



An AI call assistant is a voice agent that answers or places phone calls, listens over a telephony line, runs a short language-model turn, and speaks back — all in under a second. In 2026 the market has settled around a handful of serious platforms, sub-$0.25/minute economics, and a compliance regime that actually bites: FCC TCPA rules on AI voices, and EU AI Act Article 50 disclosure obligations that go live August 2, 2026. This is a buyer’s playbook — what to pick, what to wire, what breaks in production, what it costs, and where to keep a human in the loop.
Fora Soft is a software development company that has shipped 250+ products since 2005, including voice assistants and chatbots for LMS, fintech, healthcare, and telecom since the first GPT-3.5 wave. We’ve wired Deepgram, ElevenLabs, OpenAI, Dialogflow, LiveKit, Twilio, and Azure Communication Services into production, and we built our delivery playbook around the pitfalls the blog posts skip: echo on PSTN, hallucinated bookings, STIR/SHAKEN attestation, and the 300 ms latency budget you blow the moment you add one misplaced tool call. Read this top to bottom and you’ll know which API to shortlist, how to architect it, and where a specialist team still pays for itself.
Key takeaways
• The stack is modular, not monolithic. Telephony, STT, LLM, TTS, and orchestration are separate layers — the “platform” you pick mostly decides which of them are locked in.
• Latency, not model quality, is the 2026 buying criterion. Voice-to-voice under 800 ms feels natural; the best stacks now land near 500 ms. Everything else is tuning.
• All-in cost is $0.13–$0.33 per minute. Vendor “$0.05/min” and “$0.07/min” rates are orchestration only — they exclude STT, LLM, and telephony. Budget on $0.20/min.
• Compliance is the hidden rewrite. The FCC’s 2024 TCPA ruling makes AI voices illegal in unconsented robocalls; EU AI Act Article 50 disclosure binds August 2, 2026; HIPAA and two-party-consent states pile on regional layers.
• Pick the platform last. Start from use case, volume, languages, and compliance envelope — then Vapi, Retell, Deepgram Voice Agent, a LiveKit build, or an enterprise path (Twilio, Azure, Google CCaaS) falls out naturally.
Why Fora Soft wrote this playbook
We’ve shipped voice AI in three places where the margin for error is thin: tele-health consultations (HIPAA-audited), financial-service call centers (two-party-consent states), and multilingual support desks (RU/EN/DE code-switching, often on the same call). Across those builds we kept a running log of what actually breaks in production — barge-in failures on G.711, DTMF lost across transcoders, LLM tool calls blocking TTS, and European regulators asking for the disclosure transcript six months after go-live.
This guide distills that log — the same discipline behind 250+ products we’ve shipped since 2005. It assumes you already know your business case — inbound support, outbound qualification, IVR replacement, appointment scheduling, or agent-assist copilots — and want a technical buyer’s map to a stack that will still compile in 18 months. It’s the same map we followed shipping HIPAA-audited voice flows for a US tele-health platform (CirrusMED) and real-time interpretation for Translinguist. If you’d rather skip the comparison and talk architecture, book a 30-minute review and bring a call recording.
Need a neutral second opinion on Vapi, Retell, or a build-your-own stack?
We’ll review your call flow, latency budget, and compliance envelope in 30 minutes and tell you which stack fits — no sales pitch.
What an AI call assistant actually is in 2026
An AI call assistant is a real-time conversational agent that terminates or originates PSTN/SIP audio, streams it through speech-to-text, feeds the rolling transcript into an LLM with tools, renders the reply via text-to-speech, and returns it to the caller — all under roughly 800 ms end-to-end. The newer generation (OpenAI Realtime, Gemini Live, Azure Voice Live) collapses STT, reasoning, and TTS into a single speech-to-speech model with around 300 ms time-to-first-byte from US endpoints, shifting latency out of your orchestration code and into the model provider.
Buyers are looking at three product shapes. Inbound answering agents deflect support volume and warm-transfer to humans on escalation. Outbound campaign agents qualify leads, book meetings, or run collections — a category the FCC reshaped with its February 2024 TCPA ruling that classified AI-generated voices as “artificial or prerecorded” and made them illegal for unconsented robocalls. Agent-assist copilots listen on human calls and whisper suggestions — the lowest-risk use case and a common first deployment.
If you only know the 2023 IVR-bot category, the delta is dramatic: turn latency is down 5–10×, ASR word error rate on noisy phone audio is under 6% with Deepgram Nova-3, and emotion-aware TTS (ElevenLabs v3, Hume EVI) cleared the uncanny valley for short interactions. If replacing a legacy phone tree is the specific job, our guide to AI IVR modernization covers containment and build-vs-buy for contact centers. Teams lifting a 2023 stack into 2026 usually rip out half their orchestration code as a side effect of the upgrade. The pipeline below is what replaces it.
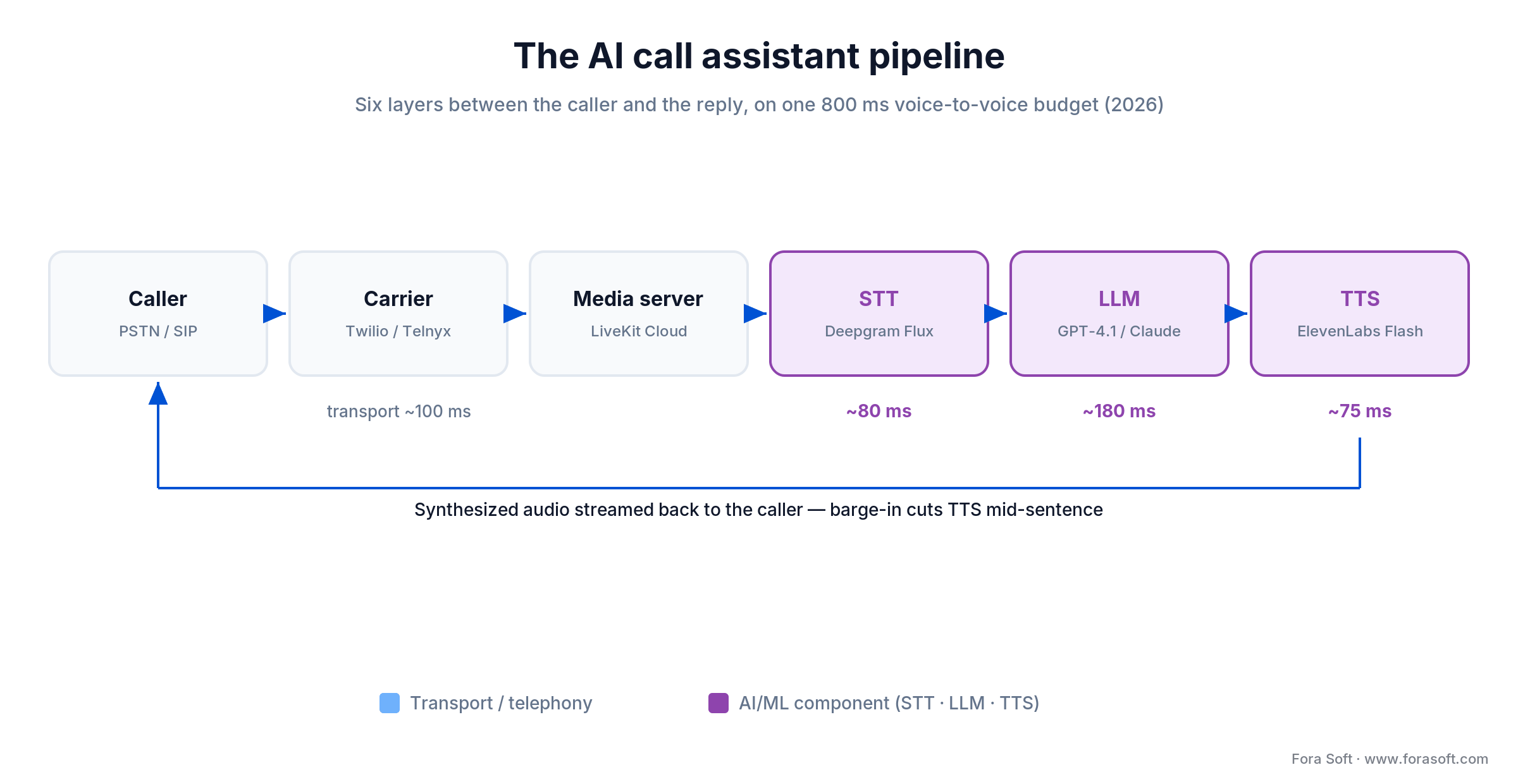
Figure 1. The six-layer pipeline every production AI call assistant follows — transport in blue, AI/ML components in purple.
The market snapshot: size, growth, and real deployments
Precedence Research put the call-center AI market at $3.23B in 2024 and $3.98B in 2025, heading for $25.84B by 2034 at a 23.11% CAGR. Gartner projects conversational AI in contact centers will save $80B in labor by 2026. Those are big-number forecasts, useful mainly as a sanity check that you’re not betting on a dying category — you’re not.
The number we point buyers at instead is Klarna’s 2024 disclosure: their AI assistant handled 2.3 million chats in its first month, about two-thirds of volume, cutting resolution time from 11 minutes to under 2, worth roughly 700 FTEs and about $40M in profit improvement that year. Here’s the catch worth stealing: in 2025 Klarna publicly rebalanced back toward human agents for the complex tail, where quality mattered more than deflection. That’s the shape that works — let the AI take the 70% of calls that are routine, and keep humans on the hard 30%. Every shortlist we build in 2026 starts with “can this stack handle 70% of call volume at equal-or-better CSAT.”
On the voice side specifically, the platform layer (Vapi, Retell, Bland, Synthflow, ElevenLabs Conversational AI) owns the template-and-prototype segment. Model-provider-native voice (OpenAI Realtime, Gemini Live, Azure Voice Live) is gaining share among teams already on those clouds. And enterprise CCaaS (Twilio + Conversational Intelligence, Amazon Connect + Lex, Google Dialogflow CX + Gemini, Azure Communication Services) still owns regulated industries where an SLA and a procurement path outweigh the last 150 ms of latency.
The API shortlist for 2026
Twelve APIs and platforms matter in 2026. Here’s the shortlist we use when scoping a build.
Voice-agent platforms (orchestration + telephony bundled)
1. Vapi. Orchestration-focused platform with a visual flow builder, bring-your-own STT/LLM/TTS, and strong barge-in. Headline $0.05/min orchestration; all-in $0.13–$0.31/min once you add components. A good default when you want flexibility and are comfortable wiring your own parts.
2. Retell AI. Tighter turnkey bundle: a flat $0.07/min platform fee (STT, verified numbers, branded calls, batch calling included) — but that excludes the LLM and telephony, so all-in still lands $0.13–$0.31. Strong outbound templates and a first-party LLM routing layer. If Vapi feels too DIY, Retell is the next step up. We put both head to head against a self-hosted build in our Vapi vs Retell AI vs custom comparison, including the volume where a managed platform stops being cheaper.
3. Bland AI. Bundled platform around $0.09/min plus monthly minimums, built for US outbound at volume. Strong call-queue management; weaker European voices. Our Bland AI alternatives and pricing guide breaks down its real per-minute cost.
4. Synthflow. No-code builder that appeals to non-engineers. We use it for internal tools and one-off pilots; it’s not our pick for production call volume.
5. ElevenLabs Conversational AI. End-to-end product wrapped around ElevenLabs’ voices, running Flash v2.5 for real-time turns. Pricing $0.08–$0.24/min by voice tier. Pick it when voice quality is the single most important feature (brand voice, consumer luxury IVR).
Model-provider speech-to-speech APIs
6. OpenAI Realtime API (gpt-realtime). Around 500 ms time-to-first-byte from US endpoints. Billed by audio token — $32/1M input, $64/1M output in 2026 — which works out near $0.30/min uncached and $0.05–$0.10/min with prompt caching. No bundled telephony; wire LiveKit or Twilio Media Streams. We cover it in depth in our OpenAI Realtime production guide.
7. Google Gemini Live. Multimodal speech-to-speech on Google Cloud, native in Dialogflow CX for CCaaS scenarios; strong multilingual coverage.
8. Deepgram Voice Agent API. Bundled ASR + LLM + TTS on Deepgram’s own Nova-3 (5.26% batch WER) and Aura-2 TTS — no pass-through billing surprises. The enterprise favorite when you need predictable cost. Deepgram’s newer Flux model folds end-of-turn detection into the transcriber, which fixes the interruption problem that wrecks most cascaded pipelines.
9. Azure Voice Live. Microsoft’s speech-to-speech offering, wired tightly into Azure Communication Services and Azure OpenAI. Pick it on Microsoft procurement or when you need Teams integration.
Enterprise contact-center platforms
10. Twilio (Voice + Conversational Intelligence). Full telephony stack with mature SIP, STIR/SHAKEN, and carrier SLAs. Effective all-in around $0.141/min for AI-agent flows on 10k-minute workloads.
11. Amazon Connect + Lex + Bedrock. AWS-native CCaaS; pay-per-minute PSTN plus service fee. Strong fit for teams already on AWS with regulated data.
12. PolyAI and Cognigy. Enterprise-only conversational platforms with in-house design teams. For when procurement wants one vendor carrying the SLA end to end.
Reach for a platform (Vapi / Retell) when: you want to ship in 4–8 weeks, you’re comfortable on a single integration seam, and call volume is under 1M minutes/month.
Reach for model-native speech-to-speech (OpenAI / Gemini / Azure Voice Live) when: latency is the single most important metric, you want fewer network hops, and you already run on the provider’s cloud.
Reach for an enterprise CCaaS (Twilio / Amazon Connect / Azure ACS) when: you’re in a regulated industry, you need carrier SLAs and STIR/SHAKEN attestation, and procurement won’t sign a startup contract.
Reach for build-your-own (LiveKit + Deepgram + OpenAI/Claude + ElevenLabs) when: none of the platforms fit your latency budget or custom tooling surface — typically healthcare, defense, financial, or anything with an on-prem requirement.
Comparison matrix — what you actually pay and ship
All figures below are the all-in effective rate we see in deployments (telephony + STT + LLM + TTS + orchestration), not the vendor’s headline rate. Voice-to-voice latency is the median on a warm US connection.
| Platform | All-in $/min | Latency | Best for | Watchouts |
|---|---|---|---|---|
| Vapi | $0.13–$0.31 | ~900 ms | BYO stacks, rapid prototyping | Price varies by components |
| Retell AI | $0.13–$0.31 ($0.07 platform) | ~800 ms | Outbound, tight bundled flow | $0.07 excludes LLM + telephony |
| ElevenLabs Conv. AI | $0.08–$0.24 | ~850 ms | Brand voice, consumer IVR | Voice cost at premium tier |
| OpenAI Realtime | ~$0.30 ($0.05–$0.10 cached) | ~500 ms TTFB | Low latency, tool-call heavy | Need BYO telephony |
| Deepgram Voice Agent | $0.12–$0.22 | ~700 ms | Predictable billing, high-accuracy STT | TTS voice library smaller |
| Twilio Voice + AI | ~$0.141 | ~1,100 ms | Carrier SLA, STIR/SHAKEN | Slower iteration loop |
| BYO LiveKit stack | $0.15–$0.25 | ~600 ms | On-prem, custom tooling, HIPAA | Highest engineering cost |
The reference architecture (six layers, one latency budget)
Every production AI call assistant we’ve shipped follows the same pipeline, whatever the vendor:
Caller PSTN/SIP → Tier-1 carrier (Twilio / Telnyx / Vonage / SignalWire)
→ Media server (LiveKit Cloud / FreeSWITCH / Asterisk)
→ STT stream (Deepgram Nova-3 / Flux / Whisper-v3)
→ LLM turn (GPT-5.5 / Gemini 3.1 / Claude Sonnet 4.6 + tool-calling)
→ TTS stream (ElevenLabs Flash v2.5 / Cartesia Sonic / Aura-2)
→ Back to PSTN/SIP
Latency budget (voice-to-voice target = 800 ms):
STT first-partial 120 ms
LLM turn (with tools) 450 ms
TTS first chunk 130 ms
Network / media server 100 ms
=====
~800 ms
Two choices dominate. First, stream everywhere: don’t buffer a complete utterance before sending — push STT partials into the LLM and push LLM tokens into TTS as they arrive. Second, one media server: don’t cross two WebRTC peers or transcode twice. Every extra hop is 40–80 ms and a fresh chance for audio artifacts.
Want a reference implementation that handles SIP trunking, jitter buffers, and barge-in out of the box? We’ve been shipping on LiveKit since 2024 — the same pipeline for agents that also handle video and screen share is in our Building Multimodal AI Agents with LiveKit guide and the deeper LiveKit for AI agents course.
The latency budget — where 800 milliseconds goes
Voice-to-voice latency is the buying criterion, so budget it like money. Human turn-taking research puts the natural response gap near 200 ms, with anything up to 500 ms still feeling conversational. Phone callers tolerate a little more, so 800 ms voice-to-voice is a safe production target and the 2026 best-in-class stacks land near 500 ms. Here’s where the milliseconds go.
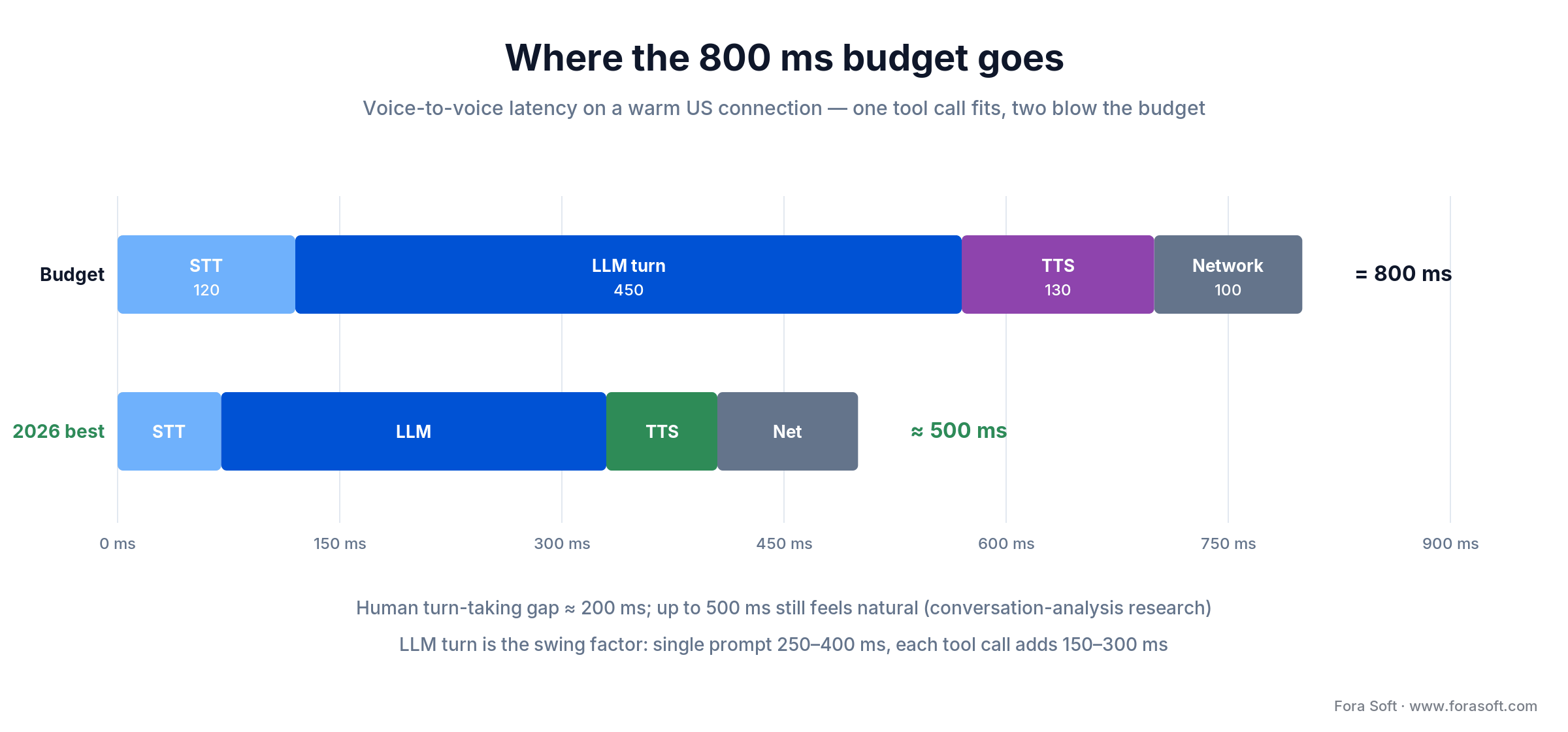
Figure 2. The 800 ms budget broken out by stage, with a 2026 best-in-class stack for comparison.
1. Speech-to-text (~120 ms). Deepgram Nova-3 streaming returns first partials in about 60–140 ms. Whisper-v3 is slower (200–300 ms) but higher accuracy on clean speech. Nova-3 Multilingual handles code-switching across ten languages on the same call — a real requirement for European and APAC deployments.
2. LLM turn (~450 ms). Most of your budget. A single-turn prompt with no tool call comes back in 250–400 ms from a fast model. Each tool call adds 150–300 ms. Two tool calls blow the budget — design for one, or pre-fetch context before the caller finishes speaking.
3. Text-to-speech (~130 ms). ElevenLabs Flash v2.5 streams a first chunk in about 75 ms; Cartesia Sonic in 40–90 ms. Reserve the expressive ElevenLabs v3 for pre-rendered audio — it’s not built for real-time. You can shave another 50 ms by preloading the first word before the LLM finishes.
4. Network, media server, jitter buffer (~100 ms). The tax on real-time audio. LiveKit Cloud runs under 100 ms in most regions; a self-hosted FreeSWITCH on the same VPC as your app, under 60.
5. Barge-in detection. Not part of the response-time budget, but the difference between a natural call and a robot. You need voice-activity detection on the inbound audio that cuts the TTS mid-sentence when the caller starts talking. LiveKit ships one; Deepgram Flux folds end-of-turn detection into the transcriber; Vapi and Retell handle it at the platform level.
Voice-to-voice latency over 1.2 seconds?
Send us a recording and a trace — our voice team ships a written diagnosis of where your 400 ms is hiding within 48 hours.
STT leaders and word-error-rate math
Deepgram published a real-world benchmark across medical, finance, and call-center audio where Nova-3 lands at 5.26% WER batch and 6.84% streaming, a 54.2% streaming WER reduction versus the prior best. The March 2026 Nova-3 Multilingual update cut batch WER a further ~34% and streaming ~21% across languages, with 10-language code-switching inside a single call.
The 2026 shift is Deepgram Flux: a conversational-STT model that bakes end-of-turn detection and configurable turn-taking into the transcriber at Nova-3 accuracy. That matters because interruptions — the caller talking over the agent — are what break most cascaded pipelines, and bolt-on VAD never quite nails the handoff. If you’re building fresh in 2026, evaluate Flux before you wire a separate VAD.
OpenAI Whisper-v3 is competitive on clean US English but degrades on accented or noisy phone audio. AssemblyAI Universal-2 is close to Nova-3 on English and behind on multilingual. Our rule of thumb: if your calls include non-native English speakers or regional accents, switch to Nova-3 Multilingual. The WER delta on accented phone audio is large enough to move CSAT, and the price difference is marginal. We proved that out on Translinguist, where accented-speaker accuracy decided the vendor. For the deep version of this, see our speech recognition playbook for noisy phone audio.
TTS leaders and the “uncanny valley” test
ElevenLabs Flash v2.5 is the real-time workhorse: ~75 ms latency across 32 languages, and good enough on short customer-service turns to clear the uncanny valley for most listeners. ElevenLabs v3 (GA March 14, 2026) is more expressive — Audio Tags, 68% fewer complex-text errors, 70+ languages — but it’s a larger model that isn’t built for real-time, so keep it for pre-rendered prompts, not live turns.
Cartesia Sonic is faster still (40–90 ms first chunk) and slightly behind on emotional delivery. It’s the best pick when your latency budget is very tight.
OpenAI TTS (gpt-realtime voice) is the default when you’re already on OpenAI Realtime — good enough for most support flows, noticeably flatter than ElevenLabs on emotional turns. Deepgram Aura-2 and PlayHT round out the shortlist: Aura-2 wins on predictable bundled billing, PlayHT on per-voice brand control.
One compliance note: if you operate in the EU, keep the voice recognizably synthetic. From August 2, 2026 the EU AI Act Article 50 requires you to tell the user they’re talking to AI — a pleasant-but-clearly-synthetic voice makes that disclosure honest and the lawsuit less likely.
Choosing the LLM — latency, tool-calling, and grounding
Voice agents live or die on three LLM traits: turn latency, tool-calling reliability, and grounding on short retrieval chunks. The counter-intuitive part: the frontier model is rarely the right voice model. Retell, which runs 40M+ calls a month, reports that GPT-4.1 is the default production voice LLM in 2026 because it balances low first-token latency, a 1M-token context window, and reasonable per-minute cost — not because it tops any leaderboard.
For latency-critical inbound, GPT-4o-mini (~120–150 ms first token) and Claude Haiku 4.5 (~100–150 ms) are the fast lane. Reserve the frontier tier — GPT-5.5, Claude Opus 4.8, Gemini 3.1 Pro — for the reasoning that actually needs it.
Claude Sonnet 4.6 handles long, policy-heavy multi-turn conversations more reliably than GPT-4o, so it’s our pick when the agent makes or confirms non-trivial bookings, billing adjustments, or medical-schedule changes — slightly slower, safer. Gemini 3.1 Flash is the price/performance leader for simple inbound and multilingual flows, and the natural default if you’re already on Google Cloud. Whichever you pick, wire the model layer so you can swap it — the “best” voice model changed twice in the last year.
Telephony — SIP trunks, STIR/SHAKEN, and why it matters
The telephony layer is where most build-your-own projects fall over, and the failures are boringly consistent: the wrong codec on the trunk (echo), the wrong caller-ID on outbound (low answer rate), or no STIR/SHAKEN attestation at all (calls flagged “likely spam” before they connect).
STIR/SHAKEN is the US caller-authentication standard the FCC enforces on PSTN outbound. If your trunk provider can’t attest your caller-ID, answer rates drop 30–60%. Tier-1 carriers (Twilio, Telnyx, Vonage, SignalWire) attest by default; generic VoIP resellers often don’t. This one detail derails more outbound projects than any model choice.
On codecs, the US PSTN default is G.711 μ-law at 8 kHz. Wideband (Opus/G.722, 16 kHz) improves STT accuracy noticeably — but only if both legs of the call are wideband, which in practice means SIP-to-SIP.
Compliance — TCPA, EU AI Act, HIPAA, two-party consent
US — TCPA and STIR/SHAKEN. The FCC’s February 2024 declaratory ruling classified AI-generated voices as “artificial or prerecorded” under the TCPA. Translation: cloning a voice for outbound robocalls without prior express written consent is illegal, with statutory damages per call. Your campaign playbook needs consent proofs and cadence limits, and STIR/SHAKEN attestation on the outbound dial tone. Our outbound AI calling software guide walks through building that campaign playbook TCPA-compliant.
EU — AI Act Article 50. Transparency obligations apply from August 2, 2026: if the call touches an EU person, disclose at the start that they’re interacting with an AI system. The May 2026 AI Omnibus agreement gives generative systems already on the market until December 2, 2026 to meet the machine-readable marking requirement of Article 50(2). Penalties reach the €15M-or-3%-of-turnover band for transparency breaches. Build the disclosure into the greeting prompt and log the recording.
Healthcare — HIPAA. You need a signed BAA with the platform vendor, encryption in transit and at rest on recordings and transcripts, audited access controls, and a documented data flow into EHR systems (Epic / Cerner). Retell, Deepgram Voice Agent, Twilio, and AWS Connect carry BAAs; Vapi and the Tier-1 LLM providers require individual negotiation.
US states — two-party-consent recording. Eleven states (CA, CT, FL, IL, MD, MA, MT, NV, NH, PA, WA) require all parties to consent to recording. Practical default: disclose and get consent at the start of every call regardless of state, and log the timestamp of the consent audio segment.
GDPR. Voice is personal data. Minimize raw-audio retention (we usually delete within 30 days unless contracted otherwise), classify transcripts and PII separately, and expose a data-subject-request endpoint in your admin tooling from day one.
Cost model — what 30,000 minutes a month actually costs
A typical mid-market deployment is 10,000 calls × 3-minute average = 30,000 minutes a month. On a standard bring-your-own stack (LiveKit + Deepgram Nova-3 + a fast frontier LLM + ElevenLabs Flash v2.5) the component cost per minute breaks down like this:
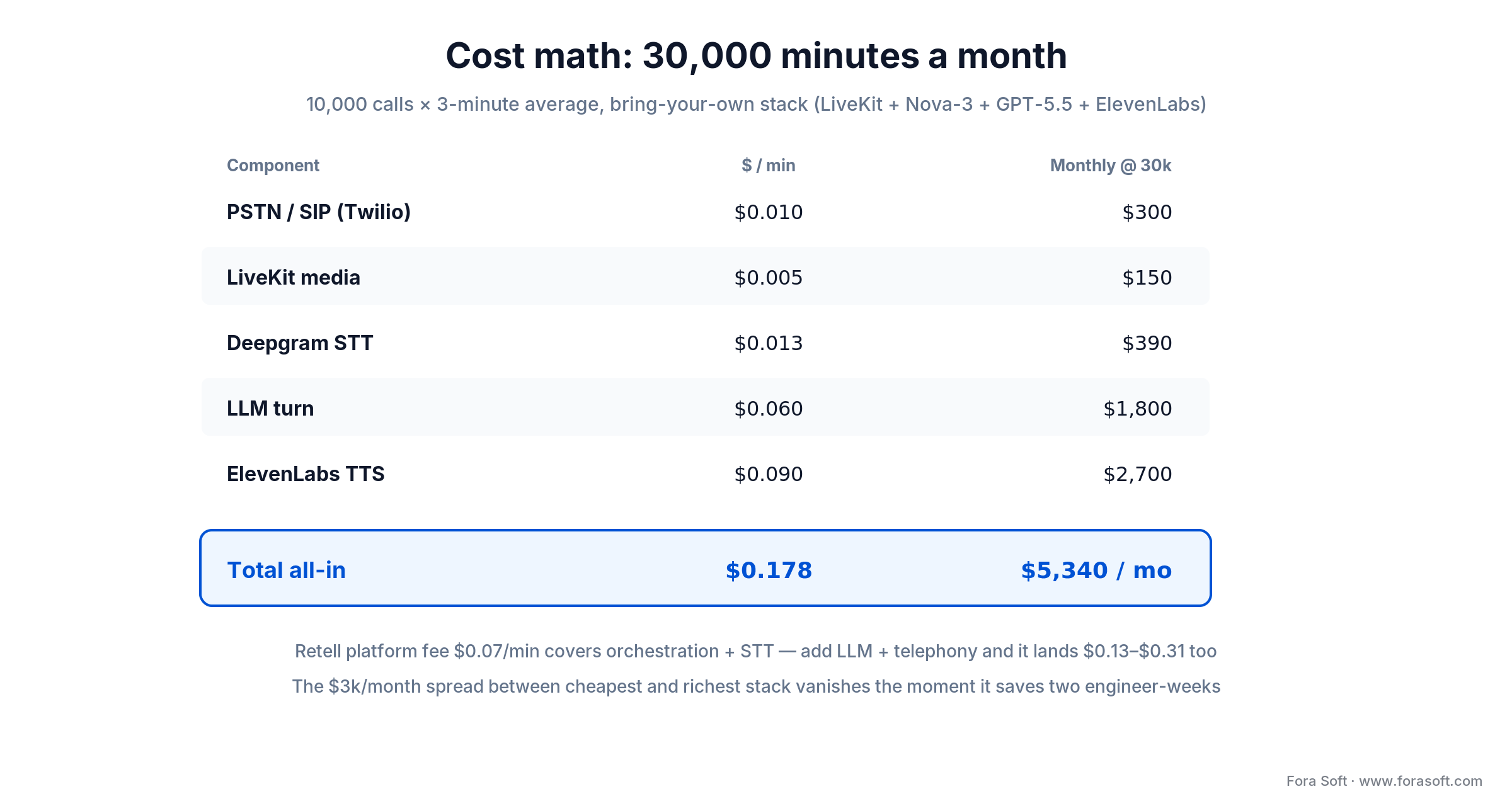
Figure 3. A worked bring-your-own cost model at 30,000 minutes/month — the LLM and TTS dominate.
| Component | $/min | Monthly @ 30k min |
|---|---|---|
| PSTN / SIP (Twilio) | $0.010 | $300 |
| LiveKit media | $0.005 | $150 |
| Deepgram STT | $0.013 | $390 |
| LLM turn (fast frontier) | $0.060 | $1,800 |
| ElevenLabs TTS | $0.090 | $2,700 |
| Total all-in | $0.178 | $5,340 |
Swap ElevenLabs for OpenAI Realtime with prompt caching and you can push the model+voice line under $0.10/min; swap it for premium ElevenLabs and you push past $0.30. Retell’s $0.07/min platform fee covers orchestration and STT but not the LLM or telephony, so it lands in the same $0.13–$0.31 band once complete. The spread between the cheapest and richest path is roughly $3k/month per 30k minutes — which almost always disappears the moment the pricier path saves you two engineering weeks of orchestration work.
Mini case — HIPAA tele-health, 12-week plan, before/after
Situation. A US tele-health platform with 120 clinicians ran appointment reminders and pre-call intake through a human call center. Cost per outbound reminder was $1.20, and 38% of calls never completed because patients hung up on the IVR. They wanted an AI assistant that could handle reminders, reschedule on request, and escalate to a human for anything clinical.
12-week plan. Weeks 1–2: BAA signed with Deepgram Voice Agent and Twilio; HIPAA audit scope defined. Weeks 3–6: Epic integration via FHIR, call flows for reminder/confirm/reschedule, human escalation to the existing agent desk. Weeks 7–9: pilot on 5% of volume, tuning ASR on accented speakers and barge-in timing. Weeks 10–12: rollout to 100%, two-party-consent disclosure on every call, PHI redaction in stored transcripts.
Outcome. Cost per reminder dropped from $1.20 to $0.34 (72% lower). Completion rose from 62% to 87%, because the AI could answer the “what is this call about?” question the legacy IVR couldn’t. Rebook rate improved 19 points. Zero HIPAA findings on the first audit. It’s the same pattern behind our CirrusMED healthcare work. Want a similar assessment for your stack? Book a 30-minute review.
Want this cost model run against your call volume?
Bring your minutes, languages, and compliance envelope — we’ll return a stack shortlist and a per-minute number you can take to finance.
A decision framework — pick the stack in five questions
Q1. What’s your call volume? Under 100k minutes/month, a platform (Vapi, Retell, Synthflow) carries you. Over that, the engineering cost of a bring-your-own stack amortizes fast.
Q2. Inbound, outbound, or agent-assist? Outbound at volume forces STIR/SHAKEN, consent proofs, and TCPA exposure. Agent-assist skips most of it. Inbound is the middle ground.
Q3. Languages and accents? Serving non-English speakers or code-switching makes Deepgram Nova-3 Multilingual the default; Whisper-v3 is viable for clean high-resource languages. Monolingual English is wide open.
Q4. Regulation? HIPAA, PCI, GDPR, EU AI Act, US state two-party consent — each forces vendor choices, and BAA-capable vendors are a small subset. Document this first, pick platform second.
Q5. Speech-to-speech or pipeline? Speech-to-speech (OpenAI Realtime, Gemini Live, Azure Voice Live) is faster but less observable. Pipeline (STT → LLM → TTS) is easier to debug, swap, and log — still our default for regulated production.
Five pitfalls that kill AI call deployments
1. Echo on PSTN. G.711 μ-law carries far-end audio back into the near-end mic path. Without active echo cancellation the LLM hears itself and loops. Fix: enable AEC on the media server and validate on every SIP trunk you add — don’t trust the vendor default.
2. Hallucinated bookings. The agent confirms a Tuesday 3pm that isn’t in the calendar. Fix: never let the LLM commit a transaction from its output alone. Make the tool call, wait for the 2xx, and read the real confirmation back to the caller.
3. Tool-call timeouts. External APIs (CRM, calendar, billing) go slow; the LLM blocks and TTS stalls. Fix: set a hard 700 ms timeout on every tool and prepare a filler utterance (“one moment while I pull that up”) the agent speaks while waiting.
4. Bad escalation handoff. The human picks up cold with no context. Fix: generate a one-sentence call-context summary on escalation, pass it with the transfer, and play the last caller utterance into the human’s softphone.
5. Missing consent and disclosure. The first EU AI Act Article 50 lawsuit will be a greeting that never mentioned AI. Fix: bake disclosure into the first TTS utterance, log the transcript with a timestamp, and store it for the retention window your regulator mandates.
KPIs — what to measure on day one
Quality KPIs. Word error rate on your own call corpus (target < 8%), containment rate (share of calls resolved without a human), CSAT on post-call SMS (target ≥ 4.3 / 5), and hallucination rate on booked actions (target 0%). Run it weekly against 200 random human-labeled calls.
Business KPIs. Cost per resolved call (versus the human baseline), abandonment rate versus legacy IVR (target −30%), conversion on outbound (benchmark against human agents), and upsell rate on inbound (AI often beats humans here for mid-market).
Reliability KPIs. Voice-to-voice p50 and p95 latency (targets ≤ 800 ms and ≤ 1.4 s), tool-call p95 latency, barge-in detection lag (target ≤ 150 ms), and PSTN error rate (SIP 5xx). These are the ones that wake you at 3am.
Build vs buy — the only useful checklist
The whole decision reduces to three questions in order — volume, regulation, latency. Answer them and the stack falls out.
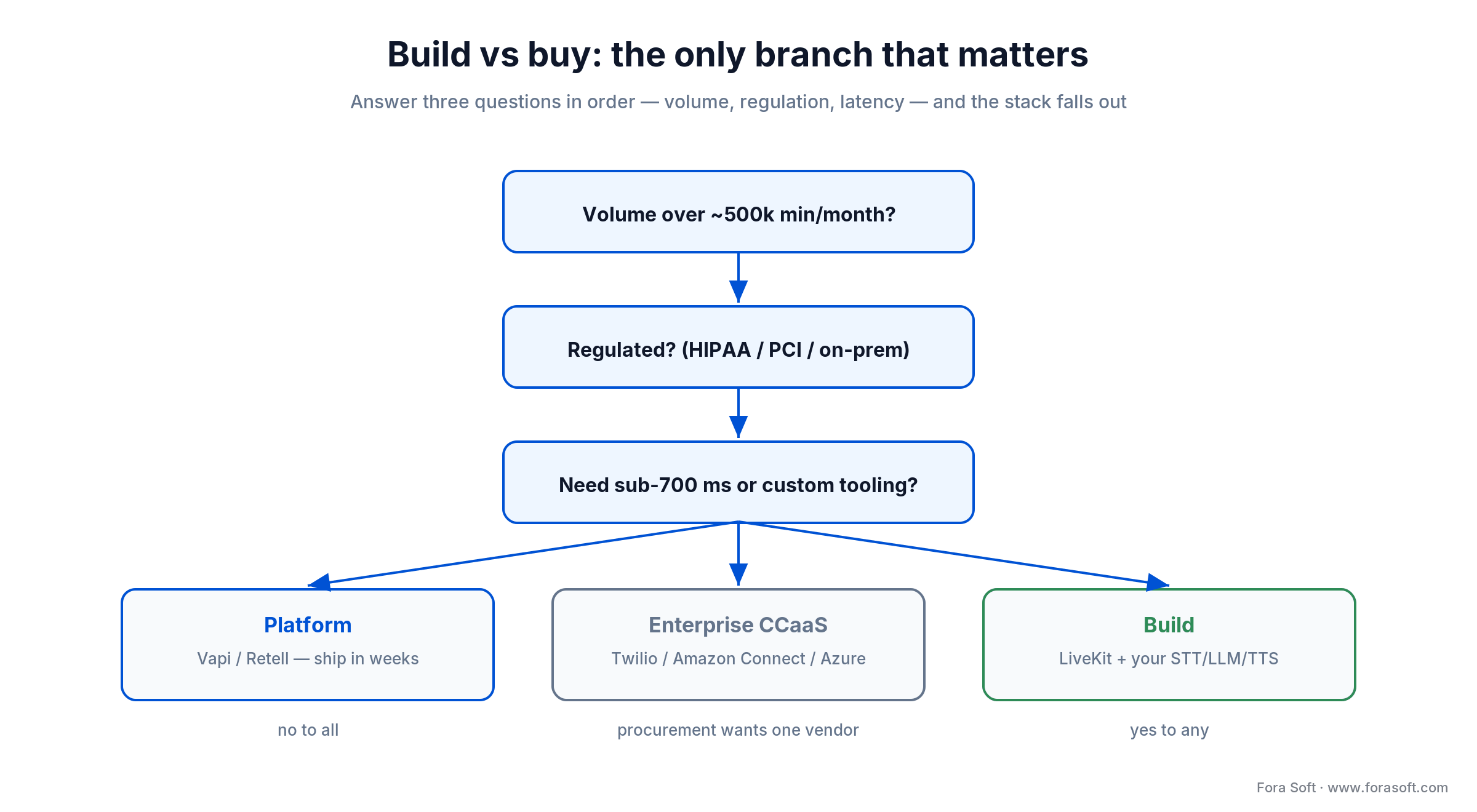
Figure 4. The build-vs-buy branch: three questions route you to platform, CCaaS, or custom build.
Buy a platform (Vapi, Retell, Synthflow, ElevenLabs Conversational AI, Bland) when your call flow is broadly industry-standard, volume is under ~500k minutes/month, you have under four weeks to first production traffic, you’re fine with orchestration-layer lock-in, and your compliance envelope is narrow (no HIPAA, no PCI, no on-prem).
Build (LiveKit + Deepgram + OpenAI/Claude/Gemini + ElevenLabs/Cartesia) when you’re over that volume, in a regulated industry, need custom tool-calling against internal systems (EHR, core banking, dispatch), want your own observability and a swap-able model layer, or your latency budget is under 700 ms. That’s where our AI integration services tend to earn their keep.
Buy an enterprise CCaaS (Twilio, Amazon Connect + Lex, Dialogflow CX + Gemini, Azure Communication Services) when procurement requires a single Tier-1 vendor, you’re already on their cloud, or your service desk already runs on their platform and you want the AI layer bolted on rather than rebuilt.
When not to deploy an AI call assistant
Don’t deploy when the call is the most valuable customer interaction. High-touch B2B sales, clinical diagnosis, grief counseling, and high-value account management still beat AI on retention and NPS — and the reputational risk of a failure dwarfs the savings. For those, an agent-assist copilot is the right level.
Don’t deploy when you can’t instrument. If you can’t measure containment, CSAT, and hallucination rate weekly, the agent drifts silently and you find out via a customer-complaint tweet six weeks later. Observability comes first, deployment second.
Don’t deploy where the regulator hasn’t ruled. Some jurisdictions are still writing AI-voice law — if the compliance team can’t point at a specific statute or guidance, pilot agent-assist first and wait on the customer-facing rollout.
Planning a voice agent rollout in a regulated industry?
We’ve shipped HIPAA, GDPR, and TCPA-compliant voice deployments since 2023. We’ll map your compliance envelope and stack in one call.
Industries shipping value with AI call assistants in 2026
Healthcare. Appointment reminders, pre-call intake, post-visit follow-up, benefits verification. HIPAA-audited vendors only; BAAs non-negotiable. Tele-health platforms see 60–70% cost-per-call reduction.
Financial services. Inbound account status, collections (heavily regulated), mortgage intake, insurance first-notice-of-loss. Recording rules, PCI for card data, and state consumer-protection layers all apply.
EdTech and LMS. Enrollment, course advising, exam scheduling, attendance. Low regulatory overhead, high multilingual requirement — a good fit for Vapi or Retell at moderate volume, and the world we know well from platforms like BrainCert.
Logistics and field service. Dispatch confirmation, appointment windows, reschedules, cancellations. High tool-calling volume against dispatch systems; the real-time calendar is the critical integration.
Real estate. Lead qualification, showing scheduling, tenant screening. Outbound-heavy, so TCPA exposure matters more here than in most verticals.
Retail and e-commerce. Order status, returns, post-purchase upsell — often delivered omnichannel (voice + SMS + chat), one reason platforms with multichannel surfaces (Twilio, Zendesk AI agents) win this segment.
A 12-week deployment playbook
Weeks 1–2. Compliance scoping (HIPAA, GDPR, TCPA, state consent), vendor BAA / DPA signed, one call flow selected, KPIs agreed with the business.
Weeks 3–5. Integrate one backend system (CRM or calendar), write the disclosure greeting in every language, finalize the tool-calling schema, tune barge-in.
Weeks 6–8. Pilot on 5–10% of volume, calibrate daily against 50 human-labeled calls, measure latency p95, dial in the escalation handoff.
Weeks 9–11. Scale to 50%, add a second call flow, implement PII redaction on stored transcripts, run the first compliance dry run.
Week 12. 100% rollout, KPI dashboard live, weekly calibration cadence set, pilot post-mortem, roadmap for the next two flows.
FAQ
What is an AI call assistant in 2026?
An AI call assistant is a real-time voice agent that terminates a PSTN/SIP call, transcribes audio with a speech-to-text model, reasons with an LLM (usually with tool-calling), and speaks a reply via text-to-speech — all in under 800 ms end-to-end. Modern systems also handle barge-in, escalation to human agents, and multilingual code-switching on the same call.
Which API should I pick — Vapi, Retell, or OpenAI Realtime?
Vapi for bring-your-own-stack flexibility. Retell for a tighter bundled outbound flow. OpenAI Realtime for the lowest latency, when you’re comfortable wiring your own telephony (LiveKit or Twilio Media Streams). For regulated industries or high volume we default to a LiveKit + Deepgram + Claude Sonnet 4.6 + ElevenLabs build.
What does an AI call assistant actually cost per minute?
Vendor headline rates are $0.05–$0.10/min for orchestration only. All-in — including STT, LLM, TTS, and telephony — the real range is $0.13–$0.33/min depending on model choices. A standard bring-your-own build lands near $0.18/min; OpenAI Realtime runs about $0.30/min uncached and $0.05–$0.10 with prompt caching.
Is it legal to use AI voices on outbound calls in the US?
Since the FCC’s February 2024 declaratory ruling, AI-generated voices are “artificial or prerecorded” under the TCPA. You need prior express written consent for outbound AI calls to consumers, plus STIR/SHAKEN attestation on your trunk. Without those, you’re exposed to statutory damages per call.
Does the EU AI Act apply to my voice bot?
If the call touches an EU person — yes. Article 50 transparency obligations apply from August 2, 2026 and require clear disclosure that the user is interacting with an AI system; the May 2026 Omnibus gives systems already on the market until December 2, 2026 for machine-readable marking. Disclose in the greeting, log the transcript, and keep the recording.
How do AI call assistants handle multiple languages?
Deepgram Nova-3 Multilingual handles 10-language code-switching inside a single call, with roughly 34% lower batch WER than the previous generation. Whisper-v3 supports more languages but is slower and less accurate on phone audio. Most LLMs respond correctly in the detected language without extra configuration.
Can AI call assistants transfer to a human agent?
Yes — warm transfer is the default. The AI passes a one-sentence context summary plus the last caller utterance to the human agent’s softphone before the handoff completes. That preserves state and kills the “say it all again” problem that wrecks CSAT on legacy IVR.
How long does an AI call assistant project take?
A basic platform pilot ships in 2–4 weeks. A production-grade bring-your-own build with one business-system integration and one language runs 8–12 weeks. Multi-language, regulated deployments with several escalation paths run 3–5 months.
Read next
AI receptionist
How to build an AI receptionist
Put a voice API to work answering your phones: the stack, real per-minute costs, and build vs buy.
OpenAI Realtime
OpenAI Realtime API: Production Voice Agents
Token costs, latency traps, and the wiring for a production speech-to-speech agent.
Architecture
Building Multimodal AI Agents with LiveKit
The reference architecture for voice + video agents we deploy in 2026.
STT
Speech Recognition Accuracy in Noisy Environments
How to squeeze sub-8% WER from phone audio in real deployments.
Services
AI Chatbot & Voice Assistant Development
How Fora Soft builds voice and chat agents end to end.
Ready to ship an AI call assistant that actually converts?
The 2026 stack is mature: sub-800 ms latency is reachable with any serious platform, Deepgram Nova-3 and Flux handle real-world phone noise and interruptions, ElevenLabs Flash v2.5 clears the uncanny valley in real time, and compliance paths for HIPAA, TCPA, GDPR, and the EU AI Act are well-trodden. The decisions that still matter are use case, volume, regulated envelope, and whether speed-to-market or control-over-stack pays off better for you.
Shipping a pilot this quarter? Pick Vapi or Retell, wire Nova-3 for ASR and Flash v2.5 for voice, set an 800 ms p50 target, and run a 5% pilot against a human baseline. Heading into a regulated industry or north of a million minutes a month? Budget a 10–12-week LiveKit build with your own STT/LLM/TTS selections and real observability from day one. Either path reaches production — the difference is whether you’re renting infrastructure in 18 months or owning it.
Either way, Fora Soft has shipped the pattern you’re about to build. Bring a call recording, a flow diagram, and your compliance envelope; we’ll return a stack shortlist, a cost model, and a 12-week delivery plan.
Ready to architect your AI call assistant, end to end?
30 minutes with our voice engineering lead: stack, compliance, cost model, and a 12-week delivery plan.








