



Key takeaways
• A remote interpretation platform is four streaming layers. Transport, speech recognition, machine translation, and speech synthesis, wired so a speaker in one language reaches listeners in another with under a second of delay.
• The 2026 production bar is concrete. Sub-900 ms p95 end-to-end, word error rate under 12% on your primary domain, and a per-minute cost of $0.05 to $0.20 depending on how you build.
• Three paths, not two. Full SaaS (fastest, priciest per minute), a build-kit you assemble from best-in-class parts (the mid-market winner), or a self-hosted stack for sovereignty and volume.
• Compliance moved, so re-check it. The EU AI Act’s high-risk obligations were pushed from August 2026 to December 2027 under the Digital Omnibus. The Article 50 disclosure duty still applies today.
• Instrument before you launch. Latency per hop, WER by language, translation quality trend, and cost per minute are the numbers that decide whether you renew a vendor or switch.
Why Fora Soft wrote this playbook
Pick the wrong remote interpretation platform and you find out in production: latency creeps past a second, a medical term gets mistranslated on a live consult, or a per-attendee invoice arrives that is ten times what you modelled. We wrote this to stop that happening to you. We’ve built real-time video and voice products since 2005, across 250+ projects, and this is the internal checklist we run before we quote an interpretation build.
Our engineers ship WebRTC, LiveKit, Agora, and Twilio stacks every quarter, and our ML team has put Whisper, Deepgram, Google Cloud, AWS Transcribe, ElevenLabs, Cartesia, and on-device speech-to-speech models into production pipelines. We shipped TransLinguist, a multilingual interpretation product, and we run VALT for 770+ organizations and 50,000+ active users. So the numbers below come from stacks we’ve actually run, not a spec sheet.
If you’re weighing a ready SaaS (KUDO, Interprefy, Wordly), a build-kit wrapped by a partner, or a fully custom platform, this guide gives you the vendor map, a reference architecture, a cost model with the arithmetic shown, a 14-week build plan, and the compliance guardrails to check before you sign anything.
Not sure which path fits your use case?
Tell us your audience size, language pairs, and compliance bar. We’ll map them to a concrete stack and a first-draft latency budget on a 30-minute call.
What a remote interpretation platform actually is in 2026
A remote interpretation platform turns a speaker’s voice in one language into a listener’s voice in another, in real time, across a network, for one listener or thousands. The word “interpretation” (rather than “translation”) is deliberate: translation handles text and can run in batches; interpretation handles live speech and has to stream.
Every serious platform solves four problems in sequence. Transport gets the audio from speaker to server with low jitter. Recognition converts audio to text continuously, emitting partial and final hypotheses. Translation converts source text to target text with context and terminology control. Synthesis turns the translated text back into natural speech, ideally keeping the speaker’s voice identity. Good platforms add a fifth concern, observability, which tracks latency per hop, word error rate, translation quality, and where listeners drop off.

Figure 1. The four streaming layers of a remote interpretation platform, with the per-hop latency each layer spends and the observability rail that watches all of them.
Reach for a cascaded stack when: you need audit-grade transcripts, custom glossaries, or long-tail languages. Reach for end-to-end speech-to-speech when your language pairs are mainstream and every 200 ms of latency counts more than transcript control.
Cascaded vs end-to-end speech translation
The architectural shift since 2023 is that the four stages no longer have to run strictly in sequence. End-to-end speech-to-speech models (Meta’s open speech models, OpenAI’s Realtime API, and the Translatotron research lineage) collapse recognition, translation, and synthesis into one model for the big Latin language pairs. The open side keeps closing the gap: Meta’s No Language Left Behind research pushed open machine translation to 200 languages.
Here’s the catch. End-to-end models win on latency (they can dip under 500 ms) and on prosody, because they never throw the voice away and rebuild it. They lose to cascaded stacks on long-tail languages, on enforced terminology, and on anything that needs a clean, reviewable transcript. For 2026, a cascaded stack (ASR then MT then TTS) is still the safer default for most builds. End-to-end is the sharper tool for a narrow, latency-obsessed job.
The practical read: prototype with an end-to-end API to feel the latency ceiling, then decide whether transcript control and language coverage pull you back to a cascade. Most of our production builds land on the cascade, with an end-to-end fallback for the two or three highest-volume pairs.
Market snapshot — who is buying, who is shipping
Remote simultaneous interpretation (RSI) and AI interpretation is now a multi-billion-dollar market on a double-digit growth path through 2030 (directional figures from several market-research houses, treat as a trend, not a precise number). Three waves drive it: enterprise all-hands going multilingual by default, regulated industries adopting AI captions under accessibility mandates, and the events industry swapping on-site interpreter booths for AI plus a small human review team.
On the supply side, KUDO, Wordly, and Interprefy lead the full-stack RSI category, Interprefy alone integrating with 80+ meeting platforms across thousands of language combinations. Open-source parts (Whisper large-v3, Meta’s NLLB-200, and Coqui XTTS) have made do-it-yourself builds realistic for a team with three to five ML engineers and a modest GPU budget.
The shift that matters most in 2026: buyers now split the decision three ways, not two. Option A is a full SaaS (fast, expensive per minute, minimal customization). Option B is a managed build-kit (a transport layer plus best-in-class ASR, MT, and TTS) wrapped by a partner. Option C is a fully self-hosted stack on your own GPUs for sovereignty and a low cost floor. Option B is winning mid-market deals because it delivers most of the speed of A at a fraction of the per-minute cost, without the multi-quarter timeline of C.
The 2026 vendor stack — five layers, twenty-one names
Break the stack into five layers and shortlist two or three vendors per layer. This is the grid we use when we scope a client build.
Layer 1 — Full-stack interpretation SaaS
KUDO (large human-interpreter network plus AI captions), Interprefy (Swiss pioneer, thousands of language combinations, 80+ platform integrations), Wordly (AI-only, 60+ languages, priced by hours and attendees), Maestra (strong on webinars and webcasts), Palabra.ai (sub-second two-way), plus Jotme, transyncAI, and X-doc. Typical pricing runs $8 to $35 per attendee-hour for AI-only, and $60 to $200 per interpreter-hour plus platform for a human-plus-AI hybrid.
Layer 2 — Streaming ASR (speech-to-text)
Deepgram Nova-3 (sub-300 ms streaming, roughly $0.0077/min pay-as-you-go and about $0.0058/min for multilingual streaming per Deepgram’s 2026 pricing), Google Cloud Chirp, AWS Transcribe, Azure AI Speech, AssemblyAI, Soniox, Gladia, and OpenAI Whisper (open-source, best long-tail coverage, self-host GPU at roughly $0.005 to $0.012/min). NVIDIA Parakeet and Canary lead leaderboards but are less production-proven for streaming interpretation.
Layer 3 — Machine translation (text-to-text)
DeepL (strongest European languages, custom glossaries), Google Cloud Translation (roughly $10 per million characters, AutoML custom models), AWS Translate, Azure Translator, Meta NLLB-200 (open-source, 200 languages), and frontier LLMs like Anthropic Claude and GPT-class models for context-heavy legal and medical text. For live speech, a streaming-aware engine beats a batch engine by 200 to 400 ms on a typical turn.
Layer 4 — Streaming TTS (text-to-speech)
ElevenLabs (low time-to-first-audio, voice cloning; see current tiers), Cartesia Sonic (about 40 ms time-to-first-audio, the cheapest premium option), Google Cloud TTS, Azure Neural TTS, Amazon Polly, and open-source Coqui XTTS and F5-TTS for self-hosted voice cloning. Voice preservation across languages is the 2026 differentiator: ElevenLabs and XTTS keep the speaker’s identity, stock voices flatten it. Avoid OpenAI TTS here; its time-to-first-audio is too slow for interpretation.
Layer 5 — Real-time transport and orchestration
LiveKit (open-source plus cloud, generous free tier), Agora (about $0.99 per 1,000 minutes), Twilio, Daily.co, Vonage, Jitsi (self-host), Pipecat (open-source voice-agent framework), and OpenAI Realtime for an all-in-one option. For interpretation you need an SFU that supports multiple audio tracks per participant (one source, many translated outputs) and holds sub-250 ms p95 latency across regions. Our deep-dive on building multimodal AI agents with LiveKit walks through the transport patterns.
Reach for open-source parts when: you have ML engineers, GPU budget, and long-tail languages. Reach for managed APIs when time-to-launch and support SLAs matter more than the cost floor.
Comparison matrix — what you pay, what you ship
The three go-to-market options, compared at a 10,000-minute-per-month mid-market scale (roughly 500 attendees across 20 hourly multilingual events).
| Dimension | A: Full SaaS | B: Build-kit | C: Self-hosted |
|---|---|---|---|
| Example stack | KUDO, Wordly, Interprefy | LiveKit + Deepgram + DeepL + ElevenLabs | Jitsi + Whisper + NLLB-200 + XTTS |
| Build time | 1–2 weeks | 10–14 weeks | 6–12 months |
| Cost per minute | $0.14–$0.35 | $0.08–$0.16 | $0.02–$0.06 (after CapEx) |
| Latency p95 | 600–1,200 ms | 700–1,100 ms | 900–1,800 ms |
| Custom terminology | Glossary upload | Glossary + custom MT | Full fine-tuning |
| Data residency | Vendor regions only | VPC deployment | Fully sovereign |
| Best for | Events, webinars, fast launch | SaaS products, mid-market | Government, healthcare, defense |

Figure 2. The same three paths as a positioning view: SaaS trades cost and control for launch speed; self-hosted trades speed for control and the lowest cost floor.
Reference architecture — the six hops
Every production remote interpretation platform we’ve shipped has the same six hops. Budget your latency per hop and you’ll hit the sub-900 ms total. Skip the per-hop budget and you’ll discover in week 10 that recognition alone ate 600 ms.
Hop 1, Capture (60–120 ms). Browser or mobile captures at 48 kHz mono with WebRTC Opus at 32 to 64 kbps. Echo cancellation, noise suppression (RNNoise or Krisp), and automatic gain control stay on. Voice activity detection runs server-side, with Silero VAD as the 2026 default, to mark speech segments.
Hop 2, Transport (40–120 ms). Put the SFU in the same region as the speaker. Keep the speaker on a dedicated audio track and route each translated language on its own track, so a listener subscribes only to the language they need.
Hop 3, Streaming ASR (150–350 ms). Deepgram, Google Chirp, or Whisper via CTranslate2 in 200 ms chunks. Show partial hypotheses as captions immediately; finalize at punctuation boundaries for translation input, so audiences read text before they hear the voice.
Hop 4, Machine translation (120–350 ms). A streaming-aware engine with a glossary and domain adaptation. Batch MT adds 300 to 600 ms and breaks the budget. Keep the source context window short (three to five prior utterances) to preserve pronoun resolution without a latency blow-up.
Hop 5, Streaming TTS (75–250 ms). ElevenLabs or Cartesia with streaming output at 24 kHz PCM and time-to-first-audio under 100 ms. Voice-clone the speaker with consent for identity preservation.
Hop 6, Playback (60–120 ms). The listener subscribes to their language track through the SFU, with a 60 to 100 ms jitter buffer. Normalize loudness (target around −16 LUFS) so the translated voice matches the room mix.
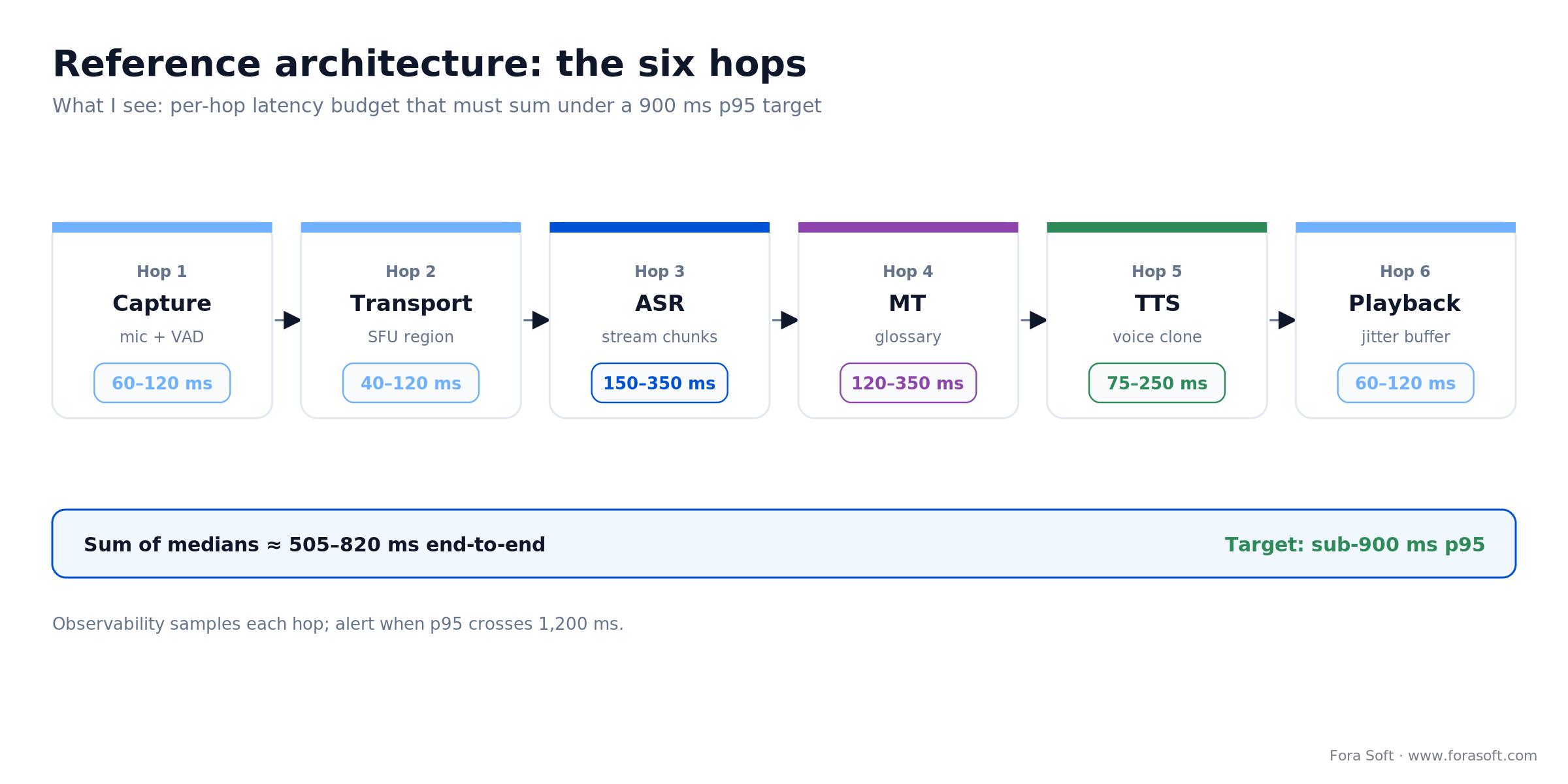
Figure 3. The six-hop reference pipeline. The median hops sum to roughly 505 to 820 ms, which keeps you under a 900 ms p95 target with headroom.
Observability cuts across every hop: metrics for time-in-queue, traces per utterance, and sampled audio capture (with consent) to regenerate WER and translation-quality scores offline.
Want a latency budget for your exact stack?
We’ll map your languages, audience, and compliance bar to a concrete six-hop budget and a first-draft architecture, at no cost.
Cost model — what a 500-attendee event actually costs
Scenario: 500 attendees, a 60-minute all-hands, two source languages (English and Spanish), five listener languages. Per-minute costs are per source channel; listener channels are marginal bandwidth. Here is the arithmetic, not a range.
| Line item | Full SaaS | Build-kit | Self-hosted |
|---|---|---|---|
| Transport | Bundled | $17 | $4 |
| Streaming ASR | Bundled | $2.80 | $0.72 |
| MT engine | Bundled | $6 | $0.90 |
| Streaming TTS (5 langs) | Bundled | $54 | $6 |
| Platform / per-attendee | 500 × $12 = $6,000 | — | — |
| Hour total | ~$6,000 | ~$80 | ~$12 + GPU |
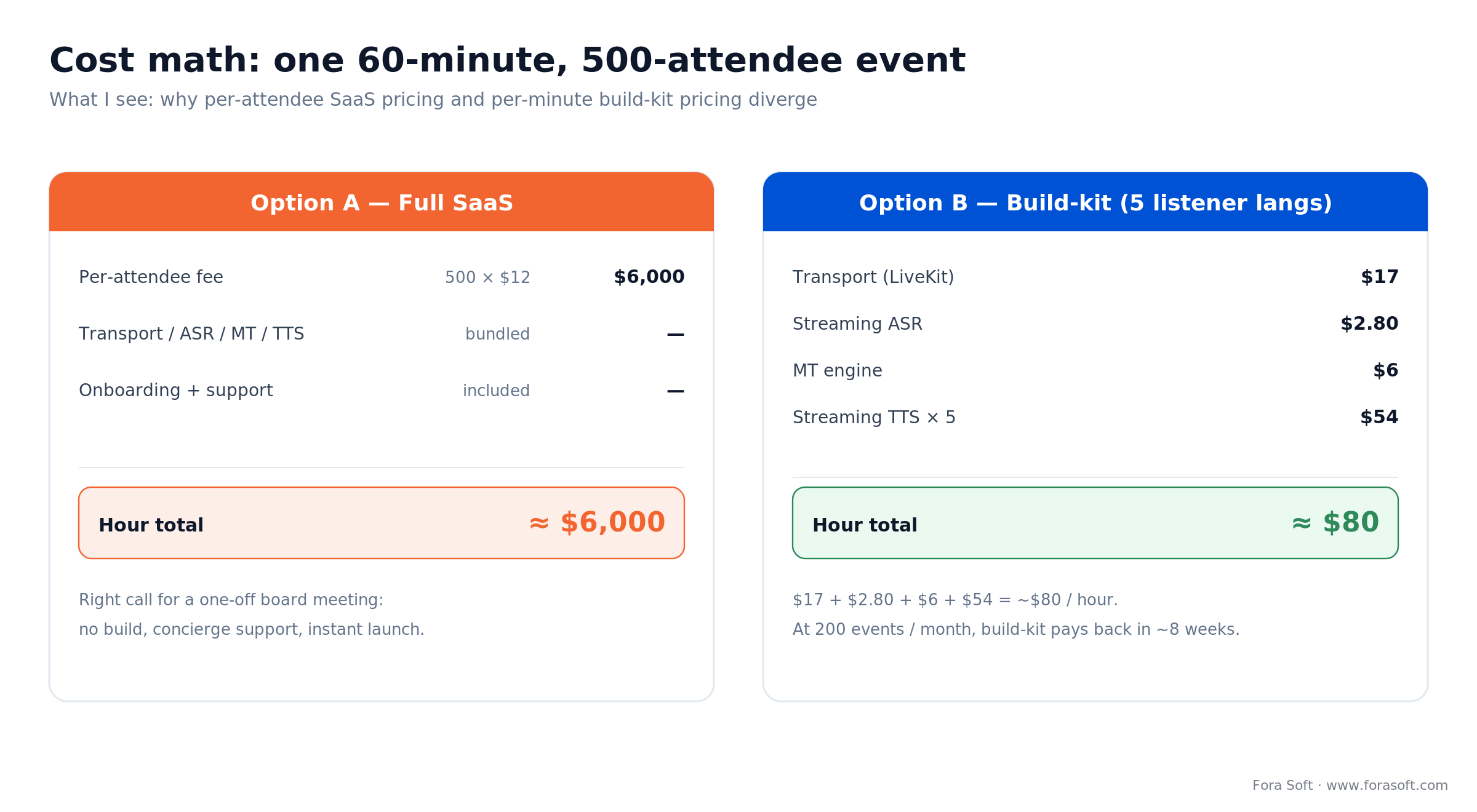
Figure 4. The build-kit hour is $17 + $2.80 + $6 + $54 = ~$80. The SaaS hour is dominated by the 500 × $12 per-attendee fee.
The SaaS number looks scary, but it bundles onboarding, concierge support, and the per-attendee model most full-stack vendors use. For a one-off 500-person board meeting, SaaS is often the right call. For a product hosting 200 such events a month, a build-kit pays back in roughly eight weeks.
Self-hosted adds CapEx: a modest cluster for continuous 500-concurrent streams runs $45k to $80k in GPU servers plus a few thousand a month in colocation. It only wins at real scale (around 2M minutes a month and up) or under a sovereignty mandate. Our estimates lean conservative here because we build with Agent Engineering, which lets a small team ship the build-kit tier faster than a traditional shop would quote.
Mini case — the 14-week build for a medtech client
A European medtech customer came to us in mid-2025 with a hard problem. Their hospital clients wanted real-time interpretation for surgeon-patient consults in eight languages, but off-the-shelf SaaS was a non-starter: GDPR, HIPAA for the US subsidiaries, clinical terminology, and voice-identity preservation for patient trust. This is the same class of work as our CirrusMED telemedicine platform.
We built a build-kit-tier stack in 14 weeks: LiveKit Cloud in an EU region, a Deepgram medical model with a Whisper fallback fine-tuned on ICD-10 vocabulary, Google Cloud Translation with a medical glossary of 11,800 terms, ElevenLabs with consented voice clones per clinician, and an observability pipeline that logged every utterance for 90-day audit retention. Median end-to-end latency landed at 740 ms; p95 at 980 ms. Word error rate on the internal medical test set fell from a Whisper baseline of 14.2% to a fine-tuned 8.9%.
The commercial outcome: the customer added five hospital contracts in Q1 2026 they could not have pursued with their old consecutive-interpreter model, at an all-in platform cost of roughly $0.11 per minute against the $0.32 per minute they had paid a human-interpreter agency. Want a similar assessment? Book a 30-minute scoping call and we’ll size it against your languages and compliance bar.
Compliance — EU AI Act, HIPAA, ISO/IEC 42001, SOC 2
Interpretation systems crossed a compliance threshold in 2025 and 2026 that changes the build calculus. Check each of these before you sign.
EU AI Act. General-purpose speech translation is a limited-risk system under Article 50; the main duty is disclosing that content is AI-generated or AI-translated, and that applies today. Use the system in a high-risk context from Annex III (healthcare, education, law enforcement, asylum and migration, administration of justice, critical public services) and it inherits high-risk obligations: quality management, risk management, data governance, technical documentation, human oversight, and post-market monitoring. Timing matters and it changed: those Annex III high-risk obligations were originally set for 2 August 2026, but the Digital Omnibus agreed in 2026 postpones them to 2 December 2027 (embedded product AI to 2028), pending formal adoption. Track the official EU AI Act implementation timeline rather than a vendor’s marketing page. Our internal checklist has 42 control items we verify before a high-risk go-live.
HIPAA. Patient conversations routed through recognition, translation, and synthesis are electronic protected health information. You need a business associate agreement with every vendor in the pipeline (Deepgram, Google, and ElevenLabs all offer HIPAA BAAs in 2026), no training on customer audio, audit logs kept six years, and encryption in transit (DTLS-SRTP for WebRTC) and at rest (AES-256).
ISO/IEC 42001. The AI management system standard, published in December 2023, is becoming an enterprise procurement checkbox. Expect large customers to ask for it in RFPs through 2026 and 2027.
SOC 2 Type II. Still the minimum North American enterprise bar. Budget $45k to $90k and a six-month observation window for a first-time report.
Voice and biometric law. Voice cloning consent is regulated under BIPA (Illinois), CCPA/CPRA (California), Texas CUBI, and GDPR special-category data. Record explicit opt-in for the voice-clone step and expose one-click revocation.
A decision framework — pick the stack in five questions
Five questions, in this order, narrow the decision to a two-vendor shortlist.
Question 1, event or product? Running ten or fewer events a month and just need captions and translation? A full SaaS is almost always cheaper than a build. Building a recurring multilingual feature inside your own product (telemedicine, LMS, contact center)? Go to Question 2.
Question 2, what languages? Five Latin languages plus an English pivot are cheap on every stack. Russian, Arabic, Mandarin, Hindi, Korean, and Japanese are commercial-grade on Google, Azure, and DeepL. Tagalog, Swahili, Vietnamese, Bengali, and regional Arabic variants still sit above 18% WER on most providers and often need Whisper fine-tuning.
Question 3, what latency bar? Under 900 ms p95 is simultaneous-interpretation grade. 900 to 1,500 ms is fine for webinars and training. Above 1,500 ms feels like consecutive interpretation and breaks natural conversation.
Question 4, what compliance bar? Limited-risk general business points to any vendor. Healthcare in the US or EU means a HIPAA BAA plus EU AI Act high-risk documentation. Government means FedRAMP plus in-region hosting. K-12 education means FERPA and state student-privacy rules.
Question 5, voice identity or stock voices? Stock voices are fine for captions-plus-audio webinars. For one-on-one conversations (telemedicine, therapy, sales), consented voice-cloned TTS measurably lifts trust and listener satisfaction over stock voices.
Five pitfalls that kill remote interpretation rollouts
1. Budgeting latency once instead of per hop. Teams set a “sub-1-second” goal, skip the per-hop split, and find in week 10 that ASR alone takes 600 ms. Fix: write the hop table before picking vendors.
2. Ignoring punctuation at the MT handoff. Streaming ASR emits rolling hypotheses without punctuation; batch MT expects sentence units. The result is either a long wait or robotic fragments. Fix: use a streaming-aware MT, or add a small punctuation model between ASR and MT.
3. Skipping the glossary step. Generic MT renders “CAR T-cell” as “automobile T-cell” in German. Enforce terminology at the MT level (DeepL glossary, Google AutoML, or system-prompt injection for an LLM) or you fail domain QA.
4. A single-region SFU. An SFU in one US region adds around 180 ms of round-trip for a speaker in Frankfurt. Use a multi-region mesh and pin ASR, MT, and TTS to the speaker’s region.
5. No observability on translation quality. Latency is easy to measure; translation quality is not. Sample 2 to 5% of utterances with consent, run nightly quality scoring against a reference set, and alert when domain quality drops more than a few points week over week. Our notes on speech recognition accuracy in noisy environments go deeper on the ASR half.
KPIs — what to measure on day one
Wire these five into the observability pipeline before the first production call.
End-to-end latency p50 / p95 / p99. Measured from mic capture to listener output. Goal: p95 under 900 ms. Alert at 1,200 ms.
Word error rate by language and domain. Sampled offline against reference transcripts. Goal: under 12% on your primary domain, under 18% on general conversational audio.
Translation quality trend. Nightly scoring on a curated 500-utterance test set per language pair. Track the trend, not the absolute number.
Listener satisfaction and voice quality. A predicted mean-opinion score on the TTS output, plus a one-question satisfaction prompt to listeners every few events.
Cost per minute per source channel. Actual spend on transport, ASR, MT, and TTS divided by source-speaker minutes. This number tells you when to renegotiate or switch tiers.
Industries shipping real value in 2026
Healthcare and telemedicine. Cross-border consults, multilingual nurse triage, and interpretation for deaf and hard-of-hearing patients, usually delivered as video remote interpreting where a qualified human is legally required. Hospital networks report meaningful cuts in interpreter-agency spend after an AI deployment.
Enterprise all-hands and training. Large companies now default to 8 to 20 language streams for global town halls. The economics broke through when per-attendee AI cost dropped below $8 against $80 to $200 per interpreter hour.
Education and MOOCs. Major platforms and university networks ship AI captions and dubbed tracks automatically. Completion rates in non-English markets rise when a course plays in the learner’s native language, the same lever behind our e-learning work on BrainCert.
Contact centers. AI interpretation collapses the multilingual staffing model: one English-speaking agent can handle Spanish, Portuguese, and French calls with a sub-900 ms interpreter in the loop.
Public sector and events. Emergency lines are piloting AI interpretation for non-English callers, and the events market has shifted budget from interpreter booths to AI captions plus a hybrid human review for high-stakes keynotes.
Build vs buy vs adapt
Buy (full SaaS) when your need is episodic events, your language list is mainstream, and legal, procurement, and IT want one vendor. Time to live: 1 to 2 weeks. Watch for per-attendee pricing that punishes scale.
Adapt (build-kit) when you’re embedding interpretation inside your own product, you want control over UX, data path, and pricing, and you have or can hire two to four senior engineers for a quarter. This is where we do most of our 2026 work. Time to live: 10 to 14 weeks. Cost per minute: $0.08 to $0.16.
Build (self-hosted) when your volume passes 2M minutes a month, you have sovereignty or air-gap requirements, or you’re in a niche domain where custom models buy a quality edge that shows up in business outcomes. Time to live: 6 to 12 months. CapEx $45k to $200k. Run cost $0.02 to $0.06 per minute after amortization.
Reach for the build-kit middle lane when: you host recurring events or ship a product feature, want your own pricing and data path, and need to launch this quarter rather than next year. It’s where most 2026 mid-market deployments land.
When not to adopt AI interpretation (yet)
Three situations where we tell clients to wait or to keep human interpreters.
High-stakes legal depositions or diplomatic negotiations. Liability for one mistranslated phrase dwarfs the savings. Keep a certified human interpreter in the loop and use AI only for attendee captions.
Low-resource language pairs without a fine-tuning budget. If your primary pair sits above 22% baseline WER, you’ll spend months fine-tuning before the experience is acceptable. Start with Whisper fine-tuning and an internal quality team before you productize.
Regulated settings without consent infrastructure. Voice cloning and audio logging need explicit opt-in. If your product can’t surface consent UI cleanly, solve that first.
Reach for human-plus-AI when: the setting is legally binding, the language pair is low-resource, or the cost of a single error is higher than a year of platform fees. AI handles the volume; the human owns the liability.
A 14-week deployment playbook
The cadence we use for a build-kit-tier deployment for a mid-market client.
Weeks 1–2, discovery and stack selection. Language list, latency bar, compliance bar, peak audience. A two-vendor shortlist per layer. Signed BAAs where required.
Weeks 3–4, transport and capture prototype. WebRTC capture with VAD, an SFU in one region, a live captions track. First latency measurement, targeting capture-to-caption under 500 ms.
Weeks 5–7, the ASR to MT to TTS pipeline. One language pair end to end, the punctuation handoff, a glossary, and the first voice-clone consent flow. End-to-end p95 measured.
Weeks 8–10, scale and quality. Remaining languages, a multi-region SFU, a load test to twice expected peak, and a translation-quality baseline.
Weeks 11–12, compliance and observability. Audit logs, 90-day retention, consent revocation, an EU AI Act documentation pack if high-risk, and SOC 2 controls mapped.
Weeks 13–14, pilot and launch. Two pilot events with real listeners, a satisfaction survey, a cost-per-minute reconciliation, and a go-live runbook. If you want this run for you, our AI development team and language-interpretation specialists do exactly this.
Need this delivered in 14 weeks?
We’ve shipped remote interpretation platforms for healthcare, events, and enterprise comms. We can start next week.
FAQ
What is a remote interpretation platform?
A remote interpretation platform is software that converts a speaker’s live voice into other languages over a network in real time. It chains four streaming layers, transport, speech recognition, machine translation, and speech synthesis, so remote listeners hear an interpreted voice with under a second of delay.
What latency is realistic for AI interpretation in 2026?
700 to 1,000 ms end-to-end (p95) on a well-tuned cascaded stack in one region, 500 to 800 ms on end-to-end speech-to-speech models for the big Latin pairs, and 1,000 to 1,500 ms on long-tail languages that still need Whisper fine-tuning.
How much does a remote interpretation platform cost?
Per source-minute, roughly $0.14 to $0.35 for full SaaS, $0.08 to $0.16 for a build-kit, and $0.02 to $0.06 self-hosted after CapEx. A one-hour, 500-attendee SaaS event can run about $6,000 on a per-attendee model; the same hour on a build-kit is around $80 in vendor costs.
How many languages do I really need?
For enterprise all-hands, 8 to 12 covers most global audiences. For consumer products, English, Spanish, Portuguese, French, German, Mandarin, Arabic, and Hindi reach billions of people. Start narrow and add languages as demand data shows up.
Does voice cloning cross legal lines?
Not with explicit written consent and a revocation path. BIPA, CCPA/CPRA, GDPR special-category rules, and the EU AI Act all assume consent is in place. Without it, you’re exposed in most jurisdictions.
Do I still need human interpreters?
For legal depositions, diplomatic work, and some medical interpretation, yes, as the certified audit layer. AI handles the routine 80 to 95% of volume; a human-plus-AI hybrid covers the cases where liability and nuance demand a person.
How does it integrate with Zoom, Teams, and Webex?
The major meeting platforms expose virtual interpreter channels or RTMP injection, so you can feed an interpreted audio track in. For custom LiveKit, Agora, or Twilio stacks, you add translated audio as extra SFU tracks. We keep integration adapters for the common platforms.
How does Fora Soft price a build?
A 14-week fixed-scope engagement, with the price driven by language count, compliance bar, and integration scope; vendor licenses and cloud costs pass through. Because we build with Agent Engineering, our estimate is usually faster and leaner than a traditional shop’s. Book a scoping call for a number against your scope.
What to read next
Real-time translation
Multilingual translation in video calls
How streaming ASR and MT plug into WebRTC calls with sub-900 ms latency.
LiveKit multimodal
Multimodal AI agents with LiveKit
Voice-plus-vision agent architecture for interpretation and support.
Noisy ASR
Speech recognition in noisy environments
Whisper fine-tuning and the 2026 playbook for contact-center audio.
Multilingual AI
How multilingual AI software actually works
A buyer’s and builder’s playbook for multilingual AI features.
Ready to pick your remote interpretation platform?
A remote interpretation platform in 2026 has clear defaults: SaaS for events, a build-kit for products, self-hosted for sovereignty. The stack is five layers, the budget is six hops, the production bar is sub-900 ms and sub-12% WER, and the compliance path depends on whether you land in Annex III of the EU AI Act, whose high-risk deadline just moved to December 2027.
One honest note to close on: the fastest stack is not always the cleanest. End-to-end speech-to-speech shaves latency but trades away glossary control, auditable transcripts, and long-tail coverage. Pick by your constraints, not by the benchmark that looks best in isolation. For an architecture tailored to your languages, audience, and compliance bar, we’ll walk you through the decisions in 30 minutes. You can also start from our real-time speech translation guide or the Audio for Video learning track.
Let’s scope your interpretation build
Bring your languages, audience size, and compliance bar. You’ll leave the call with a stack recommendation and a latency budget.








