



Key takeaways
• Real-time video translation is a three-stage pipeline, not a product. Streaming ASR → chunked MT → streaming TTS. Latency budget 800 ms for conversational calls, 2–5 s for broadcast.
• Cascaded beats end-to-end in 2026, for now. Cascaded ASR + MT + TTS covers 100+ languages, is debuggable, and plugs into existing WebRTC/HLS stacks. End-to-end S2ST (Google Pixel 10, Azure Live Interpreter, Meta’s open M4T models) is faster and, on the consumer stacks, keeps the speaker’s voice, but still covers far fewer pairs than cascaded.
• Three quality numbers, not one. WER < 10% on ASR, COMET > 0.75 on MT, MOS > 4.0 on synthesized voice. Miss any one and users feel it.
• Captions are cheap; dubbing got cheaper. Translated captions run ~$1.10–1.60 per speaker-hour, AI dubbed ~$2–2.50. Voice cloning (ElevenLabs) is now ~$0.24–0.60/min — roughly 5× cheaper than 2024.
• Privacy wins or loses the deal. Healthcare needs on-device ASR or a signed BAA. EU customers need regional data residency. Voice biometrics are non-recoverable. Protect the audio path from day one.
Why Fora Soft wrote this playbook
Fora Soft is a software development company: since 2005 we’ve delivered 250+ video projects across 20+ years of production-grade real-time video, audio, and AI work. Fora Soft built TransLinguist, a live interpretation platform with AI speech-to-speech in 16+ languages and a marketplace of 30,000+ certified human interpreters across 75+ languages. We also ship the underlying streaming on Worldcast Live (sub-500 ms glass-to-glass, 10,000 concurrent viewers), real-time video rooms on Speed.Space (1080p/8 Mbps, 25 concurrent participants for Netflix, HBO and EA), and HIPAA-regulated video on CirrusMED across 40+ U.S. states.
That stack means we’ve wired up every permutation of real-time video translation, including Google, Azure, AWS, Whisper, Deepgram, ElevenLabs, Meta’s M4T models, and DeepL, against real WebRTC and HLS pipelines. This article is the condensed playbook: which pipeline fits which use case, which provider wins on cost vs latency, where it breaks in production, and how to make it feel native in your product.
If you want to skip the curve, our video streaming app development team has shipped this in 3–6-week sprints on every major WebRTC and HLS stack. The model-level details live in our AI-for-video engineering track.
Planning live translation on top of your stream?
30 minutes with our lead AI engineer and our WebRTC lead. Walk out with a pipeline choice, a latency budget and a cost per speaker-minute for your specific product.
What real-time streaming translation actually is
“Live translation” is an umbrella for four different products. Treating them as the same thing is the most common reason a translation pilot dies before it ships.
Live captions. Speech is transcribed and shown as subtitles in the source language. One engine (ASR), one output (text). Latency target: 300–800 ms.
Translated captions. Speech is transcribed, translated, and shown as subtitles in a target language. Two engines (ASR + MT), one output (text). Latency target: 500 ms–1.5 s.
Dubbed audio. Speech is transcribed, translated, and resynthesized as audio in a target language. Three engines (ASR + MT + TTS), one output (audio track). Latency target: 800 ms for conversational, 2–5 s for broadcast.
Voice-preserving dubbed audio. Speech is translated and resynthesized in the original speaker’s voice. Either end-to-end S2ST (Google Pixel 10 and Azure Live Interpreter keep the voice natively; Meta’s expressive M4T variant does too, but only for ~6 languages) or a cascaded pipeline with a voice clone (ElevenLabs Dubbing). Latency 2–5 s; cost higher, though the gap narrowed sharply in 2026.
Pick one as your first milestone. Captions are the safe opener; voice-preserving dubbing is the moonshot.
Builder or viewer? Most searches for “real time video translation” want a browser feature or an app to translate a video someone is watching. This playbook is the other side of that: you’re a product team adding translation to a stream your users publish or broadcast. Everything below is about the pipeline you own, host and bill for — not a consumer extension. If you want the architecture overview first, start with our real-time speech translation architecture guide.
Rule of thumb: ship translated captions first, validate demand, then add dubbed audio. Captions cost about $0.02–0.03/speaker-minute; voice-cloned dubbing about $0.24–0.60/minute.
Reach for translated captions first when: you need 100+ languages, accessibility compliance, or you’re still learning which cohorts want translation. Dubbing is the upsell, not the opener.
The three-stage pipeline: ASR → MT → TTS
The cascaded pipeline is still the default in 2026 because every stage is a well-understood, battle-tested API and every stage is debuggable on its own.
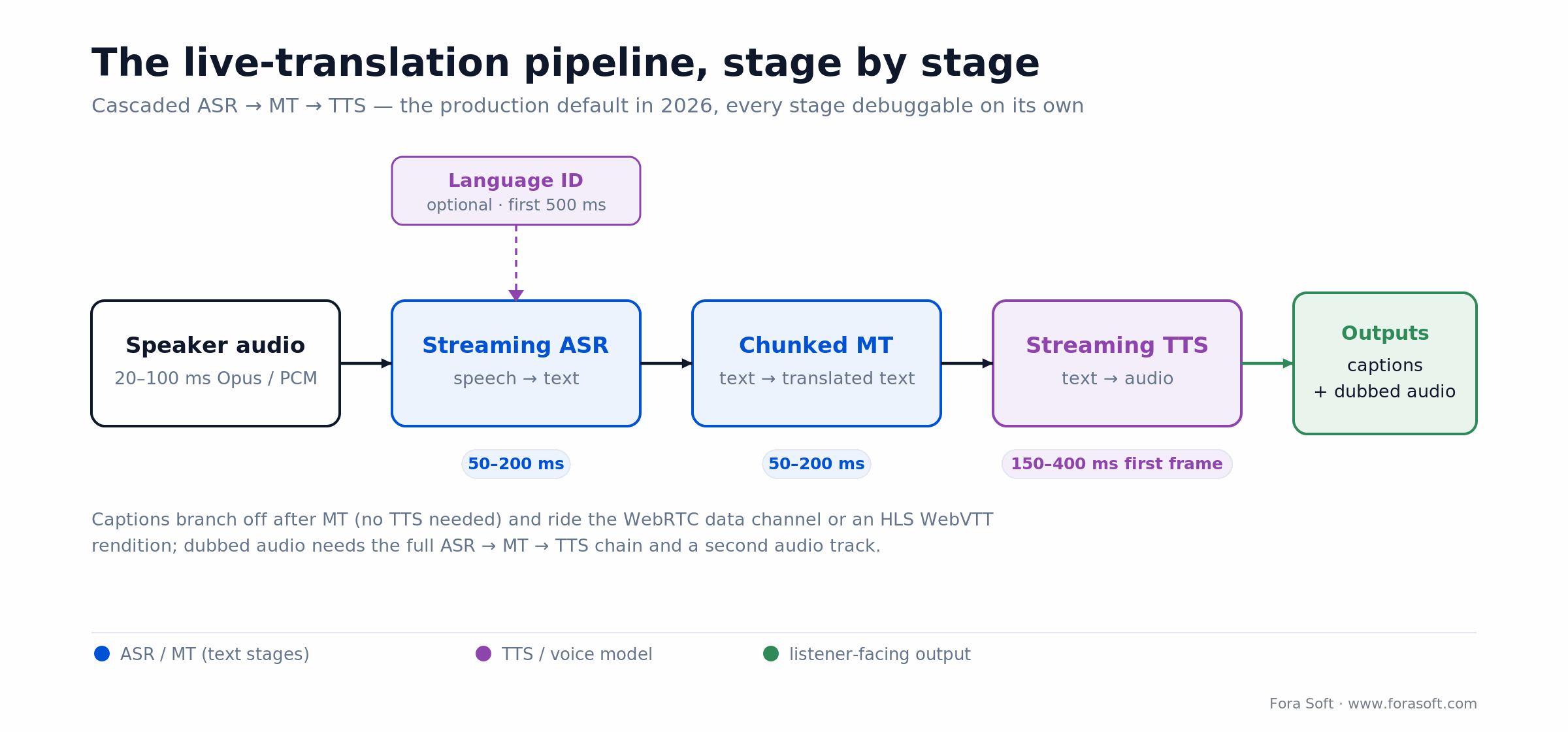
Figure 1. The cascaded pipeline — captions branch after MT; dubbed audio needs the full chain.
Stage 1: Streaming ASR (speech → text)
Audio enters as 20–100 ms PCM or Opus frames. A streaming ASR engine emits interim transcripts every few hundred milliseconds and a final transcript once an utterance is complete (typically on a voice-activity-detection pause). Latency: AssemblyAI Universal-3 Pro P50 ~150 ms; Deepgram Flux < 300 ms end-of-turn.
Stage 2: Chunked MT (text → translated text)
Translate every interim transcript so the caption updates in real time, but keep a 100–200 character context window or semantics flip (“not bad” → “bad”). DeepL, Google Translate and Azure Translator all expose streaming endpoints; for the lowest latency we use domain-glossary-tuned LLM translation with an 800-ms timeout fallback to a classical NMT engine.
Stage 3: Streaming TTS (text → audio)
ElevenLabs, Azure Neural TTS, Google Cloud TTS and AWS Polly all support chunked synthesis. They start emitting audio frames before the full input text arrives. For voice-preserving dubbing use ElevenLabs Instant Voice Clone (30-second sample) or Meta’s open M4T models (emotion-preserving speech-to-speech). Latency: 200–500 ms to first audio frame.
Optional stage: language ID
If speakers switch languages mid-stream (common in interpretation and international meetings), run a lightweight language-identification model on the first 500 ms of each utterance to pick the right ASR voice. Whisper handles this natively; commercial APIs expose it as a feature flag.
Cascaded vs end-to-end S2ST: when to pick which
End-to-end speech-to-speech translation (S2ST) promises lower latency (~2 s) and preserved speaker voice. The 2026 reality is that production-grade S2ST is still a short list.
| Factor | Cascaded (ASR + MT + TTS) | End-to-end S2ST |
|---|---|---|
| Language pairs | 100+ | ~36 speech-out (Meta M4T v2); 100+ for text; only a handful truly production-grade |
| End-to-end latency | 800 ms – 2 s | ~1–2 s (Pixel, Azure Live Interpreter, Meta streaming) |
| Voice preservation | Requires separate voice clone (ElevenLabs) | Native on Pixel/Azure; expressive M4T ~6 langs |
| Debuggability | High, each stage inspectable | Low, single black-box model |
| Cost per minute | $0.02–$0.60 | $0 (self-host M4T) to ~$3 (hosted) |
| Maturity | Production-safe across every stack | Beta–early production; expect quirks |
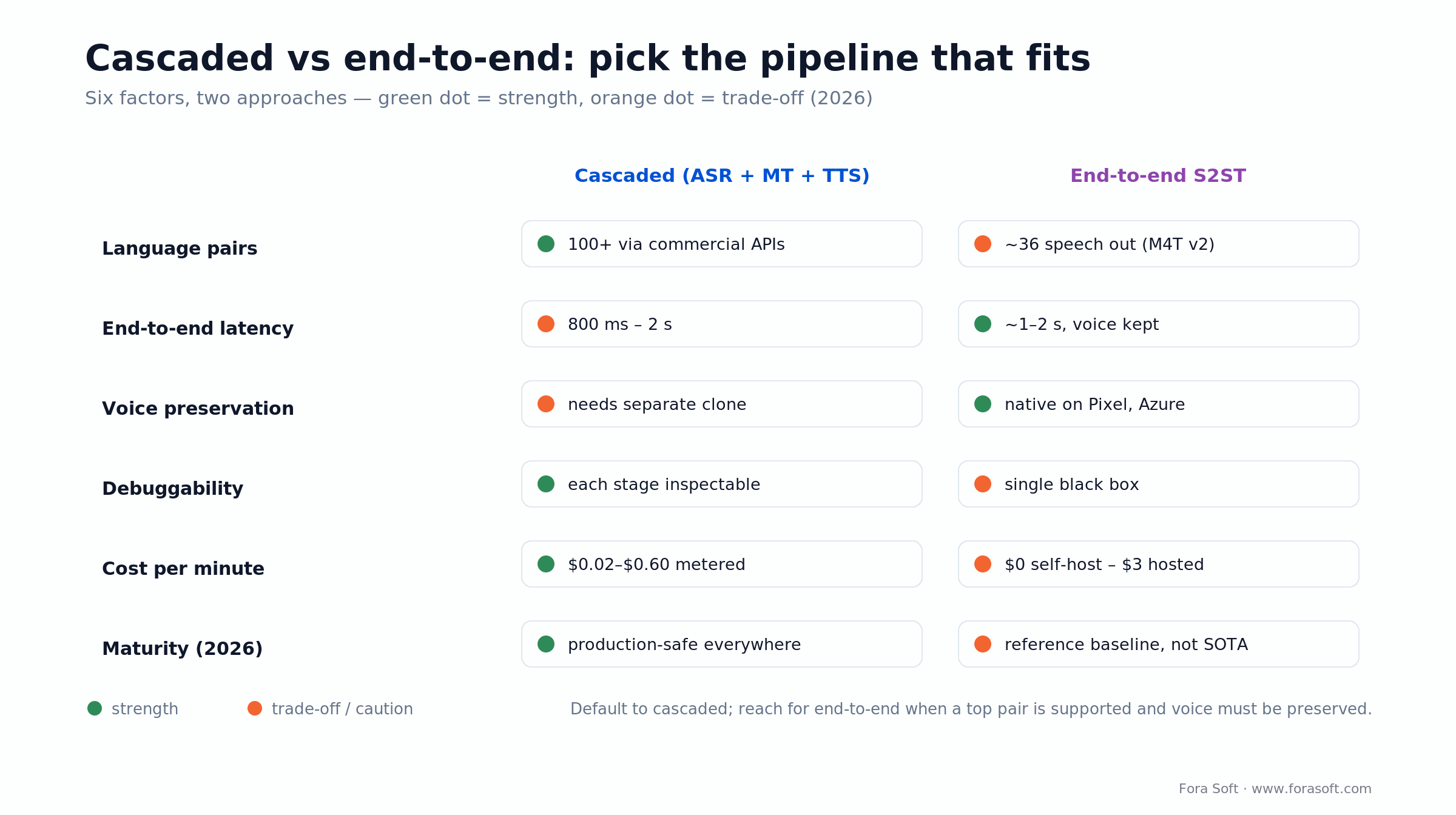
Figure 2. Cascaded vs end-to-end — green marks a strength, orange a trade-off.
Reach for cascaded when: you need more than 10 language pairs, debuggability matters, or the product is regulated. Reach for end-to-end S2ST when: one of your top pairs is supported, latency must be < 2 s, and preserving the speaker’s voice is core to the product (interpretation, cinematic dubbing). Meta’s open M4T models are the reference baseline here.
The latency budget: where every millisecond goes
Users tolerate a 500 ms conversational pause. Above 1 s they start repeating themselves. Above 2 s they interrupt the translated speaker. Hitting 800 ms end-to-end on a cascaded pipeline is the craft.
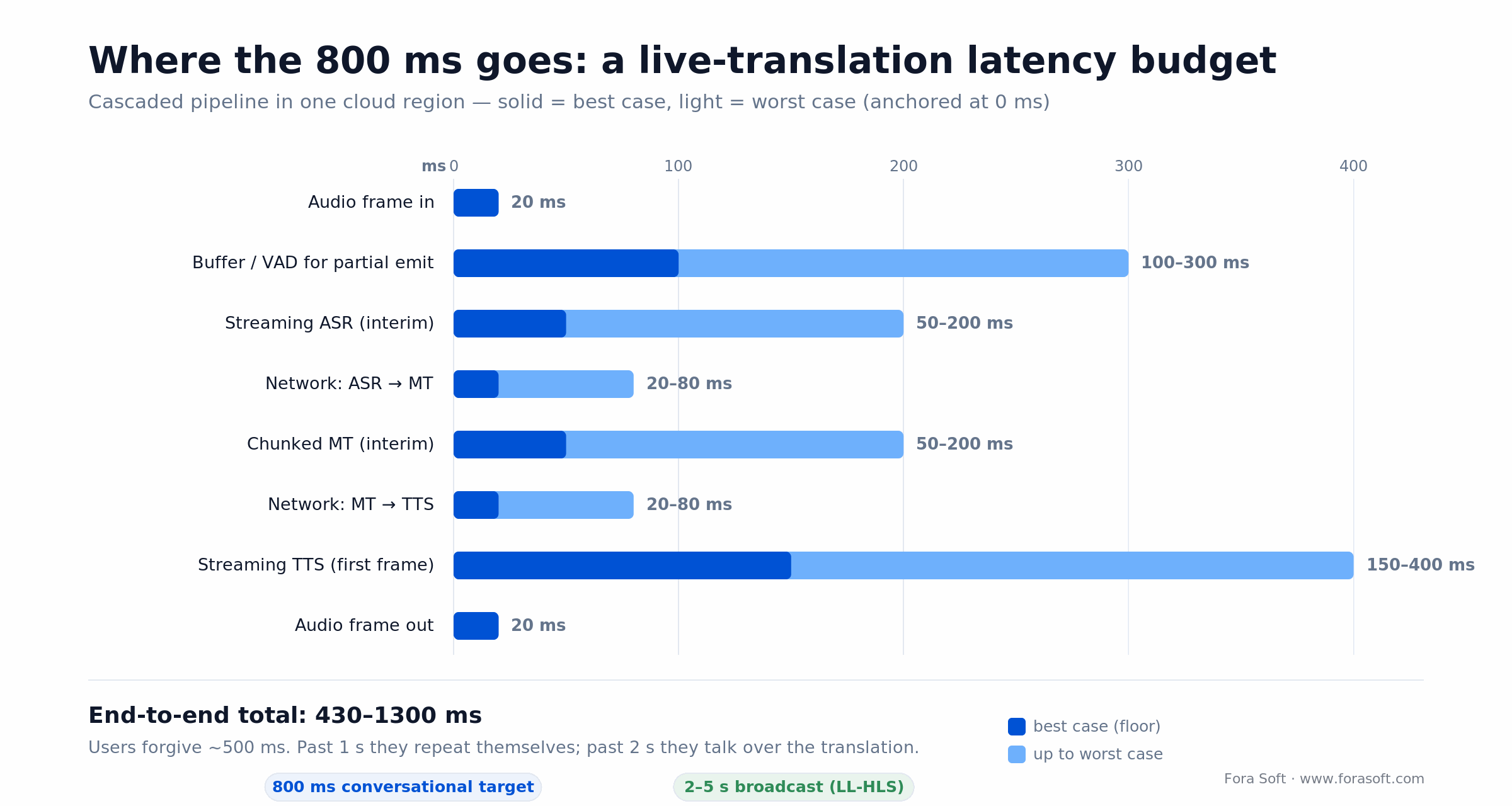
Figure 3. The latency budget — solid bars are the floor, light bars the worst case, anchored at 0 ms.
What actually hurts. Waiting for full utterance end on ASR (adds 200–500 ms), re-translating the whole sentence on every interim (wastes tokens and adds 100–200 ms), and cross-region hops between ASR, MT and TTS endpoints (can add 100 ms each).
Where the wins are. Co-locate ASR + MT + TTS in the same cloud region. Emit partial translations the moment ASR confidence > 0.7. Start TTS synthesis on the first translated chunk, not the final one. Use INT8 or 4-bit quantized models on self-hosted Whisper / M4T if you run on GPU.
Quality metrics: WER, COMET, MOS
Three numbers cover the pipeline end-to-end. Ship all three on the dashboard.
Word Error Rate (WER), ASR quality. Hold < 5% for native speakers, < 10% for accented speech, < 15% for code-mixed or noisy audio. Above 15% and the translation hallucinates even when MT is perfect.
COMET, MT quality. BLEU is largely superseded; COMET (Unbabel’s COMET-22 / CometKiwi) correlates much better with human judgment. Target ≥ 0.75 for production; < 0.60 means escalate to human review or fall back to a higher-cost MT tier. LLM-based MT hallucinates occasionally. Sample-score 1–2% of traffic continuously.
Mean Opinion Score (MOS), TTS and overall audio quality. Target blended MOS ≥ 4.0; < 3.5 is unshippable. For voice-cloned dubbing, also track speaker-similarity (cosine similarity of embeddings; target ≥ 0.85).
Composite production target. WER 4.5% + COMET 0.75 + MOS 4.2 matches the quality of the TransLinguist deployment at launch. Miss any one by more than 15% and the business-visible metric (completion rate, repeat-question rate) will show it within a week.
Choosing an ASR provider
Deepgram
Our default for low-latency commercial ASR. Flux (multilingual GA April 2026): median end-of-turn < 300 ms, ~150–250 ms time-to-first-token, ~$0.0077/min for real-time (Nova-3 drops to ~$0.0058/min). Strong on English; Spanish, French, German, Portuguese, Hindi all solid. Custom vocabularies, SOC 2, and a HIPAA BAA on the Enterprise tier.
AssemblyAI
Universal-3 Pro Streaming (shipped March 2026): P50 ~150 ms, P90 ~240 ms, ~8% WER on English streaming (~5.6% batch). Best accuracy in the streaming tier. The base Universal-Streaming model is $0.0025/min; Universal-3 Pro is ~$0.0075/min. Excellent English; weaker on low-resource languages.
Azure Speech-to-Text
~$0.017/min. 100+ languages, strong enterprise and compliance story (HIPAA BAA available, EU data residency). Live Interpreter (public preview since September 2025) bundles speech-to-speech across 76 input languages; Microsoft targets human-interpreter-level latency rather than publishing a millisecond figure, so benchmark it on your own audio.
Google Cloud Speech-to-Text
~$0.016/min real-time, with dynamic-batch discounts toward ~$0.004/min. 125+ languages across models (Chirp 3 is the current one), the widest coverage in this list. Good but occasionally bursty streaming latency; chunk carefully.
AWS Transcribe
$0.024/min streaming, dropping toward ~$0.0078/min at volume; medical tier higher. Picks up easily if you are already an AWS shop and want a single vendor story.
OpenAI Whisper / Faster-Whisper (self-hosted)
Open source, trained on 5M hours (1M weakly-labeled + 4M pseudo-labeled), 99 languages. Whisper-large-v3 matches commercial accuracy at a fraction of the cost once you own the GPU; Faster-Whisper (CTranslate2) gives ~4× speedup. OpenAI’s newer gpt-4o-transcribe (~$0.006/min) edges it on WER if you’d rather call an API. The winning path for privacy-regulated workloads where audio cannot leave the premises.
Reach for self-hosted Whisper when: audio can’t leave your infrastructure (HIPAA, defense, on-prem) or you need custom vocabulary the commercial APIs won’t take. You trade a managed SLA for GPU ops and full data control.
Choosing a machine translation provider
DeepL. The quality leader on European language pairs, with grammar-aware glossaries. API pricing is ~$25/M chars. DeepL Voice launched in November 2024; Voice-to-Voice and the Voice API followed in spring 2026, which matters if you want real-time speech in without wiring your own ASR.
Google Cloud Translation API. 100+ languages, fast, ~$20/M chars on classical NMT (or ~$10/M in + $10/M out on the newer Translation LLM tier). Glossary support. Our default when language coverage matters more than top-end fluency.
Azure Translator. ~$10/M chars — the cheapest of the majors — and the strongest option if you already use Azure Speech (same SDK, same latency guarantees).
AWS Translate. $15/M chars standard, more for adaptive/custom models. Thinner language catalogue than Google.
LLM translation (GPT-4o, Claude, Gemini). By 2026 frontier LLMs match or beat classical NMT on COMET for context-rich, idiomatic text, and they honor a “translate in a casual tone” system prompt. They still hallucinate occasionally on long context and cost is token-based with higher, less predictable latency. Sample-score with COMET; fall back to DeepL on low-confidence outputs.
Choosing a TTS / voice cloning provider
ElevenLabs. The market leader for expressive TTS and voice cloning. Instant clone from a 30-second sample; automatic dubbing now runs ~$0.24–0.60/min effective (billed per target language) — down roughly 5× from 2024. Eleven v3 covers 70+ languages; the Flash v2.5 model hits ~75 ms latency. Plans run $6/$22/$99/$299/$990 per month.
Azure Neural TTS. Excellent enterprise quality, 400+ voices, custom neural voice (CNV) available with consent workflow. Priced per character (~$16/M).
Google Cloud Text-to-Speech. Good default, integrates natively with Google Translation: $4/M standard, $16/M Neural2, $30/M for Chirp 3 HD voices that rival ElevenLabs on mainstream languages.
AWS Polly. $4/M standard, $16/M neural, $30/M generative. Solid but behind ElevenLabs on expressiveness. Pick it for price and AWS integration.
Meta’s open M4T family. Open-source speech-to-speech: the base M4T v2 model covers ~36 speech-output languages in a generic voice, while the separate expressive variant preserves prosody and emotion but only for ~6 languages. The right choice when you want a self-hosted baseline without ElevenLabs enterprise pricing — treat it as research infrastructure you maintain, not a turnkey API.
Need a provider selection sheet for your stack?
We benchmark ASR + MT + TTS combinations on your own recordings and hand you a choice with cost, latency and accuracy for your top languages.
Providers compared
| Provider | Stage | Streaming latency | Price | Best for |
|---|---|---|---|---|
| Deepgram | ASR | < 300 ms | ~$0.0077/min | Low-latency English, Spanish, French |
| AssemblyAI | ASR | P50 150 ms | $0.0025–0.0075/min | Highest streaming accuracy |
| Azure Speech | ASR + MT + TTS bundle | ASR sub-1 s; S2S n/a | $0.017/min | Enterprise, regulated, EU residency |
| Google Cloud | ASR / MT / TTS | ~650 ms ASR | $0.016–0.024/min ASR; $20/M chars MT | 125-language coverage |
| AWS | Transcribe + Translate + Polly | Moderate | $0.024/min + $15/M + $16/M | Existing AWS shops |
| DeepL | MT | < 200 ms | ~$25/M chars | European language quality |
| ElevenLabs | TTS + voice clone + dubbing | 200–500 ms TTFF | ~$0.24–0.60/min dubbed; $6–990/mo | Expressive voice, dubbing |
| Whisper (self) | ASR | GPU-dependent | Free + infra ($0.002–$0.006/min) | Privacy, on-prem, custom fine-tuning |
| Meta M4T v2 (self) | End-to-end S2ST | ~1 s streaming | Free + GPU infra | Open S2ST baseline, ~36 speech-out |
Plumbing translation into WebRTC
WebRTC gives you ~300 ms end-to-end latency for the underlying media. Add the translation pipeline and you are at ~1 s, which is still under the conversational threshold. The pattern we ship on every WebRTC project:
1. Fork audio at the SFU. LiveKit, mediasoup, Janus and Jitsi all let you subscribe to a publisher’s audio track as a raw RTP or Opus feed. Route that feed to the translation worker.
2. Run ASR + MT + TTS as a headless service. Node.js, Go or Python. One worker per active speaker. Autoscale horizontally. The workload is embarrassingly parallel.
3. Publish the translated audio as a second track. Either as a new SFU participant (“Interpreter for Speaker A → Spanish”) or as an additional SDP m-line on the same peer connection with a language code in MSID. Viewers subscribe to the language they want.
4. Send captions over the data channel. Low-jitter, ordered delivery, no extra media stream needed. Client overlays them with CSS. VTT time codes keep them in sync with the translated audio. Add a ~100–200 ms smoothing buffer so interim-hypothesis corrections don’t make captions flicker — the one detail most builder guides skip.
5. Mute the original audio per listener. Each viewer picks “original + captions”, “translated audio + captions”, or “translated audio only”. This is a client-side mixer choice. The SFU delivers both.
Plumbing translation into HLS / LL-HLS
For broadcast-style streams (sports, conferences, concerts, Worldcast-class live events), HLS dominates. Latency is 2–5 s on LL-HLS, 5–30 s on vanilla HLS, so the translation budget is more generous but CDN-wide synchronization is harder.
Caption track: segmented WebVTT. Add a #EXT-X-MEDIA TYPE=SUBTITLES to the master playlist, one per language. Segment WebVTT every 4–6 s to match the media segment cadence. Most players (hls.js, Shaka) handle language switching natively.
Dubbed audio: additional audio renditions. Add a #EXT-X-MEDIA TYPE=AUDIO per language. The client picks one at playback. Re-encode the translated audio into AAC at the same segment boundaries as the video so lip-sync holds within ±200 ms.
Keep CMAF atomic. For LL-HLS, ensure every chunk (ASR input, MT output, TTS output, video segment) lands on the same CMAF boundary. Otherwise subtitle drift accumulates and viewers complain about lip-sync two hours into the event.
Subtitles vs dubbed voice: when to use which
Subtitles win on: cost (5–10× cheaper), language coverage (captions to 100+ languages, dubbing quality drops past 40), accessibility (deaf and hard-of-hearing users need captions anyway), and multilingual environments where viewers watch the original video while reading translated text.
Dubbed voice wins on: engagement (subtitled content tends to lose watch-time versus dubbed in many locales), accessibility for low-literacy viewers, eyes-off scenarios (driving, cooking, sports watched from a distance), and the “feels premium” quality bar for paid content.
Ship both. Let viewers choose. Captions cost about $0.02–0.03 per speaker-minute; dubbed audio adds roughly $0.02/minute for neural TTS or $0.24–0.60/minute for voice cloning. In a typical viewer mix (captions watched by 60–70%, dubbed audio 20–30%, original 10%), the blended cost stays manageable.
Reach for dubbed audio when: the content is watched eyes-off (driving, cooking, sports from across the room) or your retention data shows subtitles losing viewers in a target locale. Otherwise captions win on cost and coverage.
Mini case: TransLinguist, a 75-language live interpretation platform
Situation. TransLinguist wanted one platform that offered both AI translation (cheap, always on) and a marketplace of certified human interpreters (premium, on-demand) through the same UI, for live conferences and public-sector meetings. Off-the-shelf integrations covered a handful of languages; none supported the AI-plus-human hybrid model or low-latency WebRTC delivery.
What we built. A MediaSoup WebRTC SFU with a multi-provider ASR router (Deepgram, Google Speech-to-Text and Speechmatics), machine translation with per-pair quality scoring, and Google TTS for synthesized voice. Per-listener language selection let each viewer pick a language track. A human-interpreter seat was wired in over WebRTC audio routing with a job-booking flow, plus session transcription, automatic subtitles, a sign-language UI, and a speaker-slowdown indicator. FFmpeg and RabbitMQ handled media and queues; the front end is Next.js and React.
Outcome. AI speech-to-speech translation in 16+ languages, closed captioning in 22, and a marketplace of 30,000+ certified interpreters across 75+ languages. TransLinguist won the NHS (NOE CPC) National Framework for Language Services across the UK — NHS organizations, councils, schools, police, and fire services. The platform reports 80% lower interpreting costs, 50% overall cost savings, 53% higher attendance, and 2× ROI in the first two years, and has been featured twice in Slator as a disruptive player in remote interpreting. Read the companion deep-dive on adding a real-time translator to a WebRTC video call.
If you want a similar three-month scope against your own stack, book a 30-minute call and bring a recording.
Cost math: what one hour of multilingual stream actually costs
Four line items per target language per hour of speech. Plug your own pricing sheet into the same template.
1 hour of active speech = 60 min = ~9,000 words = ~55,000 chars
Translated captions (ASR + MT):
ASR: 60 min × $0.008/min = $0.48
MT: 55,000 chars × $20/M = $1.10 (Azure $10/M halves this)
--------
~$1.10–1.60 / hour / language
Dubbed audio (ASR + MT + neural TTS):
ASR: $0.48
MT: $1.10
TTS: 55,000 chars × $16/M = $0.88
--------
~$2.00–2.50 / hour / language
Voice-cloned dubbed audio (ElevenLabs Dubbing, 2026):
~$0.24–0.60/min × 60 = $14–36 / hour / language
Live interpreter fallback (human):
~$70–150 / hour / language
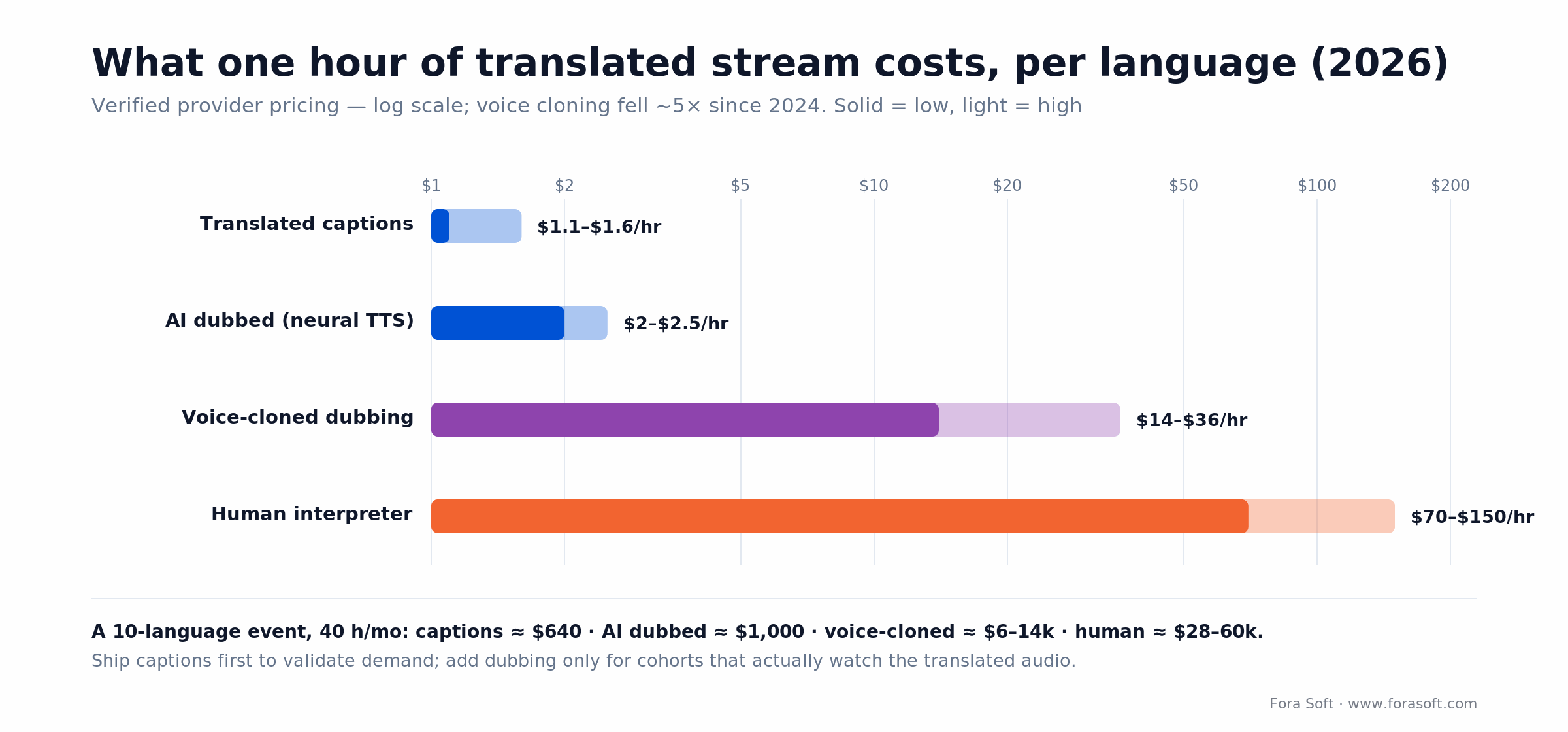
Figure 4. Cost per hour per language — log scale; voice cloning fell ~5× since 2024.
For a 10-language event with 40 hours of speech per month, captions cost ~$640 and AI dubbed audio ~$1,000. Voice-cloned dubbing lands around $6,000–14,000 — still a premium, but roughly 5× cheaper than it was in 2024, which is why voice cloning is finally viable for live tiers, not just on-demand content.
A decision framework: pick your stack in five questions
1. Captions or dubbed audio? Start with captions unless the product is content-watching with measurable retention gains from dubbing. Most conferencing and e-learning products never need full dubbing.
2. How tight is the latency budget? < 1 s conversational means cascaded with streaming ASR. 2–5 s broadcast lets you use batch ASR, wider MT context, and higher-quality TTS. Match the budget before you pick the providers.
3. How many language pairs matter for launch? Fewer than 5 → consider Azure Live Interpreter or a self-hosted M4T deployment. 5–25 → cascaded with DeepL + ElevenLabs. 25+ → cascaded with Google or Azure (coverage wins over polish).
4. Is the data regulated? HIPAA, GDPR or SOC 2 in scope → on-device Whisper or Azure EU residency + signed BAA. No regulation → pick on latency and cost. This single question vetoes half the commercial providers for healthcare.
5. WebRTC, HLS or both? WebRTC-only → SFU audio fork + per-listener language selection. HLS-only → additional audio renditions + segmented WebVTT. Both (ingest WebRTC, distribute HLS) → hybrid with CMAF timestamp alignment. The distribution protocol drives half the architecture.
Five pitfalls that will break your translation pipeline
1. Translating interim ASR outputs without confidence thresholds. Retranslating every 200 ms wastes MT spend and emits caption flicker. Gate on ASR confidence > 0.7 and only retranslate when the prefix of the utterance has changed.
2. No domain glossary. Generic MT butchers product names, medical codes, legal terminology. Expose a glossary-upload flow per tenant from day one. Typical impact: 3–5× WER drop on domain vocabulary.
3. Mixing cross-region endpoints. US-hosted ASR + EU-hosted MT + US-hosted TTS adds 100–200 ms of pure network latency on every utterance. Pin all three to the same region, then mirror to others if needed.
4. Ignoring speaker overlap. Two people talk over each other. Your ASR emits jumbled interim text. MT hallucinates. TTS speaks gibberish. Run speaker diarization on the SFU side and route each speaker to a separate pipeline.
5. No fallback when providers fail. ASR APIs return 5xx. MT models rate-limit. TTS services hit regional outages. Build a dual-provider router with < 500 ms fail-over and log every fallback as a metric. Users should never see “translation service unavailable”.
Ready to scope a TransLinguist-class multilingual stream?
We’ve shipped this playbook on WebRTC, HLS, and hybrid stacks for conferencing, e-learning, and broadcast products. Let’s price yours.
Privacy, HIPAA, GDPR for cross-border audio
HIPAA. In the U.S. healthcare context, audio often contains PHI. You need a signed BAA with every provider in the chain. Azure and AWS offer BAAs; several newer ASR vendors do not. On-device ASR with Whisper solves the problem end-to-end but costs GPU cycles.
GDPR. EU personal data must stay in the EU or be covered by SCCs + a DPA. Azure DE and AWS EU-West regions make this straightforward. The breach exposure is voice biometrics, which are non-recoverable. Fines run up to €20 M or 4% of global revenue.
Consent. For translation you are processing voice. Add an explicit consent banner before the first ASR call. Record consent timestamps and provider tags per session so you can prove compliance under audit.
Data-retention defaults. Ship with zero retention on audio inside the ASR/MT/TTS providers (most enterprise tiers support it) and a 30-day retention ceiling on your own transcription storage unless the customer opts in for longer.
Voice cloning carries new legal weight. Resynthesizing a speaker’s voice is biometric processing and, increasingly, a publicity-rights question. US state laws (Tennessee’s ELVIS Act, Illinois BIPA, California) and the EU AI Act’s transparency duty require disclosing AI-generated or cloned voice and getting explicit, logged consent. Recording-consent rules also vary (one-party vs two-party states). Bake consent and an “AI voice” disclosure into the enrollment flow, not the legal review two weeks before launch.
KPIs to report to the business
Quality KPIs. WER p50 per language, COMET p50 per pair, blended MOS per output track. Target WER < 8%, COMET ≥ 0.75, MOS ≥ 4.0. Any below-target cell on the matrix is a queued remediation task.
Business KPIs. Adoption rate (% of sessions that turn on translation), viewer minutes on translated tracks vs original, repeat-question rate (proxy for translation confusion), NPS by language cohort.
Reliability KPIs. End-to-end p95 latency per pipeline stage, provider availability per language, fallback-trigger rate. Alert on any p95 > target for 5 minutes continuously.
When NOT to add live translation
Your audience is overwhelmingly single-language. If 95% of viewers share one language, translation is a distraction. Localize the UI and post-event recordings instead, which cost 10× less.
The content is legal, medical, or financial advice. MT hallucinations in these domains carry real liability. Use translated captions with a clear “machine translation” disclaimer or route to human interpreters.
Your latency budget is under 500 ms. True interactive gaming, co-located broadcast. Cascaded translation cannot hit 500 ms today.
The data is pre-PMF. Before product-market fit, translation is noise. Ship the core product in one language first; add translation when repeat cohorts are asking for it.
FAQ
What is realistic end-to-end latency for live AI translation in 2026?
On a well-tuned cascaded pipeline in a single cloud region, 800 ms–1.5 s for translated captions and 1–2 s for dubbed audio on mainstream pairs. End-to-end S2ST (Google Pixel 10, Meta’s M4T family, Azure Live Interpreter) reaches ~1–2 s with voice preservation, but only for a handful of language pairs.
Which ASR engine is best for live streams?
Deepgram Flux wins on latency (< 300 ms end-of-turn), AssemblyAI Universal-3 Pro wins on accuracy (~8% streaming WER), and Whisper large-v3 self-hosted wins on privacy and unit cost if you already run GPUs. For regulated healthcare, Azure Speech with a signed BAA is the safe default.
How much does live AI translation cost per hour?
Translated captions: ~$1.10–1.60/hour/language. AI dubbed audio: ~$2–2.50/hour/language with neural TTS. Voice-cloned dubbing (ElevenLabs): ~$14–36/hour/language in 2026. Live human interpretation: $70–150/hour/language. Most products launch on captions for cost, and upsell dubbed audio.
Can I keep the speaker’s original voice in the translated output?
Yes, through voice cloning. Either end-to-end S2ST models (Meta’s open M4T family, Google Pixel 10 on-device) or cascaded pipelines with ElevenLabs Instant Voice Clone. Expect a 30-second enrollment sample and $0.24–0.60 per minute of dubbed output. Handle consent carefully. Voice is biometric data under GDPR.
How do I integrate translation into an existing WebRTC SFU?
Fork each publisher’s audio track as raw RTP or Opus, route it to a per-speaker translation worker running ASR + MT + TTS, publish the translated audio back to the SFU as a new participant or an additional SDP m-line, and deliver captions over the data channel. LiveKit, mediasoup, Janus and Jitsi all support this pattern out of the box.
How do I measure translation quality in production?
Track three numbers: WER on ASR (target < 10%), COMET on MT (target ≥ 0.75), MOS on TTS (target ≥ 4.0). Sample 1–2% of traffic continuously for automatic scoring, and run a weekly human review on a stratified sample of 50–200 utterances per language. Alert on any metric sliding more than 10% week over week.
Is it legal to process customer audio through third-party AI services?
It depends on the regulator and the data. In the U.S., PHI requires a signed BAA with every provider. In the EU, personal data requires a DPA and, for reliable compliance, regional data residency. Always expose an explicit consent banner before processing starts, log consent, and offer on-device ASR for users who opt out of cloud processing.
How long does it take to build a production translation pipeline?
With AI-assisted engineering we typically scope 3–6 weeks for translated captions on an existing WebRTC or HLS stack, and 8–12 weeks for full dubbed audio with voice cloning, glossaries, and compliance controls. TransLinguist (AI speech-to-speech in 16+ languages, captions in 22, a 30,000-interpreter marketplace) took ~12 weeks from kickoff to launch.
What to read next
WebRTC
Video call with a real-time translator: the WebRTC integration guide
Companion deep-dive on how TransLinguist plumbed translation into a call stack.
AI features
Enhancing video calls with AI language processing
The wider palette: summarization, sentiment, action-item extraction on calls.
Latency
How to minimize latency to under 1 second at mass scale
WebRTC / LL-HLS / MoQ. The transport layer your translation sits on top of.
Quality testing
How to test WebRTC stream quality in 2026
Metrics, thresholds and tools for the media layer feeding your translator.
Cost model
Server cost for a video platform in 2026
The underlying stream costs before translation is added.
Ready to go multilingual?
Real-time video translation in 2026 is a three-stage cascaded pipeline (ASR, MT, TTS) plumbed into a WebRTC or HLS distribution layer. Hold the quality bar with WER, COMET and MOS. Hold the latency bar at 800 ms for conversational and 2–5 s for broadcast. Ship captions first, validate demand, add dubbing on the cohorts that actually watch the translated audio.
If that sounds like the right playbook for your product, our team has already built it at scale — AI speech-to-speech in 16+ languages, captions in 22, and a 30,000-interpreter marketplace on TransLinguist. Our Agent Engineering pipeline typically delivers a production translated-caption launch in 3–6 weeks on an existing stack.
Want live AI translation on your stream by next quarter?
Fixed scope, fixed timeline. ASR + MT + TTS + WebRTC/HLS plumbing + QA dashboards. Bring a recording, leave with a plan.








