


Key takeaways
• Pick the cloning tier that matches the use case. Zero-shot (3–6s sample) for interactive agents, few-shot (1–3 min) for stable product voices, Professional Voice Cloning (30+ min) for audiobooks and broadcast.
• Sub-500ms end-to-end is achievable in 2026. Cartesia Sonic, Inworld TTS-1.5 Max and ElevenLabs v3 all hit sub-300ms time-to-first-audio; the bottleneck is usually your LLM, not the TTS.
• Consent and watermarking are architecture, not legal notes. The EU AI Act (Article 50), Tennessee ELVIS Act and Illinois BIPA each require written consent, provenance and disclosure — retrofit cost is brutal.
• Cost varies 10× across providers. Cartesia at ~$0.0005–$0.001 per 1k chars, ElevenLabs at $0.003–$0.015, OpenAI Realtime at ~$0.03 per minute. Self-hosted XTTS-v2 on an A100 breaks even at 3,000+ concurrent streams.
• Quality is a loop, not a launch. Speaker similarity (ECAPA-TDNN cosine ≥ 0.80), MOS ≥ 4.0, pronunciation error rate < 2% — measured weekly on a held-out sample set — is how you keep a voice product honest.
Real-time voice cloning went from research demo to production feature in two years. In 2026 you can drop a 3-second reference clip into a WebSocket endpoint and stream back near-perfect synthesized speech at 40–150 ms time-to-first-audio. That unlocks a category of products — AI call-centre agents, real-time dubbing, accessibility voice restoration, multilingual meeting translation, personalised assistants — that were impossible at this price a year ago. It also creates real risks: deepfake fraud, deepvoice scams, unlicensed impersonation. This guide walks through how to leverage the technology well: the decisions, the vendors, the compliance shape, the cost model and the pitfalls.
Target audience: CTOs, founders, product leads and engineering managers scoping a voice-cloning product — call-centre AI, accessibility tool, media dubbing, games NPCs, educational assistants. Everything below ties back to a real protocol, vendor, model or number; we deliberately keep cost estimates conservative.
Why Fora Soft wrote this playbook
Fora Soft has 21 years in real-time video, audio and AI engineering — 625+ shipped products, heavy concentration in voice, streaming and conversational AI. We’ve built custom voice pipelines using ElevenLabs, Cartesia, OpenAI Realtime, self-hosted XTTS-v2 and NVIDIA Riva across telemedicine, remote education, interpretation and customer support. We ship AI integration and custom video and audio processing products where latency budgets are measured in tens of milliseconds and compliance shape changes the architecture.
This playbook compresses what we learned on those builds, plus 2025–2026 research on production voice cloning, into a single reference you can hand to your engineering team or to a partner. If you want a second opinion on vendor choice, architecture or cost modelling, book a call at the end — our Agent Engineering workflow turns a proof-of-concept around fast and cheap.
Scoping a real-time voice product?
Tell us the latency target, language mix and compliance region. In 30 minutes we’ll sketch the right vendor, a realistic cost-per-minute and a 4-week proof-of-concept plan.
What “real-time voice cloning” actually means in 2026
Voice cloning generates speech in a target speaker’s voice from arbitrary text, conditioned on a reference sample. “Real-time” narrows that to latency budgets that support live conversation: sub-500 ms end-to-end for an agent that talks back while a human is still finishing their sentence, sub-1s for live dubbing, sub-3s for batched voiceover. Distinguish it from plain TTS (fixed library voices, no personalisation) and voice conversion (audio-in → same content, different voice, not generative).
| Tier | Sample needed | Typical speaker similarity | Best fit |
|---|---|---|---|
| Zero-shot | 3–6 seconds | 0.70–0.82 | Agents, NPCs, ephemeral user-facing clones |
| Instant / few-shot | 30–90 seconds | 0.80–0.88 | Brand voices, podcasts, educational tutors |
| Professional Voice Cloning (PVC) | 30+ minutes | 0.90–0.96 | Audiobooks, broadcast dubbing, celebrity licensing |
| Fine-tuned custom model | 8–16 hours | 0.95+ | Legacy brand continuity, long-running IP voices |
Reach for zero-shot when: your product needs to onboard a new speaker per session (NPC per player, customer voice for personalised IVR). Quality is good enough for conversational UX but not for audiobook-grade content.
Reach for few-shot when: the voice is a product asset that needs consistent personality — brand agents, tutors, permanent game characters. Worth the extra minute of sample capture.
Reach for PVC when: the output is distributed: audiobooks, dubbed films, YouTube series. Zero-shot never sounds broadcast-clean; PVC does.
Where real-time voice cloning actually earns its place
Not every product needs a cloned voice. The use cases where the ROI is unambiguous in 2026 cluster into a few categories.
AI call-centre agents. Replacing or augmenting tier-1 support with a 24/7 multilingual agent speaking in a consistent, pleasant voice — ideally one cloned from your top-performing human agent. Per-minute cost at 2026 managed pricing is pennies; the savings vs per-call outsourcing are immediate at mid-size call volumes.
Real-time dubbing and multilingual translation. Live translation of meetings, webinars, sport commentary with the original speaker’s voice preserved in the target language. CAMB.AI’s 2026 Paralympics work with Eurovision Sport is a marquee example. For the translation layer, pair voice cloning with the stacks we cover in real-time meeting translation and multilingual video-call translation.
Accessibility and voice banking. ALS, Parkinson’s and pre-operative patients record a 30–90 second sample that the system uses to restore their own voice on an AAC device or communication app. Deeply high-stakes; PVC-grade quality justified; consent/disclosure absolutely airtight.
Conversational avatars and assistants. Personal branding for influencers, custom voice for household assistants, multilingual customer support bots. Cartesia Sonic and Inworld TTS drive these at sub-200 ms latency.
Media localisation and voiceover automation. YouTube, TikTok, LinkedIn creator content, audiobook production, corporate training dubbing. Batched workflows are now fast enough that a creator can localise an hour of content in minutes.
Game NPCs with dynamic dialogue. Procedural dialogue trees voiced in real-time; previously prohibitive because of voice-actor costs. Now a few cents per NPC-hour.
Language-learning partners. A tutor voice that matches the learner’s dialect preferences, or a partner that corrects pronunciation interactively. Pair with ASR for closed-loop feedback.
AI call assistants and outbound sales. For the call-specific tech stack (VoIP bridging, latency budget, barge-in) see our AI call assistants API guide.
Vendor landscape: who leads on latency, quality and price
Pick the vendor by the three axes that actually matter to your product: time-to-first-audio, voice fidelity, and per-minute cost. Quality differences between the top tier are narrow; cost differences are huge.
| Vendor | Time-to-first-audio | Clone sample | Pricing signal | Best fit |
|---|---|---|---|---|
| ElevenLabs | 150–300 ms | 1–3 min (instant) / 30+ min (PVC) | ~$0.003–$0.015 per 1k chars | Quality-first products, broadcast, authenticity tooling |
| Cartesia (Sonic / Sonic Turbo) | 40–90 ms | 3 seconds (zero-shot) | ~$0.0005–$0.001 per 1k chars | Latency-critical agents, cost-sensitive scale |
| OpenAI Realtime / Voice Engine | 500 ms end-to-end | Custom voice with guardrails | ~$0.03 per minute (Realtime) | All-in-one ASR + LLM + TTS agents |
| Resemble AI | <500 ms | 5+ minutes | ~$0.005 per 1k chars | Enterprise voice cloning + fine-tuning |
| Respeecher | <1 s streaming | 30+ minutes broadcast-grade | Custom enterprise | Film, TV, high-end advertising |
| Camb.ai | <500 ms | Full reference clip | Enterprise | Live dubbing, sports, broadcast |
| Microsoft Azure Personal Voice | <500 ms | 1–2 minutes | ~$0.010–$0.025 per 1k chars | Azure ecosystem, HIPAA, enterprise |
| Google Chirp 3 / Custom Voice | 400–600 ms | Custom voice (preview) | ~$0.004 per 1k chars | GCP stacks, 90+ language breadth |
| Coqui XTTS-v2 (open-source) | 150–200 ms on GPU | 6 seconds | Self-host cost only | On-prem, privacy-constrained, captive deployments |
For the broader TTS vendor landscape (including non-cloning synthetic voices), see our best synthetic voice libraries for app development. For the upstream ASR and audio-processing tooling, the 7 best AI tools for audio apps maps the complete stack.
Reference architecture for a real-time voice-cloning product
A real-time voice-cloning product stitches four subsystems: capture, clone registry, synthesis pipeline, and delivery. A fifth — compliance — gates everything.
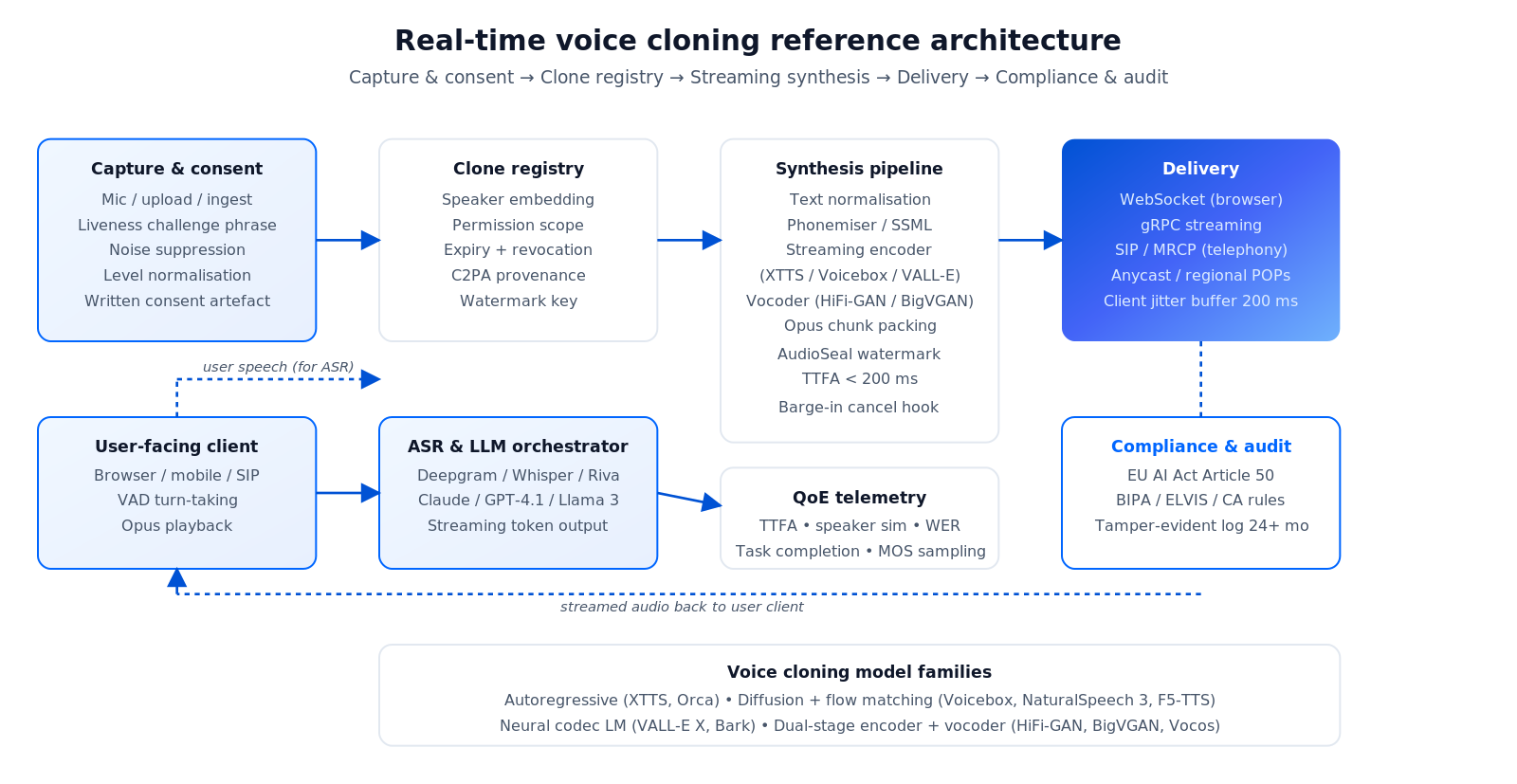
Figure 1 — Reference architecture: consent & capture → clone registry with watermarking → streaming TTS synthesis → delivery (WebSocket / gRPC / SIP) → consent / audit layer gating every request.
Capture and consent
Reference samples arrive via mic capture, uploaded audio, or content ingest (film, podcast, video). Every sample gets: explicit written consent, a liveness check where the speaker reads a dynamic phrase, PII scrubbing on metadata, and quality pre-processing — noise suppression, level normalisation, sample-rate unification to 24 kHz / 48 kHz, clipping detection, speaker-diarisation if multi-voice.
Clone registry
The registry stores: speaker embedding, permission scope (internal / external / distribution), expiry date, watermark key, provenance metadata (C2PA-compatible). Every inference request carries a clone ID and is gated against the registry — expired or revoked clones fail closed.
Synthesis pipeline
Text normalisation (numbers, dates, acronyms, URLs) → phonemiser / SSML pass → streaming encoder (autoregressive or diffusion-flow) → vocoder (HiFi-GAN, BigVGAN, Vocos) → opus-encoded chunks. Every chunk goes through an audio watermarker (AudioSeal, Perth, ElevenLabs AI Authenticity) before it leaves the server.
Delivery and barge-in
WebSocket for browser-to-server, gRPC for enterprise or telephony, SIP bridging for call-centre. On the client, a jitter buffer of 200–300 ms absorbs network variance. A server-side VAD detects user turn-taking and cancels in-flight TTS / LLM generation when the user speaks — barge-in is non-optional for real conversation.
Compliance layer
Every inference logs: caller, clone ID, text, timestamp, watermark, provenance. Audit log is tamper-evident (S3 Object Lock or equivalent), retained for 12–36 months depending on jurisdiction.
Model families actually powering production voice cloning
Autoregressive transformer (XTTS-v2, Orca, GPT-style TTS). Token-by-token generation, low latency (150–200 ms), naturally streamable. The default for real-time agents. Cheaper to serve, simpler to debug, minor repetition issues on very long outputs.
Diffusion + flow matching (NaturalSpeech 3, Voicebox, F5-TTS, MaskGCT). Highest quality and best emotional range; slower by default (200–500 ms) but catching up with accelerated sampling. The pick when broadcast-grade quality matters.
Neural codec language models (VALL-E X, Bark, Outlines-TTS). Predict discrete audio tokens with a GPT-style model; strong zero-shot from 3–6 seconds, excellent multilingual transfer. Slight artefacts from token quantisation.
Dual-stage encoder + vocoder (HiFi-GAN / BigVGAN / Vocos). The classic modular pipeline, still used by ElevenLabs v2 era models at huge scale. Well-understood, reliable, not natively streaming.
GPU sizing. A single A10 handles ~3–5 concurrent zero-shot clones at sub-300 ms latency; an A100 pushes that to 10–15; an H100 to 25+. Coqui XTTS-v2 on a consumer RTX 4090 runs 5–10 concurrent streams for homelab experiments. Call-centre deployments of 1,000+ concurrent agents need managed APIs or a dedicated GPU fleet.
Need to pick between Cartesia, ElevenLabs and self-host?
Share your expected concurrency, language mix and residency rules. We’ll give you a vendor recommendation and cost model in 30 minutes — grounded in production experience, not spec sheets.
Latency engineering: how to get under 500 ms end-to-end
In a voice agent the perceived latency is the full round-trip: user finishes speaking → ASR transcribes → LLM responds → TTS speaks. The TTS is rarely the bottleneck in 2026. The stack needs to overlap stages aggressively.
1. Streaming ASR. Deepgram, Whisper-streaming, NVIDIA Riva ASR return partial transcripts under 200 ms. Feed those into the LLM as they arrive.
2. Streaming LLM. 4-bit quantised Llama 3 8B or Claude Haiku stream first tokens in 150–400 ms. Avoid any model that doesn’t support streaming; it kills the budget.
3. Streaming TTS. As soon as the LLM emits a sentence-length chunk, push it into the TTS. Cartesia and ElevenLabs emit first audio in under 200 ms. Chunking at punctuation boundaries avoids mid-phoneme glitches.
4. Client buffer and VAD. 200–300 ms client-side buffer absorbs network jitter. Silero VAD detects user turn-taking in under 50 ms so the agent can stop speaking the instant the user resumes.
5. Regional endpoints. Anycast or regional deployment cuts 50–100 ms vs a single US endpoint. For global products, split APAC and EU into their own clusters.
For the ASR side of the pipeline, particularly in noisy environments, see our speech recognition in noisy environments guide and the speech-to-text live streaming tooling roundup.
Integration patterns: REST, WebSocket, gRPC, SIP
REST (batch). Post text, get an MP3 URL. Fine for voiceover, video dubbing, audiobook generation — anything where 5–15 seconds of wall time is acceptable. Simple to cache at a CDN.
WebSocket (real-time). Browser-native, firewall-friendly, sub-second time-to-first-audio. The default for web agents and conversational apps.
gRPC bidirectional streaming. Enterprise agents and telephony bridges. Lower overhead than WebSocket, strong typing, first-class in NVIDIA Riva and enterprise vendors.
SIP / MRCP bridging. For plugging into Asterisk, FreeSWITCH, Twilio Voice and other telephony stacks. Most voice-cloning vendors offer a direct SIP adapter; the ones that don’t require a media gateway on your side.
SSML and style tokens. Prosody, emotion, pitch, speed. ElevenLabs v3 and Cartesia accept per-chunk emotion tokens. Azure and Google support SSML. Keep the prompting pattern consistent across vendors so swap-in is cheap.
Compliance, consent and deepfake risk
Voice cloning is one of the fastest-moving regulated AI domains. The 2026 compliance picture: EU AI Act (Feb 2025 prohibition phase, Aug 2026 full enforcement, Article 50 on deepfake transparency), Illinois BIPA, Tennessee ELVIS Act, California synthetic-media rules, UNESCO ethics recommendations. Non-compliance is business-ending at the commercial side and potentially criminal at the personal side.
1. Written consent, not verbal. Every cloned voice needs a documented permission from the speaker — scope (internal / external / commercial distribution), expiry date, revocation procedure. Keep the consent artefact alongside the clone.
2. Voice liveness check. A dynamic challenge phrase at sample capture proves the speaker is the one in front of the mic, not a recording. Prevents consent-by-stolen-audio.
3. Watermarking and provenance. Imperceptible audio watermarks (AudioSeal, Perth, ElevenLabs AI Authenticity) plus C2PA Content Credentials on the audio file and the metadata. Detectability matters both for compliance and for recovering trust if a clip goes viral.
4. Disclosure on user-facing outputs. Article 50 requires “this audio was generated with AI” disclosure in most consumer deployments. Plan UX accordingly — subtle, but present.
5. Revocation. The speaker can turn the clone off. That requires a live registry check on every inference, not a one-time key.
6. US state-level rules. Illinois BIPA treats voiceprints as biometrics. Tennessee ELVIS Act protects likeness. California rules cover election / intimate imagery. If you sell into the US, expect to handle all three.
Cost model: a 1,000-agent call-centre worked example
Scenario. 1,000 concurrent agents, 8 hours/day, 20 working days/month — roughly 160,000 minutes of TTS synthesis per month, delivered through 20 distinct cloned voices.
| Option | Per 1k chars | Monthly cost (approx) | Trade-off |
|---|---|---|---|
| ElevenLabs (managed) | ~$0.003–$0.010 | ~$500–$1,600 | Highest quality, strong compliance tooling |
| Cartesia Sonic | ~$0.0005–$0.001 | ~$80–$160 | Lowest cost, best latency, narrower voice catalogue |
| OpenAI Realtime end-to-end | n/a (per-minute) | ~$5,000 (pay-per-minute) | Bundles ASR + LLM + TTS; simplest to integrate |
| Self-hosted XTTS / VALL-E | GPU-amortised | ~$15k–$30k (A100 fleet + ops) | Captive, private, breaks even past ~3k concurrent |
Add ASR (~$0.004/min on Deepgram), LLM (~$0.003–$0.03/min depending on model size), and ops. Realistic per-minute-of-call cost for a mid-tier stack: $0.02–$0.06. For reference, human offshore tier-1 agents cost ~$0.40–$1.00 per talk-minute, so even the expensive stack saves materially at mid-size call volumes. We keep these estimates conservative and re-price with live metrics after a 30-day pilot.
Quality metrics worth measuring every week
Speaker similarity. Cosine distance of speaker embeddings (ECAPA-TDNN or x-vectors). Target ≥ 0.85 for PVC, ≥ 0.75 for zero-shot. Falls when training data drifts or the clone misaligns to the speaker’s accent.
Mean Opinion Score (MOS). 1–5 human rating of naturalness. Target ≥ 4.0 for broadcast. Collect 20+ listeners per snapshot sample.
Word Error Rate (WER) on re-transcription. Run the synthesized audio back through ASR and compare to the input text. Target < 3% for broadcast, < 5% for agents. Catches pronunciation regressions fast.
Pronunciation error rate. Phoneme-level comparison. Target < 2% for multilingual deployments.
Time-to-first-audio (TTFA) p50/p95. p50 under 200 ms, p95 under 500 ms. Spikes usually indicate GPU contention or cold-starts on managed endpoints.
Emotion preservation. Human rating or an emotion-classifier comparison. Only matters in dubbing and narrative use cases; ignore for flat call-centre agents.
Mini case: a bilingual voice agent for an education platform
Situation. An e-learning client wanted a tutoring agent that spoke in a consistent “house” voice across English and Spanish, responded under 500 ms, and passed a faculty review loop before each new voice went to students. Deployed on top of their existing BrainCert-adjacent LMS.
What we built. Consent capture with liveness check, Professional Voice Cloning for the two house voices, Cartesia Sonic for streaming synthesis at <150 ms TTFA, Whisper-streaming ASR with custom vocabulary tuned to course jargon, a small Claude Haiku agent orchestrating dialogue with a RAG lookup over course materials. AudioSeal watermarking on every output. Faculty review UI to approve or revoke voices. Retention log with 24-month immutability for audit.
Outcome. End-to-end latency held under 450 ms in production. Faculty accepted 100% of reviewed voices for launch, revoked none after six months. Student engagement on the voice-tutor track lifted significantly over text-only; the bilingual house voice removed the friction of introducing a new synthetic face. Want a similar build? Book 30 minutes and we’ll walk the architecture.
A 12-week plan to ship your first voice-cloning product
Weeks 1–2 — Outcome, compliance shape, vendor shortlist. Lock the latency target, language mix, regulatory region and one primary KPI. Draft the consent flow and revocation mechanism. Shortlist two vendors.
Weeks 3–4 — Capture pipeline. Ship the sample-collection UI with liveness check, PII scrubbing, audio pre-processing and explicit consent artefacts. Standardise on 24 kHz stereo WAV with noise gate at −50 dB.
Weeks 5–7 — Voice registry and synthesis. Stand up the clone registry (expiry, scope, revocation), wire the streaming TTS API, chain ASR → LLM → TTS with overlap, validate TTFA under 300 ms on a dev corpus.
Weeks 8–9 — Watermarking and review UI. Add AudioSeal or equivalent; ship a reviewer dashboard where an admin approves/rejects new voices before they go live.
Weeks 10–11 — Barge-in and QA. Add VAD-driven interruption, soak-test for echo / barge-in regressions, measure speaker similarity and WER on a held-out set, fix regressions.
Week 12 — Pilot and rollout plan. Invite 5% of users; measure TTFA p50/p95, WER, MOS, revocation requests, legal incidents. Expand once signals are green.
Five pitfalls that sink voice-cloning rollouts
1. Poor reference audio. Noise, inconsistent sample rates, reverberation, uneven level — all drop speaker similarity from 0.88 to 0.65 overnight. Fix capture before you fix the model.
2. Shipping zero-shot for broadcast. A 3-second reference is enough for a call-centre agent but never enough for audiobook production. Use PVC where quality matters — and accept the 30-minute capture cost.
3. No barge-in. Users talk over the agent and get ignored. Voice products without interruption handling feel broken within seconds.
4. Missing consent or watermark. Regulatory and brand risk. One incident of an unauthorised clone being used for fraud and the product gets pulled. Consent plus watermark must be week-1 architecture.
5. GPU under-provisioning. Dev runs on one A10; production surge spikes to 1,000 concurrent agents; TTFA balloons, churn starts. Autoscale the GPU pool or price the managed API against realistic peak.
When you should not use a cloned voice
There are products that don’t need a clone: a generic TTS voice is fine, and simpler to compliance-prove. Don’t clone a voice when your users would be happy with ElevenLabs’ “Rachel” or Google’s Studio voices; don’t clone when you can’t obtain proper consent; don’t clone when the use case could be mistaken for impersonation (elections, legal communications, financial authorisation). Reach for cloning only when voice identity is a product feature — brand, accessibility, entertainment, localisation — and you control the consent loop.
A decision framework — pick your stack in five questions
Q1. Latency budget end-to-end? < 300 ms → Cartesia Sonic or Inworld. < 500 ms → ElevenLabs, OpenAI Realtime, Azure Personal Voice. < 3 s → batch REST on any major vendor.
Q2. Quality tier? Broadcast → ElevenLabs PVC or Respeecher. Product voices → ElevenLabs few-shot or Cartesia PVC. Ephemeral user clones → any zero-shot.
Q3. Regulatory region? EU → Article 50 disclosure, AudioSeal watermark, regional endpoints. US → BIPA / ELVIS / California coverage. APAC → local residency contracts; review each country.
Q4. Scale target in year 2? < 500 concurrent → managed API. 500–3,000 → managed API with volume commit. 3,000+ → evaluate self-hosted XTTS / Riva as the cost line flips.
Q5. Who operates the system? No dedicated ML ops → managed vendor end-to-end. Small ML team → managed TTS with in-house orchestration. Full ML platform team → DIY with open-source models.
Ready to ship a real-time voice product?
We’ve shipped custom voice pipelines across telemedicine, education, interpretation and customer support. Share your target use case and we’ll scope a 12-week build with conservative cost modelling.
KPIs: the four numbers that tell you the voice product is healthy
1. Time-to-first-audio p95. Target < 500 ms. The single metric that determines whether conversations feel natural.
2. Speaker similarity rolling average. Target ≥ 0.85. Falls when fine-tuning drifts, reference audio degrades or you switch vendors.
3. Task completion rate (agent products). Target ≥ 75% on defined intents. The business outcome that justifies the whole stack.
4. Consent incidents per 1k clones. Target zero. Revocation requests, legal complaints, provenance gaps — any of these spiking is a stop-the-line event.
FAQ
How much sample audio do I actually need?
3–6 seconds for zero-shot agent-quality clones. 30–90 seconds for stable brand / tutor voices. 30+ minutes of clean audio for Professional Voice Cloning. Quality of the sample matters more than raw length — noisy 5 minutes beats pristine 30 seconds only if both are properly processed.
Is real-time voice cloning legal?
Legal with proper consent, disclosure and provenance. Illegal for impersonation, unauthorised likeness use, election interference and most forms of fraud. The EU AI Act, Illinois BIPA and Tennessee ELVIS Act formalise the boundaries. Always build the consent flow first.
Which vendor has the best latency today?
Cartesia Sonic Turbo leads at ~40–90 ms time-to-first-audio, with Inworld TTS-1.5 Max close behind. ElevenLabs v3 clocks 150–300 ms with broader language support. For end-to-end agents, OpenAI Realtime wraps ASR + LLM + TTS at ~500 ms with a simpler integration footprint.
Can I self-host voice cloning?
Yes. Coqui XTTS-v2 and VALL-E X variants run on consumer GPUs (RTX 4090) for small scale and on A100 / H100 fleets for production. Self-host breaks even vs managed APIs around 3,000+ concurrent streams or for privacy-constrained deployments (healthcare, defence, legal).
What’s the minimum viable consent workflow?
Written consent document, dynamic challenge phrase during sample capture, expiry date on every clone, revocation button in the user’s dashboard, watermark on every output, tamper-evident log for 24+ months. Miss any of those and you’re one incident away from a crisis.
How do I handle multiple languages?
Pick a multilingual zero-shot model (XTTS-v2, ElevenLabs Multilingual v2, Cartesia Sonic, Camb.ai) for cross-lingual transfer from one reference sample. For highest fidelity per language, train per-language fine-tunes on the same speaker. Validate on accent variants, not just the dominant dialect.
How do I detect if a clip is a deepfake clone?
Three layers: watermark detection (AudioSeal / Perth / ElevenLabs AI Authenticity), provenance check (C2PA credentials), and a deepfake classifier (Resemble Detect, Pindrop, AI or Not). No single layer is perfect; the combination gets you to the 95+% detection bucket.
Can Fora Soft build a voice-cloning product for us?
Yes. We build voice pipelines end-to-end: capture, consent, clone registry, streaming synthesis, barge-in, watermarking, audit trails, compliance reviews. Typical scope is 8–12 weeks for a production pilot, 12–20 weeks for a full commercial deployment. Book a call to scope yours.
What to Read Next
TTS vendors
6 Best Synthetic Voice Libraries for App Development
The broader TTS landscape that sits alongside voice cloning.
Audio stack
7 Best AI Tools to Elevate Audio Apps
ASR, enhancement, denoising and the complete audio pipeline.
Interpretation
AI Interpretation Platform Development in 2026
The companion playbook for multilingual voice experiences.
Call centre
AI Call Assistants: Third-Party APIs for Business
VoIP bridging, barge-in and the telephony layer for cloned voices.
ASR
Speech Recognition Accuracy in Noisy Environments
The upstream ASR decisions that define the agent’s overall latency.
Ready to leverage real-time voice cloning in your product?
Real-time voice cloning is a shipped technology in 2026. Sub-300 ms time-to-first-audio is available from multiple vendors, quality is broadcast-grade in the PVC tier, and the unit economics work in call centres, accessibility, dubbing, games, education and media localisation. What separates a product that makes it to production from one that stalls in pilot is the four-layer discipline: pick the cloning tier that matches the use case, hit the latency budget with overlapping ASR/LLM/TTS, wire consent and watermarking as first-class architecture, and measure speaker similarity and WER on a weekly cadence.
If you want a team that has shipped this across telemedicine, education, interpretation and customer support — and that can give you a conservative cost model with a realistic 12-week timeline — book a call. Our Agent Engineering workflow gets the first production pilot in front of real users fast.
Let’s build your voice-cloning product
21 years of multimedia and AI engineering, 625+ products shipped. Book 30 minutes and walk away with a vendor recommendation, a realistic cost-per-minute, and a 12-week plan tailored to your use case.








