



Key takeaways
• AI video anomaly detection earns its keep on false-alarm reduction, not feature lists. Modern stacks cut alerts by 30–65% versus rule-based motion, which is the difference between an operator trusting the system and ignoring it.
• The 2026 production defaults are YOLO26 and YOLO11, with YOLOv12’s attention design reserved for crowded scenes. Top YOLO detectors land near 55% mAP@50–95 on COCO (about 70% mAP@50); site-fine-tuned single-class models climb past 90%. Add an unsupervised autoencoder head to catch novel anomalies without labels.
• Edge inference beats cloud at <100 ms. NVIDIA Jetson Orin (275 TOPS) and Hailo-8 (26 TOPS @ 3W) deliver 18–26 ms image latency — non-negotiable for forklift collision, fall detection, and crowd-rush alerts.
• Real ROI is documented across verticals. 50% retail shrink reduction (3DiVi, 183 stores), 93% incident drop on forklifts (OneTrack), 95%+ PPE detection accuracy in factories, F1=0.92 on hospital fall detection (LookDeep across 11 hospitals).
• The EU AI Act and U.S. biometric laws change the build plan. Pose-based detection (PPE, fall, crowd) is high-risk but tractable; facial recognition triggers BIPA, NYC Local Law 144, and GDPR friction — design accordingly.
Why Fora Soft wrote this playbook
Since 2005 we have shipped 250+ video- and AI-first products, and AI video anomaly detection sits exactly where our two strongest practices meet: real-time multimedia engineering and machine-learning integration. We have built the streaming spine, the camera ingest, the model serving, and the operator UI — and we have done it for U.S. law enforcement, medical-education facilities, child-advocacy centers, and large industrial operators.
Our most cited reference is V.A.L.T., a video-surveillance SaaS used by 770+ U.S. organisations and 50,000+ active users for HIPAA-compliant medical simulation, child-advocacy interview recording and law-enforcement evidence management. It runs Full HD multi-camera live streams (9 cameras per screen) with PTZ control, RBAC, encrypted recording and exportable PDF/CD evidence packs — everything an AI anomaly layer plugs into.
The numbers, costs and benchmarks below come from public 2024–2026 sources (Grand View Research, Mordor Intelligence, NVIDIA Developer, Hailo, Ultralytics, NIST FRVT, MOT Challenge, IEEE/Nature, IAPP on the EU AI Act). The product opinions come from shipping this category.
Need a second opinion on your AI video stack?
Send us your camera count, target anomalies and current platform — we’ll come back with a 1-page architecture note in 48 hours: model, edge box, alert pipeline, realistic latency.
What AI video anomaly detection actually means
An AI video anomaly detection system continuously analyses camera feeds and raises an alert only when something deviates from learned normality. Three properties separate it from a classical motion alarm: it learns what “normal” looks like from data, it produces structured metadata about what it sees (person on a forklift, missing hard hat, patient out of bed), and it ignores the trees, shadows and weather that drown out rule-based systems.
In practice an AI anomaly stack is a pipeline of three or four models stacked behind a streaming layer. An object detector (typically YOLO26, YOLO11 or RT-DETR) labels people, vehicles and objects per frame; a tracker (ByteTrack, BoT-SORT, Re-ID) keeps an identity across frames; an action or pose model (X3D, SlowFast, MMPose, MediaPipe) reads behaviour; and an unsupervised anomaly head (autoencoder, MIL or transformer-based) flags “weird” sequences without explicit labels. Output: an event with bounding box, class, confidence, timestamp, camera ID, and an alert routed to the operator UI.
That metadata is what powers downstream value: forensic search (“show me every person without a vest near dock 3 last Friday”), KPI dashboards, integration into VMS like modern VMS software, and downstream automation (slow the conveyor, lock the gate, page the duty nurse). For the model math itself, see our companion pieces on anomaly detection algorithms and anomaly detection models for video surveillance, plus our video surveillance learning hub.

Figure 1. The six-layer AI video anomaly detection stack. The anomaly head and alert pipeline (layers 4 and 5) are where most projects fail.
Why now: the 2026 case for AI over rule-based motion
Three structural shifts pushed AI video anomaly detection from “experimental” to “mainstream procurement category” in 2025–2026.
1. Alert fatigue is now a budget line. U.S. police forces field 36 million alarm calls per year with >90% false-positive rate; security operations teams generate 9,854 false positives per week (Ponemon 2024); Dallas alone burns $11.6M/year on false-alarm dispatch. Rule-based motion is the cause; AI filtering is the proven fix — vendor data shows 30–65% reduction in false alerts.
2. Edge silicon got 10× better and 5× cheaper. NVIDIA Jetson Orin AGX delivers 275 TOPS at <60 ms glass-to-glass on 4K, Hailo-8 hits 26 TOPS at 3W, Google Coral TPU is $40 for 4 TOPS. A real-time YOLOv8 multi-camera deployment that needed a workstation in 2022 fits in a fanless box in 2026.
3. Models open-sourced faster than VMS vendors could ship. Ultralytics shipped YOLO26 in January 2026 (NMS-free, edge-first) on top of YOLO11 and the attention-centric YOLOv12. Top variants reach about 55% mAP@50–95 across COCO’s 80 classes; on one fine-tuned class (a single PPE item, one intrusion type) production teams report precision and recall above 90%. Buyers now have a credible build-your-own path next to Verkada, Genetec, Avigilon and Milestone.
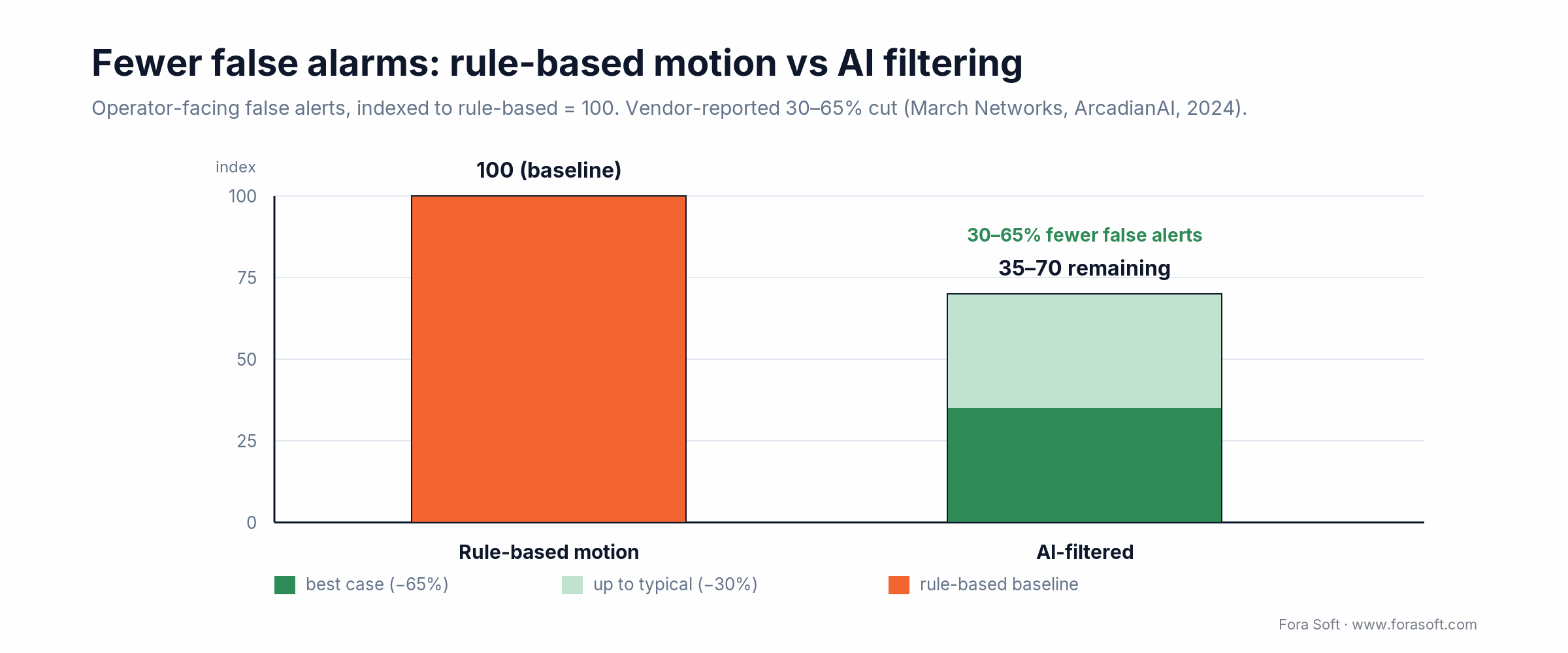
Figure 2. Operator-facing false alarms, rule-based motion versus AI filtering. Vendors report a 30–65% cut (March Networks, ArcadianAI, 2024).
The 2026 market in numbers
The figures below come from Grand View Research, Mordor Intelligence, MOT Challenge benchmarks, NVIDIA Jetson developer benchmarks, and case data published by 3DiVi, OneTrack, LookDeep Health and Spot AI. They are useful as procurement anchors, not gospel — vertical and region change them by 30–50%.
| Metric | Figure | Year | Source |
|---|---|---|---|
| AI video analytics market | $6.19B (22.7% CAGR) | 2026 base | Mordor Intelligence |
| Video analytics broad market | $15B → $37.8B by 2030 | 2026–2030 | Grand View Research |
| Best YOLO mAP@50–95 (COCO val) | ~55% (YOLOv12x, 640px) | 2025 | Ultralytics |
| Edge latency, Jetson Orin AGX | 18–26 ms (4K, 100 FPS) | 2025 | NVIDIA Developer |
| False-alarm reduction with AI | 30–65% | 2024 | March Networks, ArcadianAI |
| ROI within 12 months | 86% of organisations | 2024 | Omdia |
| U.S. shoplifting surge | +24% (H1 2024) | 2024 | National Retail Federation |
Retail: theft, queue and shrinkage
Retail is where AI anomaly detection has the cleanest financial story. Three documented deployments in 2024:
3DiVi (183 stores, 32 cities). 50% reduction in theft-related shrinkage within 12 months by combining pose estimation with item tracking on existing IP cameras. The system flags “sweethearting” at registers, concealment in changing rooms, and tag-removal motions in the aisle.
Agrex.ai (1,800+ stores). 14–18% conversion lift inside 180 days using queue analytics and dwell-time heat-maps to redeploy floor staff in real time. The same camera feeds drive both shrinkage reduction and conversion — one pipeline, two P&L lines.
Spot AI in auto services. 8× ROI on automotive aftermarket deployments — 4× membership rates, +10% revenue — through a forensic-search-first UX layered over existing cameras.
The technical pattern is consistent: pose estimation plus multi-frame tracking plus Re-ID, not raw object detection. Self-checkout fraud, in particular, requires a behaviour model — a single frame can’t tell “scanning” from “skipping the scan.”
Safety-critical verticals
Four verticals where the anomaly is a safety event, not a sale: manufacturing, healthcare, logistics and smart cities. The pattern repeats: pose and behaviour models on the cameras you already own. Only the alert and the stakes change.
Manufacturing and workplace safety
PPE detection is the highest-volume manufacturing use case, and the one with the most boring, dependable accuracy story. Production deployments routinely report >95% accuracy on hard hats, vests, gloves and fall-arrest gear across dust, low-light and crowded scenes; vendors like visionify.ai and viAct.ai cover 15+ PPE categories per facility on standard IP cameras.
Adjacent use cases ride the same models: line-stoppage detection, tool-presence checks, hand-in-machine zone violations, manufacturing defect detection. YOLOv8m fine-tuned on factory data gives precision above 0.90 on most defect classes; the harder problem is dataset labelling (3–6 months lead time) and drift management as products and lines change.
Spot AI has published a 40% workplace-injury reduction on industrial accounts via proactive safety identification. The workflow is: detect the unsafe behaviour, audio alert on-site, log to a dashboard, escalate if repeated — not a punishment system, an early-warning system.
Reach for AI PPE detection when: your insurance carrier is asking for safety analytics, OSHA has flagged your facility, or PPE-related incidents already cost more than $50K/year — payback is typically < 9 months.
Healthcare: fall detection and elopement
Healthcare AI video has a clear best-practice pattern in 2026: pose-based detection only, no facial recognition, on-prem inference. That posture sidesteps the bulk of HIPAA, GDPR and BIPA friction while still delivering the clinical signal.
LookDeep Health, deployed across 11 hospitals in three U.S. states, ran 1,000+ days of inference covering 300+ high-risk patients with macro F1 of 0.92 on object detection, 0.98 on patient-role classification, and 0.82 ± 0.15 on “patient alone” tracking accuracy. The Malaysia 2024 SMART AI Patient Sitter pilot covered 30 stroke patients with motion-sensing alerts.
The same architecture extends to elopement on dementia wards, post-op early ambulation, and seizure monitoring. We have shipped a HIPAA-compliant medical recording subset of this pattern on V.A.L.T. (medical simulation labs and supervised PhD consultations) with role-based access control, encrypted streams and per-student permissions; layering an AI anomaly head on top is an evolutionary step, not a rewrite.
Logistics and warehouse: forklift and intrusion
The headline number for warehouses is OneTrack’s 93% incident reduction across forklift deployments. The pipeline detects pedestrian intrusion into forklift paths and blind-spot collisions, then triggers multi-level voice and visual alerts for the operator. The same AI also drives dock-door occupancy analytics, perimeter intrusion detection, and trailer-arrival tracking.
In a typical 50-camera distribution centre, the safety-critical alerts (intrusion, near-miss, missing PPE) run on edge boxes for sub-100 ms latency. Forensic, dwell-time and dock-throughput analytics run in the cloud where minutes of latency are fine.
Smart city and crowd safety
Smart-city AI video tackles three classes of anomaly: crowd density and turbulence, abandoned-object detection, and traffic incidents. Crowd density above ~5–6 people per square metre triggers an early-warning workflow (operators get heat-maps, command centres get push alerts) — deployed at scale in Agra, Hyderabad and Mumbai under India’s Smart Cities Mission.
Traffic-side anomalies (helmet-less riders, wrong-way driving, stalled vehicles) typically run on YOLO11 fine-tuned on local traffic data, with a Kalman-tracker for vehicle motion. Throughput on a Jetson Orin handles 6–8 streams comfortably; cloud back-office indexing keeps forensic footage searchable. Our briefings on AI-powered IP cameras, real-time video analytics, and video telematics for fleets go deeper on the architecture choices.
Drowning in false alarms?
Send us your camera feed sample and a week of alert logs. We’ll quantify the false-positive rate, propose an AI filtering layer, and project the operator-time savings — in 48 hours, no slides.
How an AI video anomaly stack actually works
A production stack has six layers. Skip any one of them and the system either misses anomalies or buries the operator in noise.
1. Ingest. RTSP/RTMP from IP cameras (Axis, Hanwha, Avigilon, Hikvision/Dahua where compliance allows) into a hardware-accelerated pipeline (NVIDIA DeepStream, FFmpeg + NVENC, GStreamer). 4K is fine but rarely needed beyond 1080p for anomaly detection.
2. Object detection and tracking. YOLO26, YOLO11 or RT-DETR for class detection; ByteTrack or BoT-SORT for cross-frame identity; Re-ID for camera-to-camera persistence. On COCO the best of these sit near 55% mAP@50–95; a model fine-tuned on your two or three classes lands much higher.
3. Pose / action / activity model. X3D or SlowFast for action classes, MMPose / MediaPipe for pose keypoints. This is what reads “person fell”, “hands inside guard”, “item concealed.”
4. Anomaly head. Either a supervised classifier (when you have labels) or an unsupervised autoencoder / MIL transformer (when you don’t). Unsupervised heads catch novel anomalies but produce more false positives — pair with a rule-based filter.
5. Alert pipeline. Severity scoring, deduplication, geofencing, schedule-aware suppression (the loading dock at 0700 is normal, at 0200 it isn’t), then route to operator UI, SMS, Slack/Teams, on-site speaker, or VMS bookmark.
6. Storage and forensic search. Indexed metadata in a search store (Elasticsearch, OpenSearch) plus video on object storage. This is what turns the system from an alarm into a tool.
Models in 2026: YOLO, transformers, autoencoders
| Model family | Best for | Accuracy | Edge fit |
|---|---|---|---|
| YOLO26 / YOLO11 / YOLOv12 | Real-time object detection | mAP@50–95 ~55% (COCO) | Excellent on Jetson, Hailo |
| RT-DETR | Crowded scenes, occlusion | ≈ parity at matched latency | Good on Jetson Orin |
| SlowFast / X3D | Action recognition | ~80% top-1 (Kinetics) | Heavier; cloud or AGX |
| VideoMAE / TimeSformer | Long-term temporal anomaly | SOTA on UCF-Crime | Cloud only; latency > edge target |
| MMPose / MediaPipe | Pose-based safety, fall | F1 0.90+ in pilots | Excellent on edge |
| Autoencoder / MIL | Unsupervised anomaly | High recall, lower precision | Pair with filters |
Defaults we ship with: YOLO26 or YOLO11 for objects, BoT-SORT for tracking, MMPose for pose-driven anomalies, and a small autoencoder head for novel-anomaly recall. Heavier transformer models go in the cloud where latency is acceptable. Datasets we lean on for evaluation: MOT Challenge, AVA, UCF-Crime, ShanghaiTech, UBnormal and the 2024 NeurIPS MSAD multi-scenario benchmark.
Edge vs cloud: where the inference runs
Edge inference (NVIDIA Jetson Orin, Hailo-8/15, Coral TPU, Ambarella CV5, Axis ARTPEC) is the right answer when latency, bandwidth or privacy matter. Cloud inference makes sense when the camera count is large, workloads are heterogeneous, or forensic search is the dominant feature. The right answer for most 2026 buyers is hybrid: edge for the safety-critical anomalies, cloud for the rest.

Figure 3. Glass-to-glass latency by path against the 100 ms safety budget for collision and fall detection.
| Pick edge if… | Pick cloud if… |
|---|---|
| <100 ms latency required (collision, fall) | 500+ heterogeneous cameras |
| Bandwidth-constrained (rural, 4K) | Forensic search across full fleet |
| Privacy-sensitive (on-prem only) | Seasonal scaling (retail holidays) |
| Predictable workload | Centralised compliance reporting |
Reach for hybrid edge+cloud when: you have safety-critical anomalies (sub-100 ms) AND a need for centralised forensic search across 50+ cameras — that combination defeats both pure-edge and pure-cloud designs.
Commercial platforms vs build-your-own
Three buying paths in 2026.
Cloud-native VSaaS (Verkada, Spot AI, Solink, Rhombus, Coram, Lumana). Per-camera per-month pricing, AI built into the firmware, fastest deployment. Workflow ceiling is the vendor’s API. Best for retail chains and SMB sites that want to ship in days.
Open-ecosystem VMS plus AI plug-ins (Milestone XProtect with BriefCam / IronYun, Genetec Security Center, Avigilon Unity). On-prem-friendly, 1,000+ third-party analytics in Milestone’s case, lower 5-year TCO at scale. Best for enterprises with existing IP-camera fleets.
Build-your-own (YOLO + DeepStream + custom pipeline). Maximum control, zero licensing for the model layer, custom anomaly logic. Tradeoff: 6–18 months of integration work and a permanent ML/DevOps team. Best for operators whose anomaly definition is itself the product (sport-broadcast pipelines, forensic-video providers, regulated medical workflows).

Figure 4. Three buying paths for AI video anomaly detection, scored on deploy speed, control, five-year TCO and best fit.
Reach for build-your-own when: your anomaly definition is proprietary, your camera count justifies the integration cost (50+), and you can keep at least one ML engineer on call for drift management.
Our deeper take on the platform layer is in the brief on video surveillance management systems and the inventory of features modern VMS software ships in 2026. If surveillance is your exact use case, our AI anomaly detection in surveillance playbook goes deeper on architecture, cost and compliance.
What it costs to build and operate
Two cost questions matter: per-camera operating cost and one-off engineering cost. Public 2025–2026 figures cluster around the ranges below; we keep our quotes inside these bounds and use AI-assisted engineering to compress mid-range builds further when the workstreams are suitable.
| Item | Range | Notes |
|---|---|---|
| VSaaS per camera / month | $5–$18 | Spot AI / Verkada / Solink range |
| Edge box (Jetson Orin) | $300–$600 | 6–8 streams comfortably |
| Hailo-8 / Coral | $40–$300 | For lower-throughput sites |
| Custom MVP (single use case) | 4–8 weeks | Off-the-shelf YOLO + minimal UI |
| Production-ready system | 4–6 months | Dataset, fine-tune, integration, QA |
| Scale to 100+ cameras | +2–3 months | Infra, failover, observability |
| Image labelling | $0.50–$5 / image | Sama, Label Your Data, Encord |
| Quarterly retrain | 10–30% of dev cost / yr | Drift, seasonality, new SKUs |
Hidden cost most procurement decks miss: bandwidth. 4K cloud egress can land at $1–5 per camera per month before AI fees; for fleets above ~100 cameras the on-prem Jetson plus local storage path beats pure cloud once egress is in the model.
Mini case: V.A.L.T. video surveillance for 770+ U.S. organisations
Situation. Law-enforcement, child-advocacy and medical-education clients needed a single video-surveillance platform that could record interrogations, supervise medical PhD consultations and capture forensic interviews of children — with HIPAA-compliant access control, encrypted streams, full-HD multi-camera live monitoring and CD/DVD evidence export.
What we built. V.A.L.T. — a video-surveillance SaaS that streams up to 9 IP cameras (Axis-class) on a single screen with PTZ control, two-way audio, encrypted recording with instant playback and clipping, role-based access control with LDAP, automated recurring scheduling, annotation/marker workflows, exportable PDF reports, admin analytics and CD/DVD evidence burning. The architecture is built to add an AI anomaly head per use-case — intrusion alerts for police interview rooms, fall detection in medical simulation labs, and forensic search for advocacy interviews — without re-architecting the streaming spine.
Outcome. 770+ client organisations across the U.S., 50,000+ active users, used by detectives, child-advocacy investigators and medical educators. The same engineers ship our AI anomaly-detection work, which is why our integrations land faster than from a pure-CV agency. Want a similar assessment for your camera fleet?
Privacy and the EU AI Act, BIPA, GDPR
Regulators caught up with AI video in 2024–2025. The EU AI Act entered into force in August 2024, and its general-purpose-AI duties began in August 2025. High-risk obligations were slated for August 2026–2027, but the Digital Omnibus approved by the European Parliament in June 2026 pushes the Annex III high-risk deadline to December 2027 and high-risk AI inside regulated products to August 2028; until it is formally published, the original dates remain the binding fallback. Biometric identification (facial recognition) is classified high-risk and requires layered GDPR and AI Act compliance: risk assessments, technical documentation, post-market monitoring. Even non-biometric anomaly detection (PPE, crowd density) sits in the high-risk bucket for some deployments and triggers documentation and testing obligations.
U.S. picture: Illinois BIPA, Texas, California CCPA, NYC Local Law 144 (biometrics in employment), and an active patchwork of state bills. China’s PIPL constrains video data transfers and effectively forces on-prem inference for Chinese deployments.
Practical posture for 2026. Avoid facial recognition unless it is legally required and you have legal cover; prefer pose, skeleton and heat-map representations. Process on the edge where you can. Document the model, the dataset, the bias evaluation and the human-in-loop review path; keep a six-year audit log; have a model card you can hand to a regulator on request.
Reach for pose-only detection when: the use case can be solved without identifying individuals (PPE, fall, intrusion, queue, crowd) — that single design decision typically removes 60–80% of the GDPR / BIPA / EU AI Act compliance work.
Five questions to choose your AI video stack
1. What anomaly do you actually need to detect, and why does it cost money today? Quantify the cost of the current miss-rate. If you cannot put a number on it, the project will not survive year two.
2. What is the latency budget? Forklift collision and fall detection demand <100 ms; retail forensic search tolerates minutes. The answer locks edge versus cloud.
3. How many cameras and what resolution? Drives hardware cost (Jetson Orin vs Coral), licence cost (per camera vs per stream), and architecture (one big NVR vs 10 edge boxes).
4. Do you have labelled data, or do you need to collect it? Six months without an answer here means your timeline is fiction. Either commit to a labelling vendor (Sama, Label Your Data, Voxel51) or pick a model that supports unsupervised anomaly discovery.
5. Who owns the model after launch? Drift kills AI products. If nobody on your team can retrain a model in three months, structure the engagement as a managed service or buy from a VSaaS that retrains for you.
Five pitfalls that derail AI video projects
1. Treating YOLO accuracy on COCO as your accuracy. COCO mAP@50–95 tops out near 55% across 80 classes, and a generic model can miss far more than that on your factory floor or retail aisle. Fine-tune on site-specific data; budget 2,000–5,000 labelled images per anomaly class minimum.
2. Edge underspecified. A Jetson Nano cannot run YOLOv12 on six 4K streams. Size hardware to the actual model and FPS target before signing the SOW; benchmark with NVIDIA Jetson and Hailo published numbers, not vendor claims.
3. No alert-tuning loop. The system ships, alerts flood, the operator silences notifications, the project is dead in three weeks. Build a per-camera, per-class severity dial and a feedback button on every alert from day one.
4. No drift monitoring. Models go stale: new uniforms, new shelves, new lighting, new vehicles. Without quarterly retrain plus distribution-shift dashboards (Evidently, WhyLabs, NannyML), accuracy decays silently — usually noticed only after a missed incident.
5. Privacy posture as an afterthought. Adding facial recognition late in build doubles compliance work and risks BIPA / GDPR exposure. Decide pose-only vs face vs hybrid in week one; document it; stick to it.
Stuck between Verkada, Milestone+BriefCam and a custom build?
Send us your camera count, target use cases and budget. In 30 minutes we’ll talk through the trade-offs and follow up with a 1-page recommendation — not a pitch deck.
KPIs that prove the system is working
Pick a small set, instrument them on day one, review weekly. Three buckets cover most decisions.
Quality KPIs. Precision and recall per anomaly class (target precision ≥ 90% for safety-critical, recall ≥ 95% for theft / fall); mAP@50–95 for the object backbone (target ≥ 0.75 on site-specific data); per-class false-positive rate per camera-day.
Business KPIs. Incident reduction percentage versus pre-AI baseline (retailers report 30–50%, forklift sites 90%+, factories 30–40%); operator hours saved per week; alert-to-action time (target < 30s for safety-critical); ROI by quarter.
Reliability KPIs. Edge-box uptime > 99.5%, glass-to-glass latency < 100 ms p95, model-drift score weekly, retrain cadence (quarterly minimum). Track by camera, by site, by region — aggregate numbers hide problems.
When NOT to use AI video anomaly detection
1. The anomaly is rare and easy to enumerate. “Door open after 2200” does not need a deep-learning model; a contact sensor and a cron job cost less and never drift.
2. You cannot fund the post-launch operations. Without quarterly retrain, alert tuning and drift monitoring, AI video decays silently. If you cannot staff that, buy a VSaaS that owns the model lifecycle.
3. The use case requires facial recognition in a high-risk regulatory context. Workplace identification under NYC Local Law 144, EU residents under the AI Act — the legal cost can swamp the safety benefit. Use pose-only or skip the project.
FAQ
What is AI video anomaly detection in one sentence?
A pipeline that uses object detection, tracking, pose / action models and an anomaly head to flag deviations from learned normality on live or recorded camera feeds — producing structured, searchable events instead of raw motion alarms.
How accurate are AI video anomaly detection systems in 2026?
The best YOLO detectors reach about 55% mAP@50–95 on COCO’s 80 classes (roughly 70% mAP@50); attention models add a little on crowded scenes. Site fine-tuning matters more: production deployments routinely report ≥ 95% PPE detection, F1 ≥ 0.92 on hospital fall detection, and 30–65% fewer operator-facing false alerts.
Should I run inference on the edge or in the cloud?
Edge for safety-critical anomalies (sub-100 ms latency), bandwidth-limited sites or privacy-sensitive deployments. Cloud for fleet-scale forensic search, seasonal scaling, and centralised compliance. Most 2026 deployments are hybrid: edge for the alerts, cloud for the index and the search UI.
How long does it take to ship an AI video MVP?
4–8 weeks for a single use case using off-the-shelf YOLO and a minimal operator UI. 4–6 months for a production-ready system with custom dataset, fine-tuned model, multi-camera deployment, alert pipeline and operator dashboard. Plan an additional 2–3 months to scale beyond 100 cameras.
How does AI compare to rule-based motion detection?
AI emits structured metadata (person, vehicle, missing PPE, fallen patient) and learns from data, so it filters trees, shadows and weather that drown rule-based systems. Public deployments report 30–65% reduction in false alerts — the difference between an operator who trusts the system and one who silences it.
Do I need facial recognition for AI video anomaly detection?
Almost always no. PPE, fall, intrusion, queue and crowd analytics work on pose, skeleton and object representations — without identifying individuals. That posture sidesteps most of the GDPR, BIPA and EU AI Act friction. Add facial recognition only if the use case legally requires it, and document the legal basis.
What hardware should I plan for on the edge?
Defaults: NVIDIA Jetson Orin Nano / NX / AGX for multi-stream sites (6–30 cameras per box, 18–26 ms latency at 4K on AGX), Hailo-8 (26 TOPS @ 3W) for low-power retrofits, Google Coral TPU for IoT-style single-camera nodes. Match TOPS to the model and the FPS target before purchase.
What does AI video anomaly detection cost in 2026?
VSaaS runs $5–$18 per camera per month depending on AI tier. Edge boxes: $40–$300 (Hailo / Coral) up to $300–$600 (Jetson Orin). Custom build: 4–8 weeks for a single-use-case MVP, 4–6 months production-ready, with quarterly retrain budgeted at 10–30% of the build cost per year.
What to read next
VMS
Video Surveillance Management Systems: 2025 Guide
The platform layer that AI anomaly detection plugs into — vendors, architecture, decision rules.
Analytics
Real-Time Video Analytics: 4 Powerful Business Applications
Where AI video analytics actually moves the P&L — retail, security, mfg, healthcare.
Cameras
AI-Powered IP Cameras in 2025
The hardware layer underneath the model — what to look for in 2026 IP camera procurement.
Features
12 Essential Features of Modern VMS Software in 2026
A feature-by-feature checklist for evaluating any VMS / AI surveillance combination.
Service
Custom Video Surveillance Software Development
Our service page for AI video and surveillance — what we ship, how we charge, what we cover.
Ready to ship AI-powered video monitoring?
AI video anomaly detection in 2026 is a procurement category, not an experiment: edge silicon is cheap, models are open-source-grade, and ROI is documented across retail, manufacturing, healthcare, logistics and smart cities. The buyer’s job is to pick the right path (VSaaS, VMS plus plugin, or custom build), the right anomaly target, the right edge/cloud split, and a partner who has shipped it before.
If you have a camera count, a target use case and a regulatory context, we can come back inside 48 hours with a 1-page architecture note: model choice, edge box, alert pipeline, realistic latency, privacy posture and an honest cost range. No pitch deck, no upsell.
Let’s scope your AI video stack together
30 minutes, no slides. We’ll come back with a 1-page architecture note — model, edge box, alert pipeline, privacy posture — tailored to your camera fleet.








