. Above 1,800 ms retention drops sharply. Instrument P95 across every call; the median hides everything that matters.
Should we use an open-source orchestrator (LiveKit, Pipecat) or a managed platform (Vapi, Retell)?
Roughly 20,000 calls/month is the break-even. Below that, managed platforms ship faster and cost less all-in. Above it, the per-minute managed fee overtakes your engineering cost and open-source + direct-vendor contracts pay back. LiveKit Agents is the default open stack we ship on today.
Can we run the whole stack on-prem for HIPAA or air-gapped deployments?
Yes. NVIDIA Riva covers ASR + TTS on-prem; open LLMs (Llama 4, Mistral) cover the reasoning layer; LiveKit self-hosted handles transport. Expect 10–50 ms added latency versus cloud, and a real GPU fleet commitment. Cartesia Sonic-3.5 is the other strong option where on-prem deployment is contracted.
How do we handle accents and code-switching without building a language model from scratch?
Use vendors with strong multilingual streaming (Soniox v4, Deepgram Nova-3, Google Chirp 3); enable language auto-detect with a manual override; feed a keyword-bias list for your product glossary; route difficult accent clusters to a specialist fallback model. WER on your hardest accent cluster is the real benchmark — not the leaderboard number.
What about PCI DSS — can an AI voice agent take a payment?
Not by capturing card digits in ASR. The compliant pattern is to hand off the card-capture portion of the call to a DTMF or pause-and-resume recording path that never lets the number land in logs or transcripts, then return to voice for confirmation. ASR stays in-scope only for non-card conversation.
Do we need to disclose that users are talking to an AI?
Yes. Under EU AI Act Article 50, from 2 August 2026 any system that talks to a user must disclose it’s an AI; several US states (California, Colorado, Utah, and growing) require the same. Keep the disclosure short and upfront, record the consent, and expose a one-phrase path to a human. Hiding the AI nature of the agent is both a legal risk and a trust killer.
How do we prevent voice cloning and synthetic-voice fraud on our platform?
Require explicit written consent with liveness proof before cloning any voice; watermark or C2PA-tag synthetic output where fraud risk is material; run anti-spoofing models against inbound audio when biometric voice auth is part of the flow. The combination is enough for most product risk; dedicated fraud teams then layer additional detection.
What’s the realistic cost per minute of a production voice agent in 2026?
$0.06–$0.18 per minute of conversation for a medium-complexity agent, stack-dependent. Compare to $0.75–$1.80/minute for a fully loaded human agent and you see why 2026 budgets are pivoting. Volume is the lever: cost per minute drops ~30–40% from 10k calls/month to 500k calls/month.
How do you test a voice agent so silent regressions don’t leak into production?
Three layers. Nightly automated regression on a 200–500-clip golden set with WER, task-success, and latency thresholds per cluster. Weekly spot-check of 30 real calls by a human reviewer. Quarterly full human rating (MOS, CSAT simulation). Model-version lock between test and prod; any version bump triggers a mandatory full run before rollout.
What to Read Next
AI receptionist
How to build an AI receptionist
The phone-native sibling to this guide: telephony stack, latency budget, and build vs buy for answering calls.
Voice APIs
AI call assistants: a 2026 buyer’s guide
Voice API, platform and compliance picks for phone agents, compared.
WebRTC
How AI agents work with WebRTC
Architectures, latency and cost for real-time voice agents on WebRTC.
LiveKit
Build AI agents on LiveKit
Voice, vision and production patterns on the LiveKit Agents framework.
Case study
Meetric — AI sales assistant across Zoom, Meet, Teams
Real-time transcription, coaching and CRM-grade structured output.
Case study
TransLinguist — interpretation in 75+ languages
NHS-trusted marketplace with 30,000+ certified interpreters and live ASR.
Ready to ship a voice agent that actually works in 2026?
Voice assistants stopped being a science project in 2024. In 2026 they’re a stack decision — four layers, a compliance envelope, a latency budget, and a rollout sequence. The teams that pick their vendors against real evaluation sets and ship a gradual 12-week rollout land cleanly; the teams that demo a prototype and blast to production don’t.
We’ve shipped voice-first and voice-augmented products for two decades. If you want the stack picks, the 200-clip golden set, the compliance map, and the honest 10–12 week plan — that’s a 30-minute call.
Start your voice agent with a half-hour plan, not a decked pitch
Pick the vendors, pin the latency budget, scope the 10–12 week rollout. One call; the notes land in your inbox.








