



Key takeaways
• Start with one outcome, not ten models. Pick either personalised sequencing, faster content authoring, or early intervention — and ship one of them end-to-end before layering on the next.
• IRT + a recommender gets you 80% of the value. You don’t need Deep Knowledge Tracing on day one. Item Response Theory plus a content ranker ships in 6–10 weeks and lifts completion rate by 20+% in published studies.
• LLM-generated content only ships with guardrails. Retrieval-Augmented Generation, domain-expert review, and explicit citation tracking are non-negotiable — hallucinations are reduced, not eliminated.
• FERPA / COPPA / GDPR are architecture, not paperwork. Data Processing Agreements, parental consent flows, PII-free prompts and auditable logs need to be wired in week 1 or they become an expensive retrofit.
• Measure learning gains, not model accuracy. The KPIs that matter are completion rate, time-to-mastery, retention at 30 days, and teacher override rate — not AUC or MAP.
The phrase “integrate machine learning into curriculum development” covers at least ten different products: adaptive learning paths, content recommendation, difficulty calibration, knowledge-gap detection, AI-generated lesson plans, automated quiz authoring, outcome prediction, misconception detection, teacher-assist copilots and curriculum A/B testing. Most EdTech teams try to ship four of those at once, burn 12 months, and end up with none of them in production. This guide walks you through the order we actually ship them for clients, with real data, real costs and real compliance traps.
The target audience is EdTech founders, chief learning officers, curriculum leads and CTOs scoping an ML-powered learning product. Everything below is sequenced the way we scope a new engagement: pick the outcome, find the data, choose the model family, wire it into the LMS, gate it with compliance, measure the learning gains, and only then scale.
Why Fora Soft wrote this playbook
Fora Soft has spent 21 years shipping multimedia and AI-powered products — 625+ delivered, with a heavy concentration in EdTech. We built BrainCert, the WebRTC virtual classroom serving over a million learners at $10M ARR; Scholarly, the AWS-recognised adaptive-learning platform; ALDA, an AI course-material generator that saves university faculty 60%+ of preparation time; and Instaclass, a firewall-bypassing virtual classroom deployed across UAE and South African schools.
What follows is the condensed 2026 playbook we hand to new EdTech clients: the right ML problem to tackle first, the data you need, the model families in production, the vendors setting the bar, the compliance shape, the realistic cost, and the pitfalls that sink otherwise-good pilots. If you want a second opinion or a fixed-price estimate accelerated by our Agent Engineering workflow, book a call at the end.
Scoping ML into your curriculum roadmap?
Share your learner volume, LMS stack and the one outcome that matters this year. In 30 minutes we’ll sketch which model family, which data and which vendor hits it fastest.
What “machine learning in curriculum development” actually means
The phrase is used loosely. In practice there are ten distinct products — each with its own data requirements, model family, evaluation metric and compliance shape. They are not interchangeable, and the effort to ship a recommender is not the same as the effort to ship a generator.
| Use case | Model family | Effort | Typical impact |
|---|---|---|---|
| Content recommendation | Collaborative filtering + content-based hybrid | Low | +15–30% engagement, +20–28% completion |
| Difficulty calibration | IRT (2PL / 3PL), AutoIRT | Low–Medium | Cleaner assessment, less frustration |
| Adaptive learning paths | Knowledge Tracing (BKT / DKT / SAKT / AKT) | Medium | Time-to-mastery −40%, pass rate +24% |
| Knowledge-gap & misconception detection | Response-pattern clustering + LLM tagging | Medium | Targeted remediation, early intervention |
| Lesson-plan & quiz generation | LLM + RAG + expert review | Medium–High | Teacher prep time −50–70% |
| Outcome & dropout prediction | Gradient boosting / logistic regression on event streams | Medium | Retention +30%, dropout −20% |
| Skill-graph / prerequisite mapping | Graph Neural Networks over standards taxonomy | High | Cross-course transfer, targeted curricula |
| Content sequencing (bandits) | Thompson sampling / UCB | Medium | Faster A/B iteration on pacing |
| Automated grading / rubric scoring | Transformer classifiers + regression | Medium | Teacher feedback time −60% |
| Curriculum A/B testing at scale | Experimentation platform + causal inference | Medium | Continuous curriculum optimisation |
Reach for recommendation + IRT when: you have a catalogue over 200 items and want the biggest engagement lift in the shortest time. This is the right first project for 80% of EdTech teams.
Reach for LLM-assisted authoring when: your core pain is teacher/instructional-designer time, not learner outcomes. Expect a 50–70% prep-time reduction once guardrails are tuned.
Reach for knowledge tracing when: you already have 3+ months of clickstream and correctness data and the business case is specifically about time-to-mastery or pass rate, not engagement.
The reference architecture we ship
Below is the architecture we’ve stood up repeatedly for EdTech clients. The same skeleton supports recommendations, adaptive paths and generation; each product plugs into a different “brain” on top of the same event and content stores.
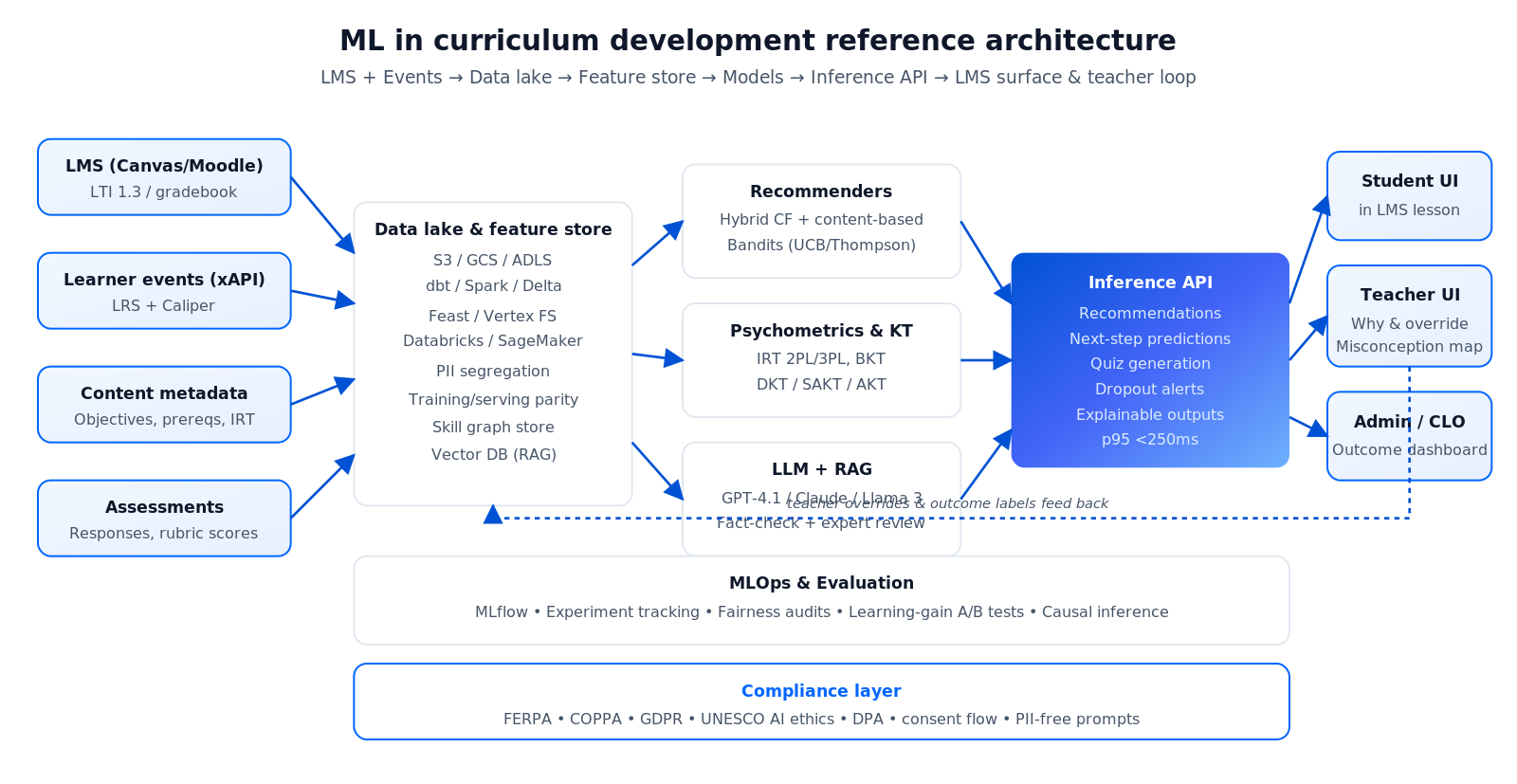
Figure 1 — ML curriculum stack: event collection (xAPI / LTI) → data lake → feature store → model training → inference → LMS surface + teacher feedback loop.
Event collection: xAPI, LTI 1.3 and Caliper
Every learner interaction — video plays, quiz attempts, hint usage, time on task — becomes an xAPI statement written to a Learning Record Store (LRS). LMS launches happen over LTI 1.3 (signed JWT, gradebook passback). xAPI is the modern default; Caliper is the IMS alternative if your LMS is Canvas/D2L-heavy; SCORM remains relevant only for legacy SCO packages.
Data lake and feature store
Events land in S3 / GCS / ADLS, are transformed by dbt or Spark, and surfaced via a feature store (Feast, Vertex AI Feature Store, Databricks, SageMaker). The feature store is what separates a reproducible ML system from a pile of notebooks — it gives you training-serving parity, PII segregation, and a single source of truth for metrics.
Content metadata and the skill graph
Content lives in your CMS, but ML needs it tagged: learning objective (Bloom’s Taxonomy verb), prerequisite concepts, difficulty (IRT-calibrated), format, duration, language. Hand-authored taxonomies beat pure LLM extraction here; the hybrid pattern we ship is a human-curated skill graph refined by LLM suggestions in a review UI.
Model training and MLOps
Training runs on Databricks / SageMaker / Vertex AI with MLflow for experiment tracking and a model registry. A simple recommender or logistic regression trains on a laptop; knowledge-tracing transformers (SAKT, AKT) benefit from a single A10/A100. Nothing in e-learning needs a 70B parameter frontier model — they are almost always the wrong tool for the job, too slow, too expensive, and too opaque for teachers to trust.
Serving layer and the teacher feedback loop
Inference is exposed through a thin API your LMS calls on-demand (recommendations) or ingests on a schedule (next-step predictions). A vector store (Pinecone, Weaviate, pgvector) powers RAG lookups for LLM generators. Crucially, every prediction is shown alongside a one-sentence explanation and a teacher override button — opaque AI loses teachers fast.
The model families worth knowing in 2026
Item Response Theory (IRT). The psychometric workhorse since the 1960s. 2PL and 3PL logistic models infer item difficulty and learner ability from binary correctness. AutoIRT automates the parameter-fitting. IRT is transparent, legally defensible for high-stakes tests, and the fastest thing to ship — we lean on it in every curriculum project.
Bayesian Knowledge Tracing (BKT). Models per-skill probability of mastery with slip and guess parameters. Interpretable, fast to train, good when you have fine-grained skill tags. The default choice before you have the data to justify a neural model.
Deep Knowledge Tracing (DKT, SAKT, AKT). RNNs and transformers over sequential responses. Better raw accuracy; harder to interpret. Ship only when you have at least a few million response events and you can clearly justify the lift over BKT.
Collaborative filtering and content-based hybrid recommenders. Matrix factorisation for the warm set, content embeddings for cold start, re-ranking on business constraints (learning objective coverage, difficulty gradient). Hybrid systems in published 2025 research hit 0.81 precision / 0.78 recall with a 4.4/5 learner satisfaction score.
LLM-based generators with RAG. GPT-4.1, Claude, Llama 3, Mistral, and Phi-3 for cost-sensitive workloads. Always grounded in your own content corpus via a vector store, always with a fact-check pass and a domain expert’s review for high-stakes outputs. Hallucinations are reduced but never fully eliminated — treat the generator as an assistant, not a decision-maker.
Contextual bandits (Thompson sampling, UCB). The right tool for sequencing experiments: “do I show this student the hard version or the scaffolded version of problem 17?” Learns faster than vanilla A/B testing and respects learner heterogeneity.
Graph Neural Networks for prerequisite and skill-graph reasoning. Use when you need to infer new prerequisite relationships from learner traversal data, or cross-course skill transfer. High ceiling, steep learning curve; often premature for a first product.
Not sure which model family fits your data?
Send us a sample schema and your monthly learner volume. We’ll tell you whether to start with IRT + recommender or go straight to knowledge tracing — and what it will cost.
The data you need before you touch a model
The single biggest predictor of a successful ML pilot is whether the data infrastructure was ready before the first model was trained. Three data sources are non-negotiable.
1. Learner event streams. xAPI / Caliper / custom events covering video plays, quiz attempts, page dwell, hint usage, login patterns. Volume target: 500+ events per active learner before recommender quality stabilises. Cold-start is solved by content-based features for the first 2–4 weeks of a new learner’s journey.
2. Assessment data. Item-level correctness, timing, rubric scores. Needs at least 50–100 responses per item for a defensible IRT calibration. Without assessment data you cannot do adaptive difficulty and you cannot measure learning gain.
3. Content metadata. Every learning object tagged with objective, prerequisites, difficulty, format and duration. Without this your recommender can surface content, but not the right content — you’ll push revision material to struggling learners or remedial content to advanced ones.
Demographics — age, grade, school, district — are optional and dangerous. Every extra column raises FERPA / COPPA / GDPR surface area. Collect only what improves the model, and only with the right consent flow.
Commercial platforms setting the bar in 2026
You don’t need to build everything. Here is the 2026 competitor map. Each platform shows what is commercially viable today — useful both for benchmarking your roadmap and for deciding which components to buy vs build.
| Platform | Primary ML angle | Segment | Notable outcome |
|---|---|---|---|
| Khan Academy Khanmigo | LLM tutor + A/B testing | K–12 + higher ed | Measurable lift in independent problem-solving transfer |
| Duolingo Max | LLM conversation + bandits | Language learning | ~$30/mo tier; gamification + GenAI combo |
| ALEKS (McGraw Hill) | Knowledge space theory | Math, K–16 | Meta-analysis: g = 0.43 as a supplement |
| Squirrel AI | Knowledge tracing, 1:1 adaptive | K–12, China + intl. | Pythagorean-theorem study: 4.2× learning gains |
| Century Tech | Adaptive pathways | Schools, UK + MENA | Strong teacher dashboard analytics |
| MagicSchool / Brisk / Diffit | Teacher-facing LLM copilots | K–12 teachers | 50–70% prep-time reduction per case studies |
| Carnegie Learning MATHia | Intelligent tutoring + cognitive model | Middle/high school math | DOE What Works Clearinghouse evidence |
| Scholarly (Fora Soft) | Adaptive AI learning | Higher ed | AWS-recognised implementation |
For a deeper vendor look at the content-creation layer in particular, see our lesson-plan generation software comparison and the AI study-guide tools roundup.
The outcomes you can actually claim
Skip vendor marketing. Here are the outcomes backed by peer-reviewed studies and production A/B tests through 2025–2026.
Pass rate and dropout. Arizona State’s adaptive-biology rollout reported a 24% higher pass rate and a 20% lower dropout rate. Institution-level adaptive deployments generally show 25–35% retention improvements in the first year.
Engagement and completion. Hybrid-recommender trials reported by the Bill & Melinda Gates Foundation lift engagement by ~34% and completion rate by ~28% versus traditional instruction.
Time-to-mastery. Well-implemented adaptive systems cut time-to-mastery by roughly 40% on average across published studies — the strongest economic case for adaptive, since teacher hours are the expensive resource.
Market size for context. AI-in-education spend was around $5.9B in 2024 and is forecast to cross $32B by 2030 (~31% CAGR) according to Grand View Research. The broader EdTech market is on track for $404B by 2025 (HolonIQ). This is a still-growing category with real budget, not a hobbyist market.
Meta-analytic caveat. The ALEKS meta-analysis across 33 studies found an average effect size of g = 0.05 when replacing instruction and g = 0.43 when supplementing it. Translation: ML works as an augmentation of good teaching, not a replacement for it.
Plugging into the LMS: Canvas, Moodle, Blackboard, Google Classroom
Most EdTech ML products live on top of an existing LMS. The integration surface is narrow and well-defined, which is good news.
LTI 1.3 for launches. Signed OAuth2 JWTs for single sign-on; supports assignment deep-linking, gradebook passback, and roster sync. Pick this for any tool the teacher or student launches from inside the LMS.
xAPI + LRS for learning analytics. Statements are written to a Learning Record Store (Veracity, LearnShare, SQL LRS, Watershed). xAPI works across web, mobile, offline and non-LMS content, which is why it has quietly become the backbone of most ML-in-curriculum systems.
SCORM for legacy courseware. Still ubiquitous in corporate training. Adequate for completion tracking; insufficient for modern analytics. Wrap, don’t rewrite.
Caliper. IMS’s newer analytics standard, stronger adoption in Canvas/D2L. If your customers run those LMSes, instrument Caliper in parallel with xAPI.
Tooling: MLOps, vector stores and the teacher-in-the-loop UI
MLOps stack. MLflow for experiment tracking and model registry is the lowest-friction default. Move to SageMaker, Vertex AI or Databricks when you need fully managed training, a feature store, and enterprise SSO. Skip heavy Kubeflow/Airflow setups unless you already have the platform team to run them.
Vector stores for RAG. pgvector wins if you’re already on Postgres and your embedding volume is under 10M vectors. Pinecone or Weaviate above that. OpenSearch, Qdrant and Vespa are strong open-source alternatives. Pick based on query patterns (filtered similarity? hybrid keyword + vector? hierarchical namespaces?), not the brand.
Feature store. Feast for lightweight, Vertex AI Feature Store or SageMaker Feature Store for managed. The win is single-source-of-truth features for both training and serving — not an academic nicety when you’re running adaptive logic live.
Teacher-in-the-loop UI. This is the underrated layer. Every inference surfaces with a plain-English “why”, a one-click override, and a feedback capture that flows back to the training data. Without it, teachers stop trusting the model the first time it’s confidently wrong. With it, they help you train the next iteration for free.
Evaluation tooling. Jupyter notebooks don’t scale; GrowthBook, Eppo or Statsig for experiment management; Arize or WhyLabs for model drift; simple SQL dashboards on learning gains for the CLO and principal users.
Mini case: ALDA, a curriculum-generator that saves faculty 60% of prep time
Situation. A US university needed to modernise course materials for an accelerating catalogue: new syllabi every semester, adjuncts without the time to build decks, and a rising expectation of personalised study guides per cohort.
What we built. ALDA is a Retrieval-Augmented Generation system on top of the faculty’s content library: textbooks, past slide decks, lecture notes. A teacher enters a learning objective and a course level; ALDA drafts a module outline, topic-aligned quizzes, and discussion prompts. Every generated claim links back to a source page, every quiz item is IRT-calibrated from historical response data, and every output goes through a faculty review UI before publishing.
Outcome. Faculty prep time fell by 60+% per unit, time-to-first-draft of a new course module dropped from weeks to hours, and the review step kept academic rigor intact. The architecture — vector store + RAG + expert-in-the-loop + IRT pre-calibration — is the same one we now reach for when any client asks for an AI-assisted course builder. Want us to sketch an equivalent for your catalogue? Book 30 minutes and we’ll walk through scope and cost.
Compliance: FERPA, COPPA, GDPR and UNESCO ethics
Compliance is where most ML-in-curriculum pilots slip. Treat it as architecture, not as paperwork.
1. FERPA (US). Educational records are protected. The most common 2024–2025 violation was teachers pasting student data into general-purpose LLMs without a Data Processing Agreement; that is a FERPA breach even if the vendor is SOC 2. Every LLM call must route through your backend with PII stripped.
2. COPPA (US, under-13 learners). Verifiable parental consent, clear notice of data practices, parental right to review/delete. Design the consent flow once and reuse it across products.
3. GDPR (EU). Explicit parental consent for minors (age varies 13–16 by country), Data Protection Impact Assessments for adaptive systems processing at scale, right to deletion/portability/objection, regional data residency if your customers demand it.
4. State-level US guidance. ~20 states have issued 2024–2025 guidance pointing to FERPA/COPPA as a baseline; ~12 explicitly warn against entering PII into AI; ~21 require encryption at rest and in transit, strong auth, and logging.
5. UNESCO’s 2023 ethics framework. Ten principles: human rights, fairness, inclusiveness, sustainability, privacy, transparency, accountability, multi-stakeholder participation, rule of law, dignity. Use them as the qualitative checklist during design reviews; use NIST AI RMF when you need a quantitative one.
Cost and timeline: conservative 2026 estimates
Below are the ranges we quote with Agent Engineering acceleration. They assume an existing LMS, an existing content catalogue and a team willing to cooperate on data access. Pure research projects and regulated high-stakes assessments sit at the top end or beyond.
| Scope | Timeline | Team shape | Where it goes wrong |
|---|---|---|---|
| Recommendation layer on top of existing LMS | 6–8 weeks | 1 ML + 1 data + 1 backend + 1 PM | Cold-start handling, metadata gaps |
| Adaptive paths (IRT + knowledge tracing) | 12–18 weeks | 2 ML + 1 data + 1 full-stack + 1 PM | Insufficient response data per item |
| LLM-based content generator with guardrails | 14–20 weeks | 1 ML (LLM/RAG) + curriculum SME + full-stack + QA + PM | Hallucinations, unclear acceptance criteria |
| End-to-end adaptive product with authoring + analytics | 6–9 months | Cross-functional squad of 6–8 | Scope creep; under-investing in teacher UI |
Add 5–15% infra cost on top: a few hundred dollars a month for a small recommender, low thousands per month for adaptive-path inference at moderate scale, and a separate LLM inference line item for generators (typically the fastest-growing part of the bill). We deliberately keep estimates conservative; where we’re uncertain, we price the discovery sprint first and only quote the rest once data is on hand.
A 12-week plan to ship your first ML curriculum feature
Here is the cadence we run for clients starting from zero ML. Substitute the specifics for your platform; the shape is stable.
Weeks 1–2 — Outcome, data audit, compliance. Lock the one outcome (completion? pass rate? prep time?). Inventory event streams, assessment data, content metadata. Draft the DPA, update privacy policy, design the consent flow. No model work yet.
Weeks 3–4 — Instrumentation and the skill graph. Stand up xAPI event collection, LRS, a minimal feature store. Tag the top 200 content items with objective, difficulty placeholder and prerequisites.
Weeks 5–7 — First model, offline evaluation. For a recommender, train a hybrid CF / content-based baseline. For adaptive, fit a 2PL IRT over the top 300 items. Evaluate offline against held-out responses, check fairness across subgroups, run a sanity review with an instructional designer.
Weeks 8–9 — Serving and teacher UI. Wrap the model in a thin API. Build the teacher view: what the model predicts, why (in plain English), and a one-click override. Ship to 5% of learners behind a feature flag.
Weeks 10–11 — A/B test with a causal design. Randomise at cohort or classroom level to avoid interference. Compare treated vs control on the pre-agreed outcome. Hit statistical significance or document why you didn’t.
Week 12 — Rollout decision and roadmap for v2. If the outcome moved, widen the rollout; if not, diagnose data vs model vs UX. Only then start the next feature.
Five pitfalls that sink ML curriculum rollouts
1. Shipping the wrong model first. Reaching for Deep Knowledge Tracing on day one when a recommender + IRT would cover the business case in a third of the time. Almost every over-engineered EdTech ML product we’ve audited made this mistake.
2. LLM generators without retrieval and review. Raw prompts hallucinate. RAG reduces but doesn’t eliminate it. For student-facing content, a domain-expert review pass is mandatory, not optional. The moment a faculty member finds a wrong formula in an AI-generated worksheet, the product loses its mandate.
3. Over-personalisation and silo effects. An adaptive engine that always avoids hard material produces short-term engagement gains and long-term learning collapse. Always include “productive struggle” branches and objective coverage constraints in the path generator.
4. Teacher workflow ignored. The fastest way to kill an EdTech ML product is to build it for learners and forget the teacher. Every recommendation needs a plain-English justification and an override button; every dashboard needs to show where the AI is weakest so the teacher can trust where it’s strong.
5. Compliance as an afterthought. PII in prompts, no DPA with the LLM vendor, no consent flow for under-13 learners. All of these are show-stoppers for enterprise sales. Close them in week 1, not month 6.
When you should not use ML in curriculum development
There are platforms where hand-authored paths beat ML decisively: small catalogues (under 100 items), niche professional training with heterogeneous prerequisites, regulated high-stakes assessment where explainability is a legal requirement, and early-stage EdTech where there’s simply not enough data yet. There are also organisations where leadership won’t update privacy policies, won’t invest in data infrastructure, or won’t commit to at least a year of iteration — ML cannot save those projects. Revisit when you cross 1,000 active learners, 10,000 assessment responses per week, or a catalogue of 300+ items.
A decision framework — pick your first ML feature in five questions
Q1. Which single KPI has to move this quarter? Completion rate → recommender. Pass rate / time-to-mastery → IRT + adaptive paths. Teacher prep time → LLM authoring copilot. Retention → dropout prediction + early intervention.
Q2. Do you have event and assessment data for at least 3 months? Yes → ML pilot is feasible. No → invest 2–3 months in instrumentation first; there’s no shortcut.
Q3. What’s your learner age range? K–12 → COPPA / FERPA constraints dominate the architecture. Adult learners → GDPR + contract terms. Corporate training → customer-specific DPAs.
Q4. Are teachers part of the product loop? Yes → invest equally in the teacher UI. No → you have a harder explainability and QA burden.
Q5. Who owns ongoing operations? No dedicated ML engineer → pick a managed layer (OpenAI + a recommender SaaS, or an AI-curriculum platform partner). Full ML team → DIY with Databricks / SageMaker / Vertex AI.
Ready to ship your first ML curriculum feature?
We’ve shipped adaptive learning, AI authoring and knowledge tracing for BrainCert, Scholarly, ALDA and more. Our Agent Engineering workflow gets first production-ready model in 8–12 weeks.
KPIs: what to measure after launch
Learning KPIs. Pass rate, time-to-mastery, retention at 30/60/90 days, completion rate, misconception-resolution rate. These are the only numbers your customer cares about.
Business KPIs. Paid conversion, renewal rate, instructor NPS, seats expanded per account. ML should move these or it isn’t earning its place on the roadmap.
Reliability & trust KPIs. Model uptime, latency p95 under 250ms for in-lesson recommendations, teacher override rate (a rising override rate is the loudest early signal of model drift), hallucination rate on generated content.
FAQ
Can I use ChatGPT directly for curriculum generation?
Not for anything student-facing. Raw LLMs hallucinate facts, and pasting student data into ChatGPT without a Data Processing Agreement is a FERPA violation. The right pattern is a vendor API (OpenAI, Anthropic, Bedrock) behind your own backend, with PII stripped, Retrieval-Augmented Generation grounded in your content, fact-checking, and domain-expert review for high-stakes output.
How much data do I need before knowledge tracing is worth it?
Rule of thumb: 50–100 responses per item for stable IRT calibration, and at least 500+ responses per active learner before deep knowledge tracing justifies the complexity. Below those thresholds, stick with a hybrid recommender and simple BKT.
Do I need to build my own LMS or can I integrate?
Integrate. Canvas, Moodle, Blackboard, Google Classroom, Thinkific and most modern LMSes expose LTI 1.3 and xAPI. Building a new LMS just to host one ML feature is almost never the right call — ship the feature as an LTI tool first.
How do I avoid bias in adaptive learning?
Audit the training data for demographic representation, evaluate models on held-out subgroups (by grade, language, accessibility status), monitor production predictions by protected class, and always keep a teacher override in the loop. Transparency reports matter more than perfect fairness metrics.
What does it cost to run LLM-based content generation?
Per-generation costs are typically $0.01–$0.20 at 2026 pricing (GPT-4.1 / Claude / Llama 3 on Bedrock), depending on output length and retrieval depth. Monthly API bills for a mid-size EdTech range from a few hundred to low thousands of dollars. Caching common outputs and using smaller models for low-stakes tasks cuts this aggressively.
Does ML work for small catalogues?
Generally no. Below ~100 items a hand-authored learning path beats any algorithm because a subject-matter expert already encodes better prerequisites than your model will learn. Reach for ML once your catalogue exceeds 200–300 items or your learner pool is heterogeneous enough that one-size paths fail.
What about multi-language support?
Multilingual embeddings (e5-multilingual, BGE-M3, Cohere Embed) and modern LLMs handle 40+ languages natively. The harder part is translating your skill graph and prerequisite tags consistently. Budget for a localisation pass per language; expect to re-calibrate IRT per locale if assessment items differ.
Can Fora Soft integrate ML into our existing EdTech platform?
Yes, this is one of our most common engagements. We plug into Canvas, Moodle, Blackboard, Thinkific, custom LMSes and internal corporate training portals. Typical scope is 6–10 weeks for a recommender, 12–18 weeks for adaptive paths, and 14–20 weeks for an LLM-assisted authoring copilot. Book a call and we’ll scope yours.
What to Read Next
Personalisation
AI-Crafted Personalised Learning Materials in 2026
The 3-layer stack: data, model, delivery — with costs and pitfalls.
Authoring
Best AI Lesson Plan Generators in 2026
MagicSchool, Diffit, Curipod and the rest — compared.
Video + AI
AI for E-Learning Video Tools: Cut Costs 60%
Captions, summaries and translation for the video layer of your LMS.
Content AI
10 Best AI Tools for Educational Content Creation
Stack guide for the content generation layer of your platform.
Case study
BrainCert — A Virtual Classroom for a Million Learners
How an AI-assisted LMS scales to $10M ARR and 1M+ students.
Ready to ship ML into your curriculum?
Machine learning in curriculum development is a real, measurable lever in 2026 — Arizona State’s 24% pass-rate lift, Squirrel AI’s 4× learning gains, and dozens of replicated meta-analyses all say the same thing: ML makes good teaching better. But only if you pick one outcome, get the data right, ship an interpretable model with a teacher in the loop, and measure learning gains rather than model accuracy.
Start with a recommender or IRT. Layer in adaptive paths once the data justifies it. Add LLM authoring last, with retrieval and review. Treat FERPA / COPPA / GDPR as architecture, not as paperwork. Do that and you’ll be inside the 25% of EdTech ML projects that reach production. If you want a team that has shipped this pattern across BrainCert, Scholarly, ALDA and more, book a call and we’ll sketch the first three months.
Let’s integrate machine learning into your curriculum
21 years of AI and EdTech across 625+ products — including award-winning adaptive learning platforms. Book 30 minutes and walk away with a concrete first-feature plan, model family, and cost range.








