



Key takeaways
• Streaming and conferencing are different scaling problems. One-to-many streaming scales with CDNs, transcoding farms and adaptive bitrate. Many-to-many conferencing scales with SFUs/MCUs, cascade meshes and tight latency budgets. Solving them with the same architecture is the most common and most expensive mistake.
• Scaling is a structural problem, not a server-count problem. Throwing instances at an origin that still fans out to every viewer does not help. Stateless APIs, CDN-first edge distribution, horizontal SFUs, autoscaling transcoders and a clear data boundary are what actually move the numbers.
• Most struggling platforms can be stabilised in 2–6 weeks. A focused audit usually finds two or three bottlenecks (origin, transcoder, DB contention, TURN capacity) that account for >80% of the incidents. Fixing those buys 10× the concurrency before a rebuild is needed.
• Latency budgets set the architecture. <1s for broadcast (HLS/DASH + CMAF LL), <500ms for interactive live (LL-HLS, WebRTC over HLS), <200ms mouth-to-ear for conferencing (WebRTC SFU). Pick the budget before you pick the tooling.
• KPIs that actually matter. Startup time, rebuffer ratio, P95 glass-to-glass latency, concurrent viewers per origin/SFU, cost per concurrent stream, MOS. If your dashboard is not showing these live, you are flying blind.
• Fora Soft ships these every day. From small interactive e-learning rooms (BrainCert, Scholarly) to billiards championships streamed globally (Kozoom) to enterprise WebRTC fleets — we know where the numbers flip and we tune for them early.
Why Fora Soft wrote this playbook
Fora Soft has spent 21 years shipping real-time video and streaming products. Our portfolio includes live-video education at scale on BrainCert, broadcast-grade billiards streaming on Kozoom, telemedicine, WebRTC-based courtrooms, OTT platforms and video surveillance systems. We have built, audited and rescued more of these systems than we can comfortably count.
This playbook is what we tell clients in Week 1 of a scaling engagement: how streaming and conferencing actually differ, where platforms break first, how to size them honestly, and what a realistic fix looks like. It draws on specific choices we use on production: Hetzner AX-series bare metal for transcoding, Cloudflare for edge delivery, mediasoup and LiveKit for SFU clusters, managed Kubernetes where it pays, plus a comparison of custom work vs Agora-style managed video.
If you are staring at a dashboard that is going red on product demos, our custom scalability modules are designed to plug in next to your existing stack and buy you the headroom you need before an architectural rebuild becomes unavoidable.
Platform buckling under real traffic?
Thirty minutes on a call is usually enough to name the two or three bottlenecks blocking your next order of magnitude of growth. Free, no sales theatre.
Streaming vs conferencing: two different scaling problems
Scaling decisions start with one question: what traffic pattern is the product? Broadcast (one publisher, many viewers) and conferencing (many publishers, many viewers) look similar on a pitch deck and behave nothing alike in production.
| Dimension | One-to-many streaming (OTT/live) | Many-to-many conferencing |
|---|---|---|
| Traffic shape | 1 publisher, 10k–10M viewers | 2–1000 publishers, same viewers |
| Latency budget (glass-to-glass) | 2–30s standard, <1s LL-HLS/CMAF, <500ms WebRTC-over-CDN | <200ms interactive, <50ms high-trust |
| Core primitive | Ingest → transcode → packaging → CDN → player | WebRTC peer → SFU → optional cascade → peer |
| Hot bottleneck | Transcoder CPU/GPU, origin egress | SFU port/bandwidth, TURN capacity |
| Cost shape | Egress-dominated, CDN-billed per GB | Compute-dominated, SFU hosting per CCU |
| Scaling unit | PoP + cache layer per region | SFU node per 300–1000 concurrent streams |
| Player | HLS/DASH + ABR ladder | WebRTC SDK (browser/native) |
Rule of thumb: if you want high fan-out and are comfortable with 2–10s latency, bet on HLS + CDN. If you need interactive sub-second latency with many publishers, bet on an SFU. Hybrid products (live classes, watch parties, interactive sports) need both, and they need them designed together.
Why video platforms actually break — and why “more servers” does not help
When a video platform buckles during the webinar, the cricket final, the virtual classroom, the problem is rarely the total CPU count. It is almost always one of these five structural failures.
1. A single origin fanning out to every viewer. No CDN or an under-sized one. Egress saturates the first NIC that hits its cap; buffering spreads region-by-region.
2. A transcoder overloaded on a general-purpose VM. ABR ladders are CPU-expensive. Running 1080p60 H.264 on a shared t-class VM is the textbook source of stream drops.
3. SFU sized for “peak yesterday”. Conferencing SFUs saturate on egress bandwidth or port count. A single node comfortably holds 300–1000 concurrent audio+video tracks; past that you need cascade or autoscaling.
4. Stateful application servers. If the session state lives in the app process, you cannot horizontally scale it without sticky sessions or shared state. Move the state to Redis, Postgres, or a dedicated session store.
5. No observability. No rebuffer rate dashboard, no P95 startup time, no SFU CPU alert — you only find out when Twitter does. Monitoring is cheap. Rebuilding on fire is not.
Downtime is expensive. Recent Gartner/Information Technology Intelligence Consulting numbers put the average cost of enterprise downtime between USD 5,600 and USD 9,000 per minute. On a consumer live-stream event that is a fraction of the lost advertising, subscription cancellation and brand hit. A focused audit paid once is almost always cheaper than the next incident.
How scalable video systems are actually designed
The same six design principles show up on every well-scaled video product. They are not proprietary tricks; they are table stakes.
1. Stateless compute, stateful storage. API services carry no user state in memory. Sessions live in Redis; media state lives in the SFU or origin; business data in Postgres. Any service can die or scale without sticky routing.
2. CDN-first edge distribution. For broadcast: HLS/DASH packaged at the origin, cached on a CDN (Cloudflare, Fastly, Akamai, AWS CloudFront). 95–99% of viewer traffic never touches the origin. For low-latency: LL-HLS or WebRTC-over-CDN (Cloudflare, Phenix) to keep sub-second.
3. Adaptive bitrate (ABR). A ladder of renditions (e.g. 240p, 480p, 720p, 1080p at 400kbps/1.2Mbps/3Mbps/6Mbps) lets each viewer pick the highest quality their connection supports. Rebuffer rate drops by order of magnitude.
4. Horizontal SFU with cascade. Each SFU holds a cap (say 500 concurrent media streams). When a room grows past that, cascade the room onto a second SFU. mediasoup, LiveKit, Jitsi and Janus all support this; implementation details vary.
5. Transcoding on the right hardware. For serious broadcast we run transcoders on Hetzner AX-series bare metal with GPU (NVENC) or dedicated CPU. Elastic burst into AWS MediaConvert or Cloudflare Stream when spikes go past the fleet. Transcoding on a shared VM is a trap.
6. Monitoring and graceful degradation. Dashboard on P95 startup time, rebuffer ratio, error rate per region, SFU CPU, TURN bandwidth. Alarms at 70% of capacity. When things go wrong, drop non-essentials first: simulcast layers, 4K rendition, fancy filters. Keep the basic stream alive.
Reference architecture for a scalable video platform
The diagram below is the shape we default to for anything above a few thousand concurrent users. A small product uses a subset; an enterprise product adds regional replicas and private-origin redundancy.
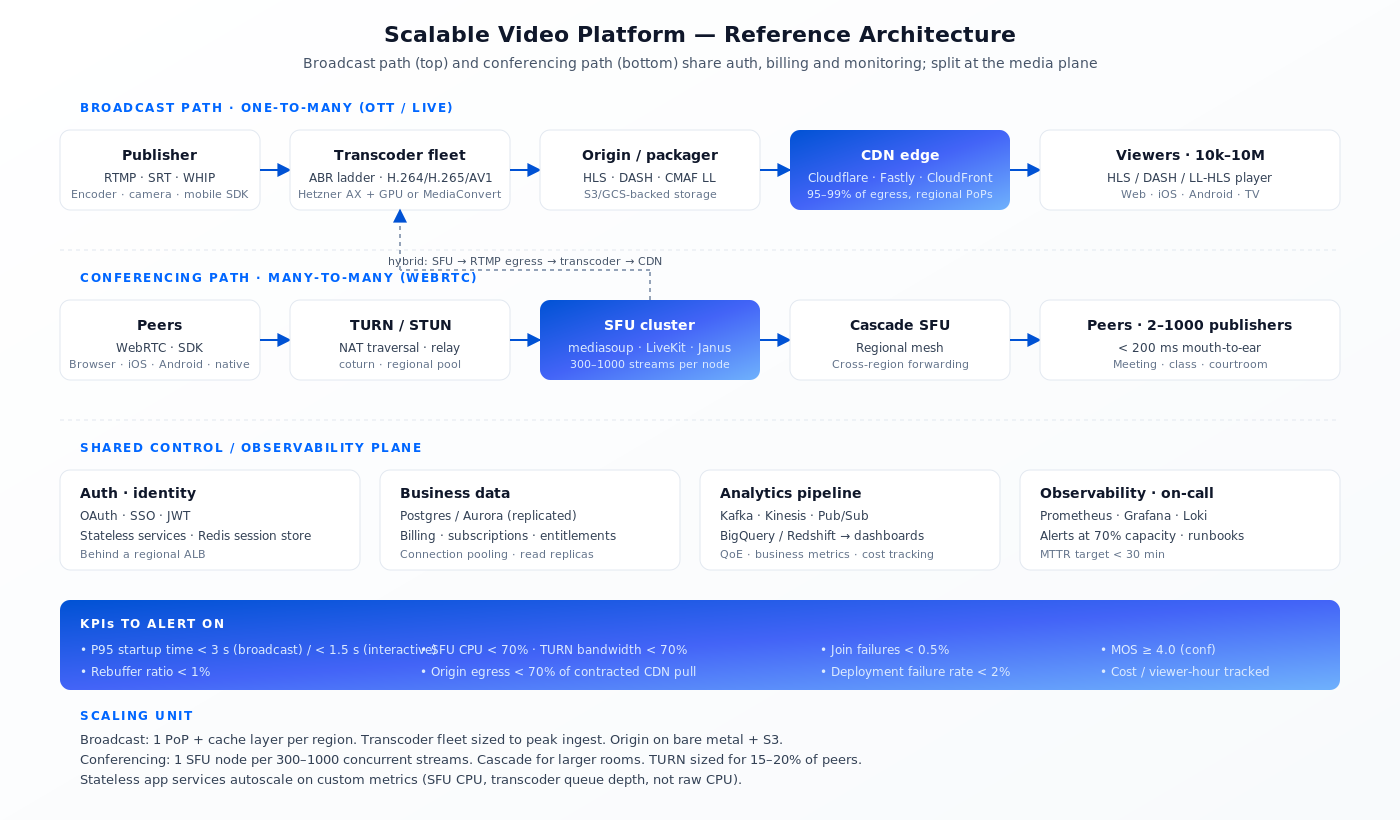
Figure 1. Broadcast path (top) and conferencing path (bottom) share auth, billing and monitoring but split at the media plane.
Broadcast path (OTT, live events)
Ingest (RTMP, SRT, or WebRTC-WHIP) → transcoder fleet producing an ABR ladder → origin packaging to HLS/DASH + CMAF LL → CDN edge → player. Typical scaling unit: a region’s transcoder fleet sized for peak ingest, with an autoscaling group for spikes.
Conferencing path (meetings, rooms, interactive live)
WebRTC peer → SFU cluster → (optional) cascade SFU → WebRTC peer. TURN servers are sized independently based on symmetric-NAT prevalence in your audience (rule of thumb: 15–20% of users need TURN). For interactive live products (watch-along, e-learning), the conferencing stage may feed into the broadcast path via server-side RTMP egress.
Shared plane (auth, billing, analytics)
Identity, billing, user records and analytics are shared across paths. These services should be stateless, horizontally scaled, behind a regional load balancer, talking to a replicated Postgres or Aurora. Analytics events stream to Kafka or a managed equivalent, land in BigQuery/Redshift for reporting and a time-series store (Prometheus, Grafana Cloud) for operations.
Latency budgets that dictate your architecture
Before picking tools, pick the latency budget. Everything else follows.
| Use case | Glass-to-glass target | Tech stack fit |
|---|---|---|
| VOD / OTT library | n/a (startup < 3s) | HLS/DASH + CDN, VOD packager |
| Standard live (sports, concerts) | 5–30 s | HLS/DASH 6-s segments + CDN |
| Low-latency live (betting, auctions) | 1–3 s | LL-HLS, CMAF low-latency |
| Interactive live (e-learning, streaming gym) | 300 ms–1 s | WebRTC-over-CDN or SFU with RTMP egress |
| Group video call | <200 ms | WebRTC SFU (LiveKit, mediasoup, Jitsi) |
| Courtroom, surgery, trading | <50 ms | WebRTC SFU with regional TURN, QoS-tuned network |
Common trap: asking for sub-second latency on a platform designed with 6-second HLS segments. The tooling shift is not “tune a parameter” — it is a re-architecture.
Need a second opinion on your scaling plan?
We will stress-test your architecture against the latency budget and traffic shape you actually have. If the plan is sound, we will say so.
When your platform is already on fire: the stabilisation playbook
Most platforms we audit are not broken beyond repair. They have two or three bottlenecks accounting for the vast majority of incidents. A focused 2–6 week intervention buys 10× headroom. The standard sequence:
Week 1 — audit and baseline. Measure P95 startup, rebuffer ratio, SFU CPU, origin egress, DB connection pool. Identify the top three bottlenecks. A written code and architecture audit becomes the map.
Week 1–2 — put a CDN in front of the origin. Same-day win for broadcast. Cloudflare or Fastly on the HLS/DASH endpoint reduces origin egress by 95–99% almost immediately.
Week 2–3 — containerise and auto-scale. Move stateless services into containers (Docker + Kubernetes or ECS). Autoscale on custom metrics (SFU CPU, transcoder queue depth) not just CPU.
Week 3–4 — move transcoding off the app path. Transcoders go to dedicated hardware or managed services (AWS MediaConvert, Cloudflare Stream, Wowza). Queue-based processing, not in-request.
Week 4–5 — cascade the SFU. For conferencing products. Cap each SFU at a known bandwidth or participant limit, cascade rooms across nodes, route by geography.
Week 5–6 — observability and runbooks. Grafana dashboards on the KPIs below. Alerts at 70% of capacity. Runbooks for the top five incidents. Blue-green or canary deployment so rollouts stop being outages.
Outcome we typically see: platforms that collapsed at 200–500 concurrent users reach stable 5–20k CCU inside six weeks, without touching core product code. Full migrations take longer; stabilisation does not.
Cost model: where the money actually goes
Two patterns to internalise:
Broadcast is egress-dominated. Once you have a CDN, compute is cheap and bandwidth is expensive. At scale you pay USD 0.005–0.04 per GB depending on contracted CDN and region. A 2 Mbps stream watched for 1 hour is ~900 MB, so roughly USD 0.01–0.04 per viewer-hour in egress. Transcoding is a fixed fleet cost amortised over all viewers.
Conferencing is compute-dominated. Managed services (Agora, Twilio, Daily, LiveKit Cloud) price per concurrent user or per minute — typical managed WebRTC lands USD 0.003–0.01 per participant-minute. Self-hosted SFUs on Hetzner or Equinix can be cheaper by 3–5× at steady-state scale but require a platform team.
| Workload profile | Best-fit hosting | Rough cost per unit | Notes |
|---|---|---|---|
| VOD / OTT library | Object storage + CDN | USD 0.005–0.02 / viewer-hour | Hit-rate-driven; origin costs near zero at scale |
| Live event (peaky) | Cloud transcode + CDN | USD 0.02–0.06 / viewer-hour | Burst-friendly, higher per-GB |
| Live streaming steady-state | Bare metal transcode + CDN contract | USD 0.008–0.03 / viewer-hour | Hetzner AX + Cloudflare is our common pick |
| Managed conferencing | Agora / Twilio / LiveKit Cloud | USD 0.004–0.01 / participant-minute | No ops cost; vendor lock-in |
| Self-hosted SFU | mediasoup/LiveKit on Hetzner | USD 0.0008–0.003 / participant-minute | Requires a platform team; big savings at scale |
Crossover: self-hosted SFU beats managed at roughly 30–50k participant-minutes per day, depending on geography. Below that, managed conferencing is almost always the cheaper total cost of ownership once you count engineering time.
Mini case: stabilising a live-video e-learning platform
Situation. A live-video e-learning product built on a monolithic Node server with a single SFU was collapsing at 300–400 concurrent users during the evening study rush in Asia. Webinars would degrade to audio-only, attendees would disconnect, CSAT in the app store collapsed.
What we changed in six weeks. We moved stateless services behind an ALB and autoscaled them on Kubernetes. We cascaded the SFU cluster (mediasoup) with four regional nodes — two EU, one US East, one Singapore. We put TURN behind a dedicated pool. We added Grafana dashboards for P95 startup, join failures and SFU CPU, with alerts at 70% capacity.
Outcome. Stable 8–10k CCU on the same product code, P95 join < 1.5s, rebuffer ratio down from 4.1% to 0.6%. Monthly infra cost went up by roughly USD 6k, avoided an estimated USD 400k rebuild, and unblocked a new enterprise tier. The pattern is repeatable across scalable video management systems and interactive live tools in general.
Want a similar assessment on your platform? Book a 30-minute call; we usually leave it with a one-page punch list you can ship next sprint.
A decision framework — scale your video platform in five questions
Q1. Broadcast or interactive? One publisher to many viewers → HLS + CDN. Many-to-many with <200ms interactivity → WebRTC SFU. Hybrid (live class with Q&A) → both, wired together.
Q2. What is the real latency budget? Write it down in milliseconds. Do not let anyone negotiate it up later without redesigning the pipeline.
Q3. What is the concurrency peak? Peak CCU is the number that sizes the fleet. Ordinary traffic hides the problem. Model the worst-minute of the worst-day you care about.
Q4. Managed or self-hosted media? Below ~30k participant-minutes/day managed wins on total cost. Above that, self-hosted pays back within a quarter if you have the team.
Q5. Who is on call? Video is 24/7. If there is no rotation with runbooks, you will pay that cost in outages instead of salaries.
Five pitfalls we see in almost every scaling project
1. Single origin for broadcast. No CDN, no cache layer. The first 500 viewers saturate the NIC; quality collapses region-by-region.
2. Stateful app servers. User or session state pinned to a process. No horizontal scale; sticky sessions become the new bottleneck.
3. One SFU for the world. Fine until the first global event. Cascade and regional SFUs are not optional past ~500 concurrent streams.
4. Transcoding on the app VM. CPU spikes crash the API. Move transcoding to its own fleet or a managed service.
5. Zero observability. No rebuffer dashboard, no startup-time histogram, no SFU CPU alert. You will find out when a customer tweets, not before.
KPIs: what to monitor every week
Quality KPIs. P95 startup time < 3 s (broadcast) or < 1.5 s (interactive). Rebuffer ratio < 1%. Video start failures < 0.5%. MOS ≥ 4.0 (conferencing). Glass-to-glass P95 inside the budget for your use case.
Business KPIs. Concurrent viewers, session duration, watch-through rate, churn by region, cost per viewer-hour or per participant-minute. These pay for the whole program.
Reliability KPIs. Origin and SFU CPU (alert at 70%), TURN bandwidth utilisation, error rate per region, P99 join latency, deployment failure rate, MTTR under 30 minutes. Treat the video plane like a payments system; if it is down, revenue bleeds.
When not to build custom scalability
Early MVP with unknown demand. Use managed services (Mux, Cloudflare Stream, LiveKit Cloud, Agora, Daily) to buy time. Custom pays off after you have a reliable growth curve.
Very small audience, very long product life. 200 active users on a tutoring app: managed forever. The engineering cost of DIY dwarfs the savings.
Team without WebRTC / streaming expertise. Self-hosted SFUs and transcoders are unforgiving. If you do not have — or cannot hire — that skill, stay managed.
Commodity use-case inside someone else’s ecosystem. A meeting widget inside an EMR usually belongs on Amazon Chime SDK or Zoom SDK, not on a bespoke SFU fleet.
Thinking about migrating off Agora or Twilio?
We have run the migration multiple times (mediasoup, LiveKit, Janus). Tell us your CCU and we will come back with a TCO delta and a realistic timeline.
FAQ
What does “scalable” actually mean for a video platform?
It means the system can grow its concurrent users or sessions by at least an order of magnitude without a proportional increase in cost, latency or failure rate. Practically: P95 startup and rebuffer ratio stay inside your budget, SFU and origin CPU stay below 70%, and adding more capacity is a matter of scaling a group, not redeploying a stack.
Should I build on WebRTC, HLS, or both?
Broadcast (VOD, sports, concerts) with 5–30s latency tolerance: HLS/DASH + CDN. Group calls, interactive rooms, courtrooms, telehealth: WebRTC SFU. Interactive live (classrooms, streaming gyms, auctions): usually both — WebRTC for the active participants, HLS or LL-HLS for the passive long-tail audience.
Why do small platforms break so easily during growth?
Early versions tend to rely on a single origin, a stateful Node process, and a shared VM handling both API and transcoding. All three collapse under real traffic. The fix is not size; it is structure — CDN, stateless services, dedicated transcoding, monitoring.
Is scalability just about buying more servers?
No. Hardware does not fix a structural bottleneck; it just makes the failure mode louder. You can add ten servers behind a single origin and still see 100% of viewers hit that origin. Spend on CDN, stateless redesign and monitoring first; then scale the compute.
Can an overloaded system be stabilised without a full rebuild?
In most cases, yes. A focused 2–6 week program covering CDN, stateless services, SFU cascade, dedicated transcoding and monitoring usually buys a 10× increase in safe concurrency. A full rebuild is occasionally necessary (for example when the whole app is built around a broken WebSocket signalling protocol), but it is the exception.
How long does it take to make a video platform scalable?
Quick wins (CDN in front of origin, async transcoding, basic dashboards) land in days. A full stabilisation program — including SFU cascade, autoscaling, blue-green deployments and observability — takes 4–8 weeks for most platforms. A custom from-scratch build is a 4–9 month effort depending on scope.
How do I know my platform is actually scalable?
Load-test to 2× your expected peak and watch the KPIs. P95 startup stays < 3s, rebuffer < 1%, no region falls below target quality, SFU CPU stays < 70%. Combine with a chaos test (kill a region, drop a node) — if the platform rides through, you are good. If any of those go red, you have a scaling gap.
Does Fora Soft offer a free scalability audit?
Yes. The first scoping call is free. If you want a formal code and architecture audit we can deliver that as a fixed-price one-week engagement, typically producing a prioritised punch list and a realistic budget range for stabilisation.
What to Read Next
Architecture
WebRTC Architecture Guide for Business (2026)
SFU, MCU, cascade and TURN explained for product leaders picking a conferencing stack.
Streaming
Best Technologies for Video Streaming App Development in 2024
The technology stack choices behind video streaming app development.
Migration
Agora.io Alternative: Custom WebRTC with LiveKit, mediasoup, Jitsi & Janus
TCO and migration playbook when managed conferencing gets too expensive at scale.
VMS
Scalable Video Management Systems in 2026
The five engineering decisions that actually matter when VMS goes past a few thousand cameras.
Cost
How to estimate server cost for a video platform
A CCU-driven cost model that puts real numbers against real workloads.
Build guide
Building a streaming app: VOD, live and video conferencing
End-to-end product build guide for founders picking the right video pattern from day one.
Ready to scale your video platform without breaking it?
Scalability in video is never “buy more servers”. It is a set of structural decisions: stateless compute, CDN-first edge, ABR, horizontal SFUs, dedicated transcoders, serious monitoring. Streaming and conferencing each have their own version of this playbook; solving them with the same architecture is the most expensive mistake in the category.
Most platforms that are struggling today can be stabilised within six weeks. The remaining 20% need a more serious re-architecture, and that is usually worth doing once the stabilisation buys enough runway to plan it properly. Either way, measure the right KPIs, keep humans in the loop, and design for the growth curve you actually expect — not the one you hope for.
Let us scope your scalability program
Thirty minutes, a real engineer, a one-page plan: bottlenecks, priorities, realistic budget and timeline. Free.








