



Key takeaways
• Agora ships the last mile of RTC, not the AI you want to sell. Emotion detection, live translation, background replacement, conversational agents and AR filters all live in the custom layer on top of the SDK.
• The work happens at the frame observer. registerVideoFrameObserver and registerAudioFrameObserver are the two hooks where roughly 80% of custom AI effort lands.
• Budget $40–300K, plus inference and battery engineering. Light AI features start around $40–80K; multi-party translation and empathetic voice push past $160K. Run-cost is per-minute, not per-seat.
• You compose a pipeline, not a vendor. Agora Conversational AI Engine, OpenAI Realtime, LiveKit Agents, Deepgram and Cartesia slot together cleanly in 2026.
• Agent Engineering trims 30–40% off the scaffolding. SDK wiring, token services and channel plumbing get faster; the Metal shaders and NNAPI delegates still need a senior human.
Short answer: in 2026, shipping an AI-powered mobile app on Agora.io means owning three layers the default SDK doesn’t hand you: a custom video-frame pipeline, a custom audio-frame pipeline, and an AI orchestration layer that plugs third-party models (OpenAI Realtime, Deepgram, Cartesia, Hume, MediaPipe, or your own) into live calls without wrecking latency, battery or call quality.
This playbook is written for the CTO or product lead of an AI mobile app development company that has already picked Agora, or is about to. It covers what the custom layer actually contains, what it costs in 2026, where it breaks on real devices, and when a different RTC vendor (LiveKit, Daily.co, 100ms) is the smarter call.
Why Fora Soft wrote this Agora playbook
We’ve built video and real-time communication products since 2005: 250+ projects, 50 in-house engineers, and more than a decade of shipping custom frame pipelines on iOS and Android. When an AI mobile app development company asks us to add captions, translation or an in-call agent to an Agora build, we’re not reading the docs for the first time. We’ve debugged the 50 ms jitter that only shows up on a Snapdragon 7 Gen 1, and we’ve watched a demo that felt instant on office Wi-Fi fall apart on LTE.
One example that keeps paying off: VALT, our video management platform, now serves 770+ US organizations and 50,000+ users with custom frame processing and evidentiary storage under HIPAA. It isn’t Agora-based, but the discipline is what transfers: keeping inference off the render thread, hardening reconnect logic, gating AI behind feature flags. That carries into every Agora AI build we take on.
The rest of this guide is that discipline written down: the architecture, the numbers, the honest trade-offs, and the parts we’d hand to a different vendor without blinking.
Building an AI feature on top of Agora?
We’ve shipped custom frame processors, conversational agents, translation pipelines and AR filters on Agora. In 30 minutes we’ll tell you what’s realistic in your timeline — and what isn’t.
What Agora ships out of the box in 2026
Agora’s default stack is good, and it’s worth being precise about what you already get before you pay anyone to build more:
- Video SDK with codec auto-negotiation (H.264, VP8, VP9, AV1 where the device supports it), bitrate adaptation and simulcast.
- Voice SDK with AI noise suppression, echo cancellation and network adaptation.
- Signaling and Real-Time Messaging for chat, presence and call setup.
- Cloud Recording (composite and individual), plus Media Push and Media Pull for server-side routing.
- Virtual Background (segmentation with blur or image replacement).
- Conversational AI Engine for dropping an AI agent into a call, billed at $0.10 per minute (Agora pricing, 2026).
That covers maybe 60–70% of an AI app’s RTC needs. The remaining third, the part that actually differentiates your product, is custom work. The diagram below shows where the SDK stops and your engineers start.
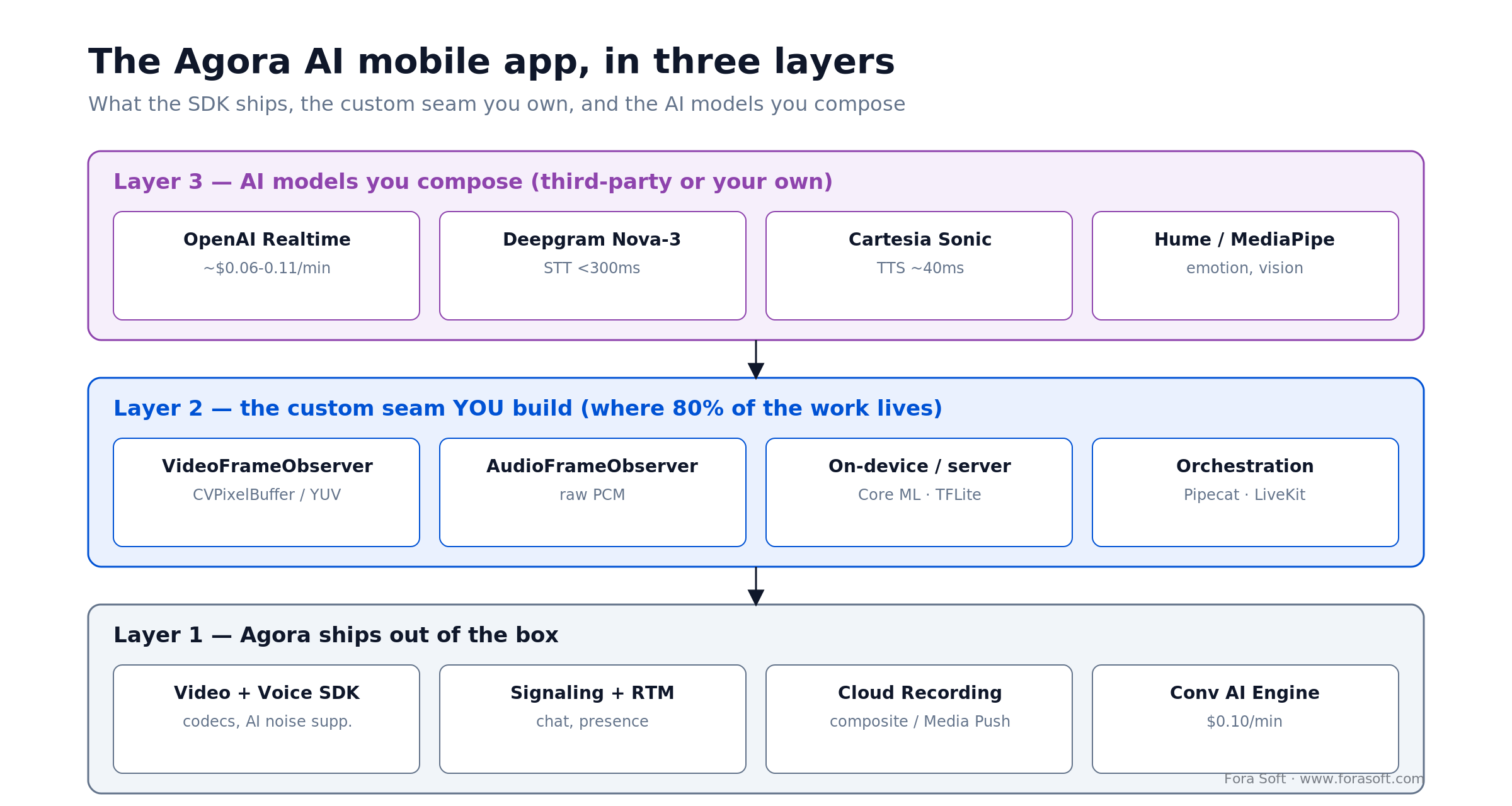
Figure 1. Agora handles transport; you own the frame-observer seam; the AI models sit on top and get swapped as vendors improve.
Where the default SDK stops and custom work starts
The moment you want anything AI-flavored that Agora doesn’t ship, you’re in custom-dev territory. The honest list:
- Custom video-frame processing. Register a
VideoFrameObserver, grab theCVPixelBuffer(iOS) or YUVbyte[](Android), run it through Core ML / TFLite / MediaPipe, then push the processed frame back. This is the seam where custom visual AI lives. - Custom audio-frame processing. Register an
AudioFrameObserver, route raw PCM to a transcription, emotion or noise-suppression model, and feed audio back into the call. We build a lot of this in our custom video and audio processing work. - Third-party AI integrations. Wiring Deepgram, AssemblyAI, Hume, OpenAI Realtime, Cartesia or TwelveLabs into live streams without latency stacking out of control.
- Server-side pipelines. Media Push out, FFmpeg, a GPU inference service, and a path back into the channel via Media Pull.
- AR filters. Banuba, DeepAR or Snap Camera Kit, each with its own texture pipeline to bridge into the frame observer.
- Live moderation, spatial audio and custom conversational agents. Agora’s engine handles the plumbing; your agent logic and policy are still yours to build.
The AI integrations we build most on Agora
Across Agora AI projects, the same seven features come up again and again. Here’s the typical stack, a realistic build cost, and the thing that actually bites you in QA.
| Feature | Typical stack | Build cost | Watch out for |
|---|---|---|---|
| Real-time transcription + captions | AudioFrameObserver → Deepgram / AssemblyAI → caption overlay | $12–30K | WER on non-English, diarization, sub-600 ms finals |
| Live translation | STT → translation API → Cartesia TTS → back via Media Push | $30–70K | Latency stacking; budget under 1.5 s end-to-end |
| Emotion / sentiment detection | Hume AI (voice) + MediaPipe FaceLandmarker (video) | $25–60K | Bias testing, consent flows, battery drain |
| Background blur / replacement | VideoFrameObserver → MediaPipe Selfie Segmentation → Metal/Vulkan | $15–40K | Edge halos on hair, GPU thermals on long calls |
| AR filters | Banuba / DeepAR SDK → VideoFrameObserver bridge | $20–60K + license | Licensing tiers, asset pipeline, low-end perf |
| In-call conversational agent | Agora Conv AI Engine or OpenAI Realtime via Media Push; Pipecat / LiveKit Agents | $40–120K | Barge-in, turn-taking, per-minute LLM cost |
| Live AI moderation | Cloud Recording → Hive / Sightengine → review dashboard | $15–50K | GARM alignment, false-positive queue |
Reach for captions first when: you need a shippable AI feature this quarter with a small budget. Real-time captions are the lowest-risk entry point — one audio observer, one STT vendor, no video pipeline — and they teach your team the frame-observer discipline everything else depends on.
Three architecture patterns that actually ship
Every Agora AI feature is a choice about where the model runs. There are three patterns, and the right one depends on model size and your latency budget.
1. Full on-device pipeline. Frame observer → on-device model (MediaPipe, Core ML, TFLite) → push the processed frame back. Latency sits at 10–30 ms, which is why it wins for background blur, AR filters, voice-activity detection and wake-word. The cost is heat: without Metal or Vulkan optimization, a face-ML model will cook a mid-range phone in ten minutes.
2. Sidecar server pipeline. Media Push streams the call to your server, FFmpeg plus a GPU inference service processes it, and results return via Media Pull or a companion channel. This is the only sane home for heavy models — Whisper Large, a 70B LLM, high-quality diarization. Latency lands at 300–1,200 ms depending on network and model.
3. Hybrid. Cheap models on-device (VAD, segmentation, wake-word, light emotion), heavy models server-side (large LLMs, diarization, translation). This is our default for anything shipping to consumer iOS and Android at scale. It’s more code, but it’s the only pattern that stays both fast and affordable.
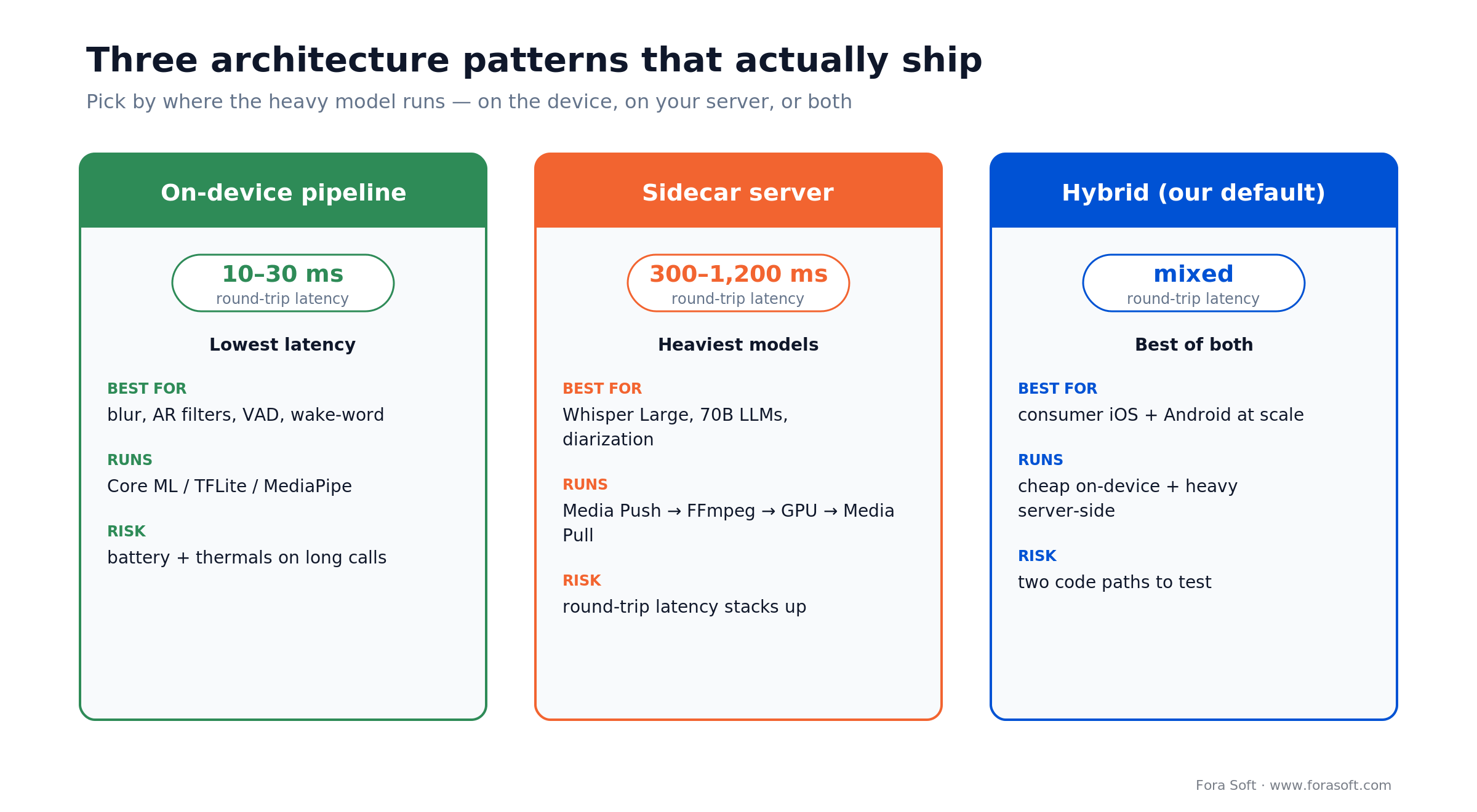
Figure 2. The three patterns side by side — pick by where the heavy model has to run.
Reach for the hybrid pattern when: your app targets both a $150 Android phone and a flagship iPhone, and the feature set mixes light effects with a real LLM. Nine times out of ten that’s the consumer reality, and hybrid is the only pattern that survives it.
The latency budget for a call that still feels human
A conversation with an AI agent starts to feel natural under about 700 ms round-trip, and excellent under 400 ms. The trick is that no single service is “the slow one” — latency is the sum of five stages, and any one of them going long ruins the feel.
Here’s a realistic breakdown with current numbers: Deepgram Nova-3 (released February 2025) streams partial transcripts under 300 ms across 36 languages; Cartesia Sonic returns its first audio chunk in roughly 40 ms; OpenAI’s Realtime API, generally available since August 2025, produces a first token in the low hundreds of milliseconds. No single service is the bottleneck; the sum is.
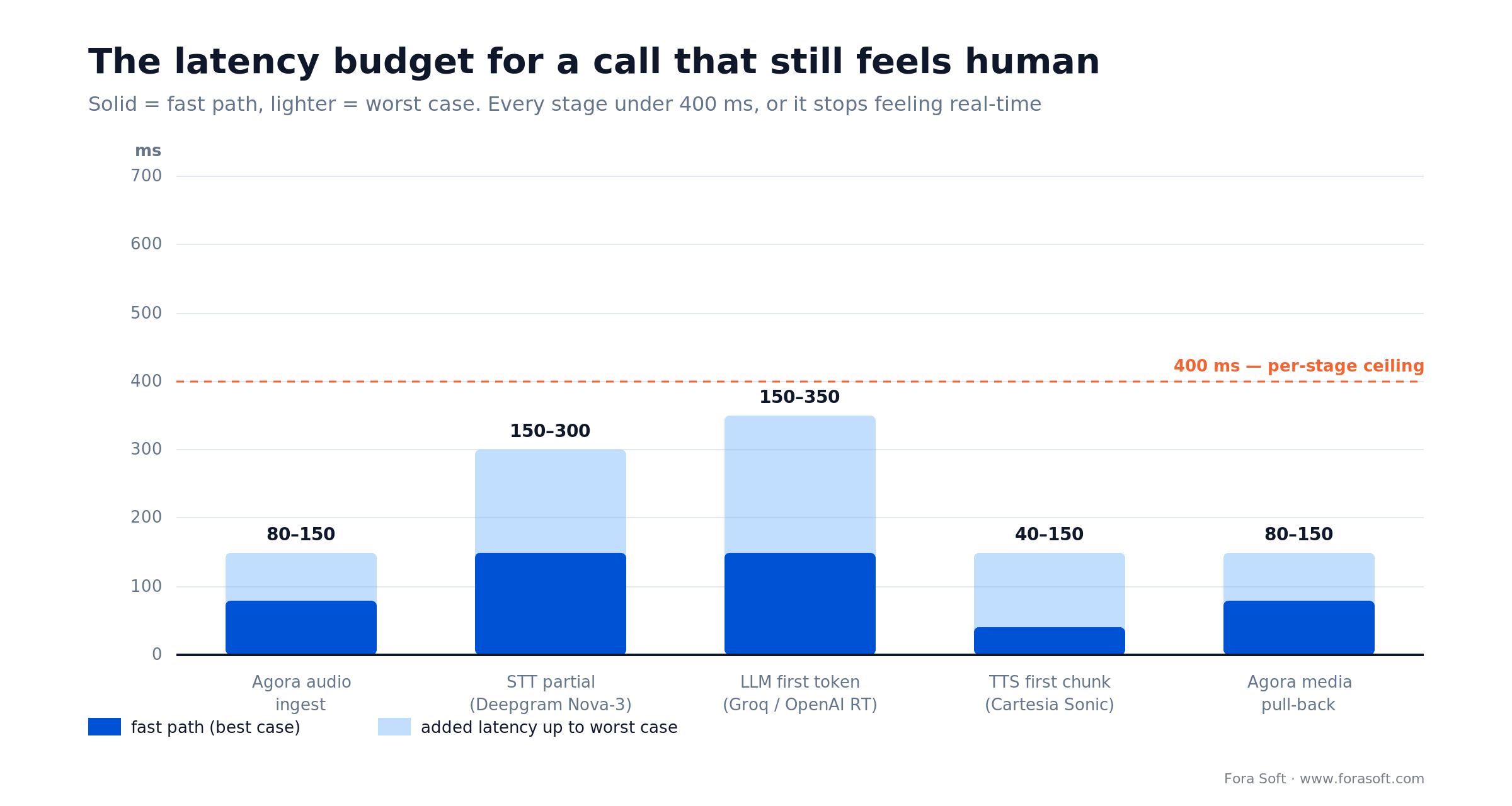
Figure 3. Round-trip latency, stage by stage. Solid bars are the fast path; the lighter caps show the worst case you have to design against.
Field rule: measure your round-trip from the far end of the WAN, never from a laptop on office Wi-Fi. A demo that feels instant on a 20 ms LAN routinely loses 250–400 ms on mobile LTE, and that’s exactly where your paying users sit.
Platform specifics that matter
The frame observer looks the same in the docs across platforms. It is not the same in practice. If your team is weighing one codebase against two, our cross-platform video app guide goes deeper; the short version:
- iOS:
CVPixelBuffer,AVAudioEngine, models through Core ML (use the Apple Neural Engine where you can), compositing with Metal Performance Shaders. Watch for CIKernel-induced latency spikes. - Android:
SurfaceTexture,MediaCodec, TFLite with GPU/NNAPI delegates, Vulkan for composition. Custom frame work exposes hardware variance brutally — test on cheap devices early. - React Native: the official Agora plugin covers basic calls and some frame-observer work via native modules. Anything advanced needs your own TurboModule in Swift/Kotlin.
- Flutter: the community plugin is mature for basic calls; custom frame processing needs platform channels bridging to native code.
- Web:
MediaStreamTrackProcessor+ WebCodecs + ONNX Runtime Web run on Chromium; Safari lags, so plan fallbacks. For the fundamentals, our digital video primer is a solid grounding.
Realistic 2026 cost model
Build cost scales with how much AI you’re adding and where it runs. These are the bands we quote in 2026, built on Agent Engineering rather than a blended day rate — which is why our floors sit below what a traditional agency quotes for the same scope.

Figure 4. Build-cost tiers. Solid bars are the floor, lighter caps the ceiling; run-cost sits on top and is billed per minute.
Now the worked example. Say you run a moderate-AI app — captions plus an in-call agent — with 2 million conversation minutes a month. Agora video at $3.99 per 1,000 minutes is $7,980. Streaming STT at roughly $0.005 per minute adds $10,000. An agent on OpenAI Realtime at about $0.08 per minute (flagship, with prompt caching) adds $160,000. Run the arithmetic: $7,980 + $10,000 + $160,000 = $177,980 a month, and the LLM is 90% of it. That’s the whole point — on a chatty agent, inference dwarfs the RTC bill, so you model per-minute LLM cost first and everything else second. The mini and cached-prompt paths (full breakdown here) can cut that figure by half or more.
Negotiating tip: Agora’s list price is a starting point, not a quote. Any team doing more than 100M minutes a year can negotiate meaningfully off list (see current rates). Get that number before you lock your unit economics, because it moves your break-even by months.
Not sure which tier your app actually needs?
Send us the feature list. We’ll map it to a build band and a per-minute run cost, and flag the one line item that’ll blow your budget.
Agora vs the alternatives for AI mobile apps
Agora isn’t the only RTC vendor, and for some products it isn’t the best one. If you’re still choosing a platform — or choosing an AI mobile app development company that has a favorite — here’s the honest field, side by side.
| Vendor | Best for | AI orchestration | Watch out for |
|---|---|---|---|
| Agora | Low-bandwidth reliability, APAC/China reach, one SDK across six platforms | Conversational AI Engine ($0.10/min) or Media Push to your own stack | Custom AI still lives in the frame observer |
| LiveKit | Self-hosting; orchestration-first products | Agents framework 1.0 (Apr 2025), native MCP; runs ChatGPT voice mode | You own the infra you self-host |
| Daily.co | OpenAI Realtime from day one | Pipecat (Daily’s open-source Python framework, v1.0 Apr 2026) | Smaller global edge footprint than Agora |
| 100ms | South Asia, price-sensitive builds | Maturing AI feature set | Newer, thinner ecosystem |
| Amazon Chime SDK | Teams already deep in AWS, US-centric | Do-it-yourself | No batteries-included AI path |
| Twilio Video | Existing Twilio shops | Do-it-yourself | EOL announced then reversed (2024); weigh the roadmap wobble |
We compare the two front-runners on real per-minute economics in our LiveKit vs Agora cost analysis. In short: Agora wins when you need excellent low-bandwidth handling, strong APAC and China coverage, predictable pricing, and one SDK across iOS, Android, Web, React Native, Flutter and Unity.
LiveKit or Daily win when your team leans open source, the orchestration is the core of the product, or you’re building on OpenAI Realtime from day one.
The 2026 real-time AI stack, composed
Nobody builds the whole thing in-house anymore. You compose. The stack we ship most often on Agora looks like this:
- RTC: Agora Video + Voice SDK.
- STT: Deepgram Nova-3 or AssemblyAI for streaming; Whisper Large V3 server-side when accuracy beats latency.
- LLM: OpenAI Realtime for native turn-taking, Groq + Llama for cost, Claude via Bedrock or Vertex for quality.
- TTS: Cartesia Sonic for sub-100 ms, ElevenLabs for voice cloning, Azure Neural TTS for language breadth.
- Emotion: Hume AI for voice, MediaPipe FaceLandmarker for facial expression.
- Orchestration: LiveKit Agents, Pipecat, or our own middleware — whichever fits the integration surface. Our LiveKit Agents playbook covers that layer end to end.
Because these are composed, you swap parts as vendors improve. When a faster TTS ships, you change one adapter, not your architecture. That’s exactly what our AI integration service is built around.
The team you actually need
A custom Agora AI build is not a job for two generalist mobile devs. The roles that matter:
- Senior iOS engineer (Core ML, Metal, AVFoundation). Non-negotiable.
- Senior Android engineer (NDK, TFLite, Vulkan, MediaCodec). Non-negotiable.
- ML engineer focused on mobile model optimization — quantization, pruning, delegate tuning. Our note on hiring computer vision developers covers what to screen for.
- Backend engineer for the token service, session management, Media Pull/Push and agent orchestration.
- DevOps/SRE for GPU inference infrastructure and observability.
- QA with a device farm — the cheapest insurance you can buy against low-end Android surprises.
Mini case: what a large surveillance platform taught us about frame pipelines
Situation. VALT is a video management platform we’ve been the sole dev team on for over a decade — 770+ US organizations, 50,000+ users, HIPAA-grade evidentiary storage, and custom frame pipelines under constant load. It’s not built on Agora, but the failure modes are identical to the ones an Agora AI app hits.
What transferred. Three lessons show up on every Agora build we do since. First, frame observers must never block the SDK’s own render loop — everything runs on a dedicated Metal or Vulkan queue. Second, reconnect logic is 20% of the code and 80% of the bugs; we test it on flaky LTE, not on Wi-Fi. Third, feature flags around each AI feature save you from an app-store rollback when a new model underperforms in the wild.
Outcome. That mental model is the reason our Agora AI builds don’t hit week-12 surprises: the reconnect and threading work is done before the first AI feature lands. If you want our architect to walk your team through the same discipline on your pipeline, grab a 30-minute slot and bring your topology.
A 16-week plan for an AI-powered Agora app
- Weeks 1–2. Agora App ID and token service, signaling, baseline one-to-one call on iOS and Android.
- Weeks 3–4. VideoFrameObserver + AudioFrameObserver plumbing; a Core ML / TFLite inference test rig.
- Weeks 5–6. First AI feature (usually captions or blur), full end-to-end on both platforms.
- Weeks 7–8. Second AI feature (emotion, translation or AR); thermal and battery profiling.
- Weeks 9–10. Conversational agent via Conv AI Engine or OpenAI Realtime; Media Pull/Push pipeline.
- Weeks 11–12. Cloud Recording and moderation; feature flags and analytics.
- Weeks 13–14. Low-end Android QA, weak-network testing, consent and privacy flows.
- Weeks 15–16. Staged rollout, on-call runbooks, SRE alarms on latency and inference cost.
A decision framework: pick your RTC vendor in five questions
Before you commit an AI mobile app development company to a vendor, answer these five. They decide the build more than any feature-matrix ever will.
1. Is the AI agent the product, or a feature? If the agent is the whole product, LiveKit Agents or Daily + Pipecat give a cleaner orchestration story than bolting onto Agora.
2. Where are your users? Heavy APAC or China traffic, or spotty networks, tilt hard toward Agora’s low-bandwidth handling.
3. Do you have to self-host? Tight regulatory constraints (government, defence, strict data residency) point to self-hosted LiveKit, not a managed CPaaS.
4. What’s your latency ceiling? A sub-400 ms conversational agent forces on-device or edge inference; a captioning app can tolerate a server round-trip.
5. Who maintains it in year two? The frame-observer code is the hard part to hand off. If you don’t have senior iOS and Android in-house, budget for a partner who does. That’s the honest reason most teams call us.
Stuck between Agora and LiveKit?
Walk us through your five answers above. We’ll tell you which vendor fits — even when the answer isn’t us.
KPIs that tell you the pipeline is healthy
Three buckets, with thresholds we hold builds to before they ship.
Quality KPIs. End-to-end audio latency under 700 ms P50 and 1,200 ms P95. STT partials under 300 ms, LLM first token under 350 ms, TTS first chunk under 150 ms. Transcription WER under 10% English, under 18% for major non-English languages.
Reliability KPIs. Frame-drop rate on custom video under 2% P95. Audio jitter under 30 ms. Call-join success above 99.3%. These are the numbers that quietly decide whether users trust the feature.
Business KPIs. Battery drain under 10% per 30-minute call on a mid-range phone. Moderation false-positive rate under 5% with a human review queue. Inference cost per minute tracked per feature, so one chatty agent can’t sink your margin unnoticed.
Five pitfalls we clean up on new Agora AI projects
1. Token security done client-side. Embedding the App Certificate or minting tokens in the app is the most common thing we rip out. Always mint server-side with the right RTC role and a short expiry.
2. Inference on Agora’s thread. Running a model on the SDK’s own frame-callback thread tanks frame rate. Hand off to a dedicated GPU/CPU queue, always.
3. Battery blindness. On-device ML without quantization, without an FPS cap for face tasks, and without pausing when the call is backgrounded, will drain a phone and earn one-star reviews.
4. Background transitions. iOS kills the audio session after 30 seconds backgrounded unless you implement the right background modes and re-init paths. This one bites late, in the wild.
5. Skipping low-end Android QA. Agora’s SDK is polished; your custom frame code is not, until it’s tested on a cheap phone on 10%-packet-loss Wi-Fi. A Pixel 3a on a bad network is the whole test plan in one device.
The single biggest cost to watch: per-minute LLM inference on a chatty agent routinely exceeds Agora’s minute pricing many times over. Model cost per minute of conversation before you ship, and always keep a cheaper-model fallback for free-tier users.
When NOT to use Agora for your AI mobile app
Honesty sells better than a pitch. Skip Agora when:
- Your entire product is an AI agent that joins calls — LiveKit Agents or Daily Bots + Pipecat is a cleaner orchestration story, and our LiveKit playbook shows why.
- You must self-host for regulatory reasons — self-hosted LiveKit or a Jitsi-based stack wins.
- You need tight OpenAI Realtime orchestration from day one — Daily’s SDK is designed around exactly that.
- Your market is US-only and you already run on AWS — Chime SDK may be cheaper and simpler.
FAQ
Can I add live transcription to an Agora call without custom development?
Partly. Agora’s Real-Time Transcription covers English and a few other languages out of the box. The moment you need custom vocabulary, speaker diarization, or an unsupported language, you register an AudioFrameObserver and route audio to Deepgram or AssemblyAI — that’s custom work.
How do I add my own AI agent to an Agora call?
Two patterns. Use Agora’s Conversational AI Engine ($0.10/min) for speed, or Media Push to your own backend running Pipecat or LiveKit Agents, generate audio with Cartesia or ElevenLabs, and push it back via Media Pull for flexibility. Pick the engine for time-to-market, the backend for control.
How do I do custom background blur on Agora?
Register a VideoFrameObserver, grab each frame, run MediaPipe Selfie Segmentation via Core ML or TFLite, composite with Metal or Vulkan, and push the processed frame back. Cap processing at 24 FPS to protect battery on mid-tier devices.
What does a real custom-Agora AI project cost in 2026?
Light AI features (captions, blur, light moderation) run $40–80K. Moderate (translation, emotion, AR, an in-call agent) run $90–150K. Heavy (multi-party translation, voice cloning, empathetic voice, fine-tunes) run $160–300K and up — plus Agora minutes and per-minute inference.
Can I build all of this in React Native or Flutter?
You can get about 80% of the way. The last 20% (frame observer, ML delegate tuning, background modes) needs native Swift or Kotlin and a senior mobile engineer. Budget for that native work up front rather than discovering it in week 10.
Is Agora still a good choice for a consumer AI app in 2026?
Yes — especially if your audience includes APAC or China, or low-bandwidth reliability is a selling point. LiveKit and Daily.co are strong alternatives when the product is orchestration-first and open-source-leaning.
What latency target should an AI mobile app development company aim for?
Under 700 ms round-trip for a conversational agent to feel natural, under 400 ms for it to feel excellent. Compose the stack so each link — STT, LLM, TTS, and the Agora media path — stays under 300 ms on its own.
What to Read Next
Comparison
LiveKit vs Agora: The 2026 Cost Analysis
The two vendors side by side on real per-minute economics and flip points.
Framework
Cross-Platform Video App Development: A CTO Framework
Where cross-platform saves money and where it hits native-only walls on Agora.
Cost
Video Streaming App Development Cost in 2026
The financial twin of this guide — honest bands for video apps end to end.
Team
When and Why to Hire Computer Vision Developers
The ML roles you need to ship AI mobile pipelines that stay reliable at scale.
Case study
VALT — 770+ organizations, 50,000+ users
The custom frame-pipeline discipline we reuse on every Agora AI build.
Ship a real AI feature on Agora, not a demo
Agora plus the 2026 AI stack lets you ship conversational agents, live translation, emotion detection and custom visual effects. The catch is the custom layer: it only holds up if the frame observers, battery budget and weak-network hardening are built in from day one, and if you’ve modeled per-minute inference before launch, not after the first bill.
Whether you build in-house or bring in an AI mobile app development company, the same five questions decide the architecture — and if you want a shortcut to the answer for your product, that’s the conversation we have most weeks.
Get a 30-minute pipeline review for your Agora AI build
Frame-observer path, AI orchestration, latency budget, cost per minute — all on one call, with a senior engineer who’s shipped it.








