



Key takeaways
• 20+ years, 625+ projects, one standard. The same engineers who shipped V.A.L.T. for 770+ U.S. organizations and BrainCert’s 500M+ live minutes carry your build.
• Multi-stack by design. PHP, JavaScript/TypeScript, Go, Python, Java/Kotlin, Swift, C++. We pick the stack per the problem, not the CV — and fluency across stacks is what keeps estimates honest.
• Agent engineering ships faster. Our spec-driven agent practice compresses typical 6-month builds into 10–14 weeks for first production. Fewer people-hours, more senior judgment.
• Quality is cultural, not sprint-5. Code review, typed contracts, test coverage thresholds, and reliability KPIs are baked in. We don’t fix bugs; we prevent them.
• You hire engineers, not ticket-closers. Every senior dev on our team owns an outcome. If that’s the partner you want, book a scoping call.
Why Fora Soft wrote this piece
Founders and CTOs evaluating development partners often ask the same thing: can this team actually ship? This piece answers that honestly. It’s a field report on how our engineering team is structured, which stacks we run, how code quality is enforced, where AI and agent methods sit in the workflow, and what you can expect in the first weeks of a project.
Fora Soft has shipped 625+ products over 20 years — video, AI, telemedicine, e-learning, surveillance, fintech. See real engagements: V.A.L.T. (770+ organizations, 2,000+ IP cameras), BrainCert (500M+ delivered minutes), Tradecaster. The engineering patterns we describe below are what keeps that shipping rate with a team sized around craftsmanship, not headcount theater.
Need engineers who own outcomes, not just stories?
Book a 30-min scoping call. You’ll meet the lead engineer who’d own your project, not a sales rep. Leave with a plan and a range you can defend.
How the engineering team is structured
Every project runs with a tech lead (senior, owns architecture and code review), a core build team (mid–senior, 2–6 depending on scope), and domain specialists on call (WebRTC, ML/AI, payments, video streaming). Above the tech lead sits a head of engineering who allocates resourcing, coaches on craft, and escalates hardware/cloud decisions that cross projects.
We deliberately stay senior-heavy. Most of our engineers have 5–12+ years in the relevant domain. We add juniors in structured apprenticeship under a lead, never as primary implementers on client work. That’s how we keep review cycles short and defect rates low.
Which stacks we run — and why we pick each
| Stack | Best for | Fora Soft pattern |
|---|---|---|
| TypeScript + Node / NestJS | Web apps, real-time backends, unified full-stack teams | Default for new builds; strict types, Zod at boundaries |
| React + Vite | Modern web frontends, SPAs, admin panels | Vite over Webpack; micro-bundles; Suspense patterns |
| Go | High-throughput services, SFU-adjacent, edge infra | Where Node can’t hold the CPU/latency budget |
| Python | ML/AI, data pipelines, CV & ASR glue | FastAPI for services; Poetry + pyright for discipline |
| Kotlin (Android) | Native Android apps, real-time SDK integrations | Jetpack Compose, coroutines, custom WebRTC glue |
| Swift (iOS) | Native iOS apps, AVFoundation, callkit | SwiftUI + Combine where viable; deep MLX experience |
| PHP (Symfony / Laravel) | Existing estates; long-standing platforms | Used where the existing codebase rewards continuity |
| C++ (selective) | Low-level codec work, native video processing | Reserved for performance-critical paths only |
We’ll tell you the trade-offs we see before we let you pick. “Use what you know” usually wins on maintainability; but for real-time video, audio, or ML-heavy backends, the stack choice has material performance consequences.
Reach for Go when: you need low p99 latency on a hot path, high goroutine concurrency, or tight memory footprint. Below that bar, TypeScript+Node is usually the right default.
Our engineering process, sprint by sprint
Sprint 0 — Tech architecture (1 week). The tech lead translates the analyst’s deliverables into architecture sketches, ADRs, API contracts, infrastructure plan, and a test strategy. Engineers read; questions land in sprint-1 backlog.
Sprints 1–N — Build (2-week sprints). Story pull, PR-driven development, CI enforced green, daily async standups. Every PR goes through at least one senior reviewer and automated checks (types, tests, lint, security).
Weekly tech-debt budget. 10–15% of each sprint is reserved for paydown — refactors, dep bumps, test-gap fills. Skipping this is the #1 reason projects slow down in month 3.
Pre-launch hardening (1–2 weeks). Load tests, security review, accessibility audit, chaos scenarios. Our QA team (see the QA team playbook) owns sign-off.
Post-launch SRE cadence. Observability stays live, weekly reliability reviews, monthly roadmap refresh. We don’t disappear after launch; most clients keep us on a maintenance engagement.
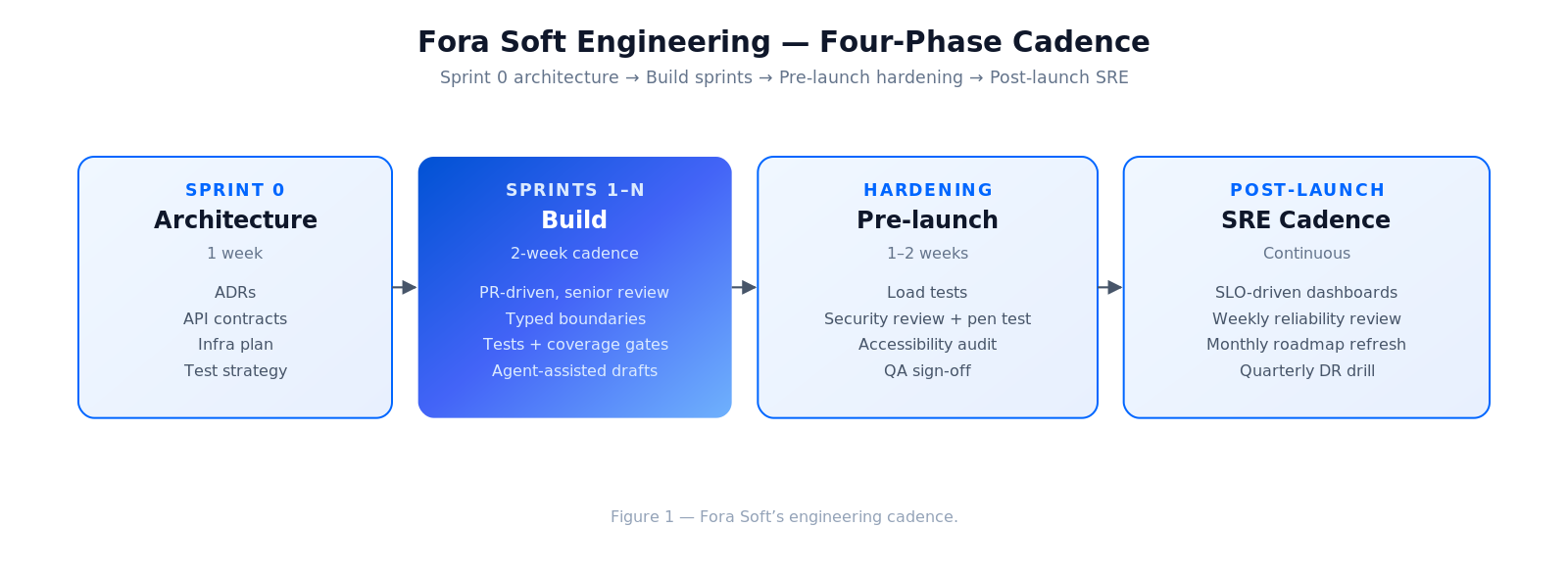
Figure 1. The engineering cadence across sprint 0, build, hardening, and post-launch.
Reach for a senior tech lead when: the project has >15 services, real-time or ML-heavy components, multi-region deployment, or a hard deadline tied to a business event. Leads pay for themselves in avoided rework in the first month.
Code quality: what it means operationally
1. Strict types at boundaries. TypeScript strict mode, pyright strict in Python, generics used where they prevent a class of bugs. Runtime validation at ingress (Zod, Pydantic) so API consumers can’t sneak bad data in.
2. Tests as first-class citizens. Unit tests for logic, integration tests for contracts, end-to-end for the critical user journeys. Coverage thresholds enforced in CI (typically 70%+ unit, 80%+ critical paths). Without the thresholds, coverage decays.
3. Code review discipline. Every PR reviewed; seniors review seniors. Review comments are direct but kind. Approved PRs merge via CI, not a button.
4. Architecture decision records (ADRs). Every non-trivial architectural choice is captured in a short markdown ADR (context, decision, consequences). Six months later, when someone asks “why did we pick X?”, the answer is on disk.
5. Observability day one. Structured logging, tracing, metrics from sprint 1, not added later. “It works on staging” is not a certification.
Agent engineering — how we ship faster without cutting corners
We use LLM-powered coding agents inside a strict review discipline. Agents draft, humans decide. The wins are concrete.
1. Spec-driven generation. Analyst specs feed agents that draft scaffolding, types, service boundaries, and tests. Humans iterate on the draft rather than starting from scratch. See the details in Spec-Driven Agentic Engineering.
2. Test synthesis. Agents propose edge-case tests from a spec plus an implementation. Engineers accept, edit, or reject. This is where agent-assisted coding delivers consistent quality — more tests, lower cost.
3. Code review assistant. Agents flag obvious regressions, missing null checks, and security anti-patterns before the human reviewer. Humans focus on design and intent.
4. Documentation generation. API docs, README stubs, architecture summaries from code + ADRs. Maintenance documentation stays current, which is rare in industry.
Effect on estimates: typical 6-month builds land in 10–14 weeks for first production. That’s why our quotes beat incumbents on both price and timeline — not because we skip steps, but because the agent compresses the routine.
Mini case: real-time audio on V.A.L.T. — the hard-to-fake wins
One of our longer-running engagements, V.A.L.T., needed a new Talkback feature — web-browser-to-IP-camera two-way audio across a fleet of cameras that included older, resource-constrained models. Latency had to stay under 300ms on the hot path; audio needed resampling, encoding normalization, and noise reduction; cameras without native WebRTC support required a shim.
What shipped: a rewritten frontend audio capture pipeline, a middle-tier audio processor handling resampling and noise reduction, backend adjustments for camera compatibility, and — as a side project — a Vite migration that cut the team’s frontend build from ~15 minutes to ~25 seconds. Result: usable Talkback on the client’s full camera fleet, and a measurable productivity lift on every subsequent feature because builds stopped being the bottleneck. The Vite story is the kind of “invisible” win that separates engineers who care from those who don’t.
Reliability engineering: the boring stuff that matters
1. SLOs before features. Availability, latency, and error-rate targets decided with the client; dashboards and alerts wired before the first user. See our deeper notes in How to make software reliable and crash-proof.
2. Blameless postmortems. Every incident gets a 5-why and a follow-up action list. Action items land in the backlog with an owner and a date.
3. Load testing. Before every launch and before every major feature. Synthetic users hit the same paths real users will.
4. Security review. Threat model at architecture time; OWASP Top-10 linted in CI; penetration test before production for any product with auth and sensitive data.
5. Disaster recovery drills. Quarterly on production-facing products. RTO/RPO documented and tested — not just written in a Confluence page.
Cloud, infra, and delivery stack
Hosting. AWS, GCP, Azure — we work in all three. For cost-sensitive video workloads we also use Hetzner AX-series and DigitalOcean. Cloudflare for edge and CDN.
Orchestration. Kubernetes for multi-service apps, Nomad for simpler stacks, ECS/Fargate for AWS-native teams. We use what the client’s operations team can run.
CI/CD. GitHub Actions, GitLab CI, Buildkite. Blue-green or canary deploys for any production system with real users.
Observability. Datadog, Grafana + Prometheus, OpenTelemetry. Structured logs to Loki or Cloudwatch. Alerting into PagerDuty or Opsgenie.
Data. Postgres as the default; Redis for caching; Kafka / NATS for event streams; Clickhouse or Snowflake for analytics workloads.
Reach for Hetzner when: you’re hosting heavy 24/7 video workloads and the AWS bill is eating the business. We’ve seen 50–70% savings on bare-metal video infra vs. hyperscalers.
What engineering actually costs
Three realistic shapes for 2026, grounded in our recent projects:
| Engagement | Typical duration | Cost shape |
|---|---|---|
| Focused MVP | 6–10 weeks | $40–$90k, fixed |
| Mid-scope build | 10–16 weeks | $90–$180k fixed, or T&M |
| Complex platform | 4–9 months | $180–$600k+, staged |
| Dedicated team | Ongoing | Per-engineer monthly rates |
We use agent engineering to compress timelines; our fixed-price deals land because we can scope cleanly after a 1–2 week spike. If the build is uncertain we say so; we don’t quote a number we can’t defend.
Want a defensible estimate for your build?
Bring your brief, stack preferences, and constraints. We’ll return a cost shape that adds up — or tell you the spike needed to get there.
Reach for fixed-price when: scope is tight, specs are clear, and a scoping spike converged to an estimate we can defend. Otherwise T&M is cheaper for both sides.
Decision framework — when to hire Fora Soft engineers
Q1. Is the product’s complexity in real-time, AI, or regulated systems? Yes: we’re a strong fit; our 20-year portfolio is concentrated there.
Q2. Do you need engineers who can make architecture decisions, not just execute? Yes: that’s how we staff. Our seniors are hired for judgment, not for ticket throughput.
Q3. Do you want a team that stays post-launch? Most of our clients stay with us on maintenance and iteration. We built for longevity.
Q4. Is speed-to-first-production critical? Agent engineering makes us fast without cutting corners. If you have a launch deadline tied to a business event, we’re the right call.
Q5. Is the engagement $40k+? Below that we may recommend a smaller partner — we’ll give you the referral rather than take a misfit contract.
Five engineering pitfalls on rescue projects
1. Everything in one big service. A 50k-line monolith with no module boundaries ruins the sprint-5 onwards. Refactor early.
2. No types. Dynamic-only JavaScript or untyped Python will eat your delivery speed by month 3. Types pay for themselves.
3. Skip observability. Teams who add logs in sprint 10 are flying blind when the first incident hits sprint 11.
4. Ignore tech debt budget. Without a standing 10–15% sprint allocation, debt compounds and velocity halves.
5. Missing reviews on junior PRs. Juniors shipping unreviewed code to production is the fastest way to turn a team into a firefight. Make reviews non-negotiable.
KPIs we hold the engineering team to
Quality KPIs. Defect escape rate to production (<3 per 10k LOC). Mean time to detect incident (<5min). Mean time to recover (<30min for SEV-2, <4h for SEV-1). Post-deploy rollback rate (<5%).
Velocity KPIs. Cycle time from PR open to merge (<2 days). Deployment frequency (multiple per day on mature projects). Lead time for change (hours, not weeks).
Cost KPIs. Estimate-to-actual variance (±15% ceiling on fixed-price). Cloud spend / DAU trend (should decline post-optimization). Engineering retention (>90% annually).
When you don’t need Fora Soft engineering
If your product is a simple CRUD app with no real-time, AI, or streaming component, and you have a capable in-house team, we’re probably over-qualified. If you need a single contractor to make quick changes on a legacy PHP site, a freelancer will serve you better than our delivery model.
Where we earn our seat: complex, reliable, multi-domain builds. That’s the work where our 20-year portfolio and engineering discipline compounds, and where agent engineering gives you real speed without corner-cutting.
Dedicated team model — when it’s the right pattern
For clients running ongoing product development, we offer a dedicated team — named engineers who work as an extension of your org for months or years. We’ve run 3–10 person dedicated teams for clients continuously for 5+ years. The pattern works when your roadmap is continuous and you want the same senior engineers owning product memory.
How we work with your team
Your tools. Jira, Slack, GitHub/GitLab, Linear, Notion, Confluence, PagerDuty — we plug into whatever your org runs on. Our engineers show up in your standups and retros.
Time zones. We span Europe and MENA time zones; major overlap with North American mornings and European working hours. Async-first where we can, synchronous where decisions need it.
Security and compliance. NDA + MSA before any code access. We hold SOC 2-aligned internal controls and can sign BAAs for HIPAA projects. Data-residency constraints respected at deployment.
Ownership handover. If we build for you, you own the code. Full handover docs at key milestones. We can transition to your in-house team or another vendor cleanly.
A note on culture
We value craft. That shows up as honest code reviews, refusal to ship obvious shortcuts, and a willingness to disagree with the client when we think we’re right. We also value kindness — in reviews, in retros, in client conversations. The two aren’t in tension; they’re what keeps senior engineers happy for years, which is why our retention is high and our quality is consistent.
What you feel on day one: engineers who care, push back when needed, and bring real judgment to the table. If that fits your team’s culture, the partnership will be long. If you want quiet order-takers, we’re not the right vendor.
FAQ
Can we meet the engineers before we sign?
Always. You’ll meet the tech lead who’d own your project on the first or second call. If we can’t align on craft and communication style, we’d rather know now.
Who owns the code?
You do. Everything we write is yours, in your repos, under your licenses. Full transfer at milestones and final handover.
Do you do fixed-price or time-and-materials?
Both. Fixed-price after a scoping spike when the scope is tight enough to defend; T&M when the product is exploratory. We won’t lock in fixed-price on an uncertain scope — it’s bad for both sides.
How do you handle mid-project scope changes?
Our analyst runs a change flow: impact assessment, revised plan, revised estimate, sign-off. Small scope changes inside buffer; larger changes become change orders. Nothing slips through as “just a tweak.”
Can you join our existing codebase or do you prefer greenfield?
Both. Roughly half our projects are legacy rescues or extensions. We read the codebase before quoting, and we bring a structured onboarding pattern so new engineers are productive in 2–3 days.
Do you sign HIPAA BAAs, SOC 2 DPAs, GDPR DPAs?
Yes to all three. We’ve shipped HIPAA-compliant workflows for medical education; we align internal controls with SOC 2 for enterprise buyers; we run EU-resident deployments under GDPR DPAs.
How does agent engineering change the cost?
Net effect: 20–40% less calendar time and 10–25% lower cost on typical builds. The savings don’t come from fewer people; they come from senior engineers spending less time on routine code.
Do you work on hardware-adjacent or embedded projects?
Yes — we’ve shipped on Jetson Orin (edge AI), intercom/camera integrations, ONVIF-based surveillance, and custom audio hardware pipelines. Firmware isn’t our core, but the edge-adjacent work is a common engagement.
What to Read Next
Agent Engineering
How We Use Spec-Driven Agents to Speed Up Development
The agent playbook that compresses our 6-month builds into 10–14 weeks.
Reliability
How to Make Software That Doesn’t Crash
SLOs, observability, blameless postmortems — the boring stuff that keeps products alive.
Quality
What to Do If There Are Too Many Bugs in Your Project
Diagnostics and remediation playbook for legacy products drowning in defects.
QA Team
Inside Fora Soft’s QA Testing Team
How the QA team partners with engineering to own sign-off on every release.
Ready to hire engineers who earn their seat?
Engineering at Fora Soft is craft plus discipline plus the compounding speed of agent-assisted workflows. We ship reliable, observable, maintainable systems in the domains where it matters most — video, AI, telemedicine, surveillance, fintech. We staff seniors, we review every PR, we bake accessibility and compliance in from day one, and we stay post-launch. That’s 20 years of working the same way.
If that’s the engineering partner you want, a 30-min call is the shortest path from your brief to a plan and a range you can defend to your board.
Want our engineers on your next build?
30 minutes with the tech lead who’d own your project. You’ll leave with an architecture sketch and a realistic timeline.








