



Key takeaways
• Audio emotion detection is a solved problem in the lab — and broken in the wild. Fine-tuned wav2vec2/HuBERT reach ~73% weighted accuracy on IEMOCAP speaker-independent (a flattering ~80% in the speaker-dependent split), then fall to 55–65% on real call-center audio. Treat the benchmark number as marketing, not a spec.
• Multimodal fusion (voice + transcript sentiment) is the 2026 default. It adds several points of accuracy over voice alone (about 8 in one 2025 5-class benchmark) and makes the difference between “detects arousal” and “knows your customer is frustrated.”
• The build-vs-buy line is clear. Hume EVI’s 2026 tiers run about $0.04–0.06/min (Pro is $70/month for 1,200 minutes; Scale is $200 for 5,000), so at 100k minutes/month managed costs several thousand dollars a month while a self-hosted wav2vec2 pipeline runs $500–1,000 fully loaded. Managed buys speed and zero MLOps; self-host wins on cost and control at scale.
• Regulation matters more than the model. The EU AI Act’s Article 5 ban on workplace and school emotion inference went live in February 2025, and its Article 50 transparency duty — you must tell every person exposed that an emotion system is running — is enforceable from 2 August 2026 and was not deferred by the Digital Omnibus. Voice emotion is biometric data under GDPR and PHI under HIPAA. Design your legal surface first, your model second.
• Fora Soft ships these systems end-to-end. 250+ projects since 2005, a 100% Upwork success rate, and a standing stack of fine-tuned SER models and multimodal fusion heads we can deploy for your domain.
Why Fora Soft wrote this playbook
Audio emotion detection is one of those problems where a Jupyter notebook in a blog post looks suspiciously close to a product — and then production audio hits, and everything falls apart. We’ve shipped emotion-aware features for virtual classrooms, telemedicine platforms, call-center analytics and voice agents, and watched a lot of first-time teams mistake a flattering IEMOCAP benchmark score for a production SLA. This guide is what we actually do when we build this for a client: where the model choice matters, where it doesn’t, and where the EU AI Act quietly rewrites your architecture.
Our BrainCert virtual classroom uses voice and video engagement signals to flag students who need a nudge. CirrusMED’s HIPAA-grade telemedicine infrastructure is the kind of regulated environment where voice biometrics have to be treated as PHI from day one. Our AI integration practice has shipped fine-tuned wav2vec2 pipelines into production for analytics, moderation and agent coaching — and the recommendations below come from those builds.
Building an emotion-aware voice product?
Book a 30-minute call with our voice AI lead. We’ll map your use case to the right SER stack, flag the regulatory fault lines, and share a build-vs-buy recommendation you can take back to your CTO.
Market context: why emotion detection is suddenly a line item
Emotion-aware voice is in product because two things changed at once. Models crossed the “useful, not novelty” threshold — wav2vec2 and HuBERT make a strong IEMOCAP benchmark score accessible from a `pip install` — and voice agents became the UX pattern everyone wants to copy since the launch of OpenAI Advanced Voice Mode and Gemini Live. The emotion-AI market is tracking from roughly $4.2B in 2024 toward about $21B by the early 2030s (Fortune Business Insights, ~22% CAGR), and emotion analytics has moved from pilot to line item across the contact-center vendors we work with.
At the same time the regulatory fence went up. The EU AI Act’s February 2025 ban on workplace and school emotion inference is the first hard perimeter most teams have had to design around. That combination — cheap accurate models and narrowing legal surface — means the 2026 build-vs-buy and legal choices matter more than any one hyperparameter.
What audio emotion detection actually is in 2026
Speech Emotion Recognition (SER) is the discipline of inferring a speaker’s emotional state from their voice signal alone. In 2026 the field has converged on three useful ways to label emotions, and picking the right one is most of the design decision.
Categorical models. Ekman’s six basic emotions — happy, sad, angry, fear, surprise, disgust — usually plus a neutral class, sometimes extended further. Easy to explain to stakeholders, easy to log, easy to visualize. Weak when the user is “frustrated but polite” or “sad but trying to hold it together,” because the label space doesn’t have those cells.
Dimensional models. Valence (positive/negative), arousal (high/low energy), dominance (in control / not). Measured as continuous scores, usually 0–1. Better for nuance — “angry” and “excited” are both high arousal but different valence. The standard academic metric is Concordance Correlation Coefficient (CCC), and SOTA models on MSP-Podcast hit 0.76–0.82.
Fine-grained taxonomies. Hume AI’s commercial model exposes 48 classes including states like “stressed yet focused,” “confused,” “vulnerable.” Impressive for voice agents that need to personalize tone, proprietary to the vendor, and harder to audit for bias.
A 2026 reference architecture in one picture
Most production SER pipelines look the same once you strip away vendor branding. The four-stage flow below is the template we reach for on day one:
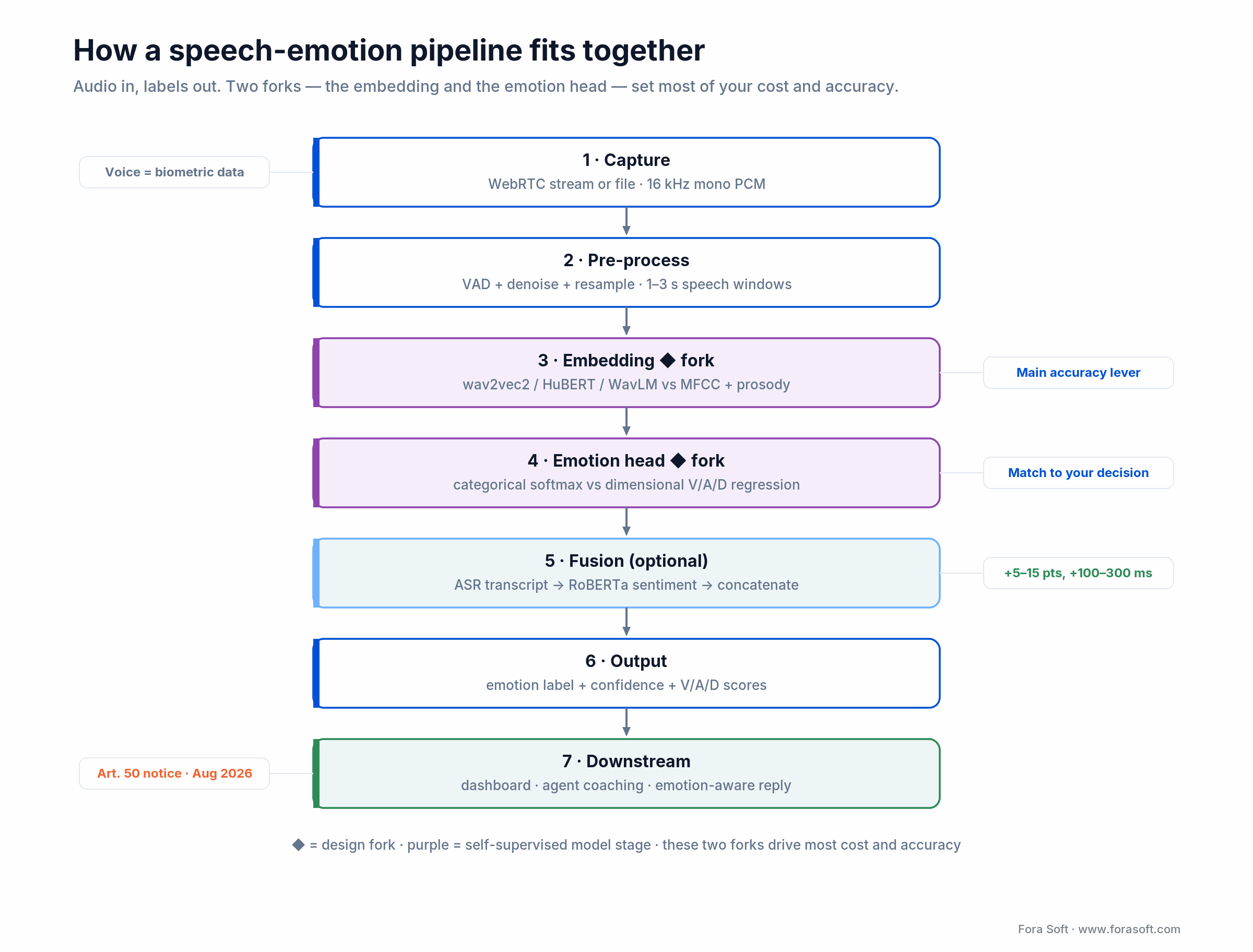
Figure 1. The two forks — embedding and emotion head — decide most of your cost and accuracy.
Two decisions determine most of the cost and accuracy. First, which embedding layer you use (self-supervised transformer vs classical features) — self-supervised wins on accuracy, classical wins on explainability and cost. Second, whether you add the text-sentiment fusion head — which adds 100–300 ms of latency but 5–10 points of accuracy and is, in our experience, table stakes for any analytics use case.
Five model choices that cover 95% of projects
wav2vec2 fine-tuned on IEMOCAP / MSP-Podcast
The workhorse. Fully fine-tuned, wav2vec2/HuBERT checkpoints reach roughly 73% weighted accuracy on IEMOCAP speaker-independent (Wang et al., 2021); off-the-shelf SUPERB baselines land in the low-60s. They expose a simple AutoModelForAudioClassification interface, so fine-tuning on 500–1,000 hours of domain audio is where the accuracy actually comes from. Runs fast on CPU after ONNX export and quantization.
# wav2vec2 SER inference in a few lines (Hugging Face)
from transformers import pipeline
clf = pipeline("audio-classification",
model="superb/wav2vec2-base-superb-er") # IEMOCAP-style labels
scores = clf("call_segment_16k.wav") # 16 kHz mono, 1–3 s window
print(scores[0]) # {'label': 'ang', 'score': 0.71}
The checkpoint above is the SUPERB baseline (about 63% on IEMOCAP out of the box). The low-70s figures come from a fully fine-tuned model on in-domain audio — which is the whole point of the fine-tuning step.
HuBERT — the small accuracy upgrade
Meta’s second-generation self-supervised encoder. A couple of points better than wav2vec2 on speaker-independent IEMOCAP (mid-70s WA versus wav2vec2’s ~73%) and noticeably better on cross-dataset generalization, at a similar compute footprint. Worth it if accuracy is paying the bill.
Dimensional wav2vec2 on MSP-Podcast
If you need valence/arousal/dominance instead of discrete labels, audeering’s public wav2vec2-large dimensional model (their MSP-Dim checkpoint on Hugging Face) is the SOTA. CCC around 0.76–0.82 on MSP-Podcast, trained on the largest naturalistic corpus available. Better for nuanced analytics.
Reach for dimensional models when: you’re building coaching dashboards, CSAT prediction or mental-health screening where “how intense?” and “positive or negative?” matter more than a single label.
Classical features (openSMILE + SVM/LSTM)
~6,000 hand-crafted low-level descriptors (MFCC, pitch, energy, voice quality) plus a simple classifier. Ceiling sits at 65–72% WA — lower than neural models — but inference is CPU-cheap, the features are interpretable (useful when legal needs to audit them), and the footprint is small enough for edge. One licence trap: openSMILE is dual-licensed — the open-source build may not ship inside a commercial product without a paid audEERING licence, and that restriction extends to features extracted with it. For a commercial build, pull the same descriptors with librosa or torchaudio, which are permissively licensed.
Hume AI EVI / Octave
The managed option. 48-class output, sub-300 ms latency, unified conversation+emotion model, HIPAA-ready enterprise tier. Pricing in 2026 is tiered: Pro is $70/month for 1,200 EVI minutes (about $0.06/min), Scale is $200/month for 5,000 minutes ($0.04/min), and Business is $500/month for 12,500 minutes ($0.04/min); the entry rate is still around $0.07/min. Worth it when you want to skip the MLOps entirely at low-to-mid volume; self-hosting wins on unit economics once you are well past a plan’s minute bucket.
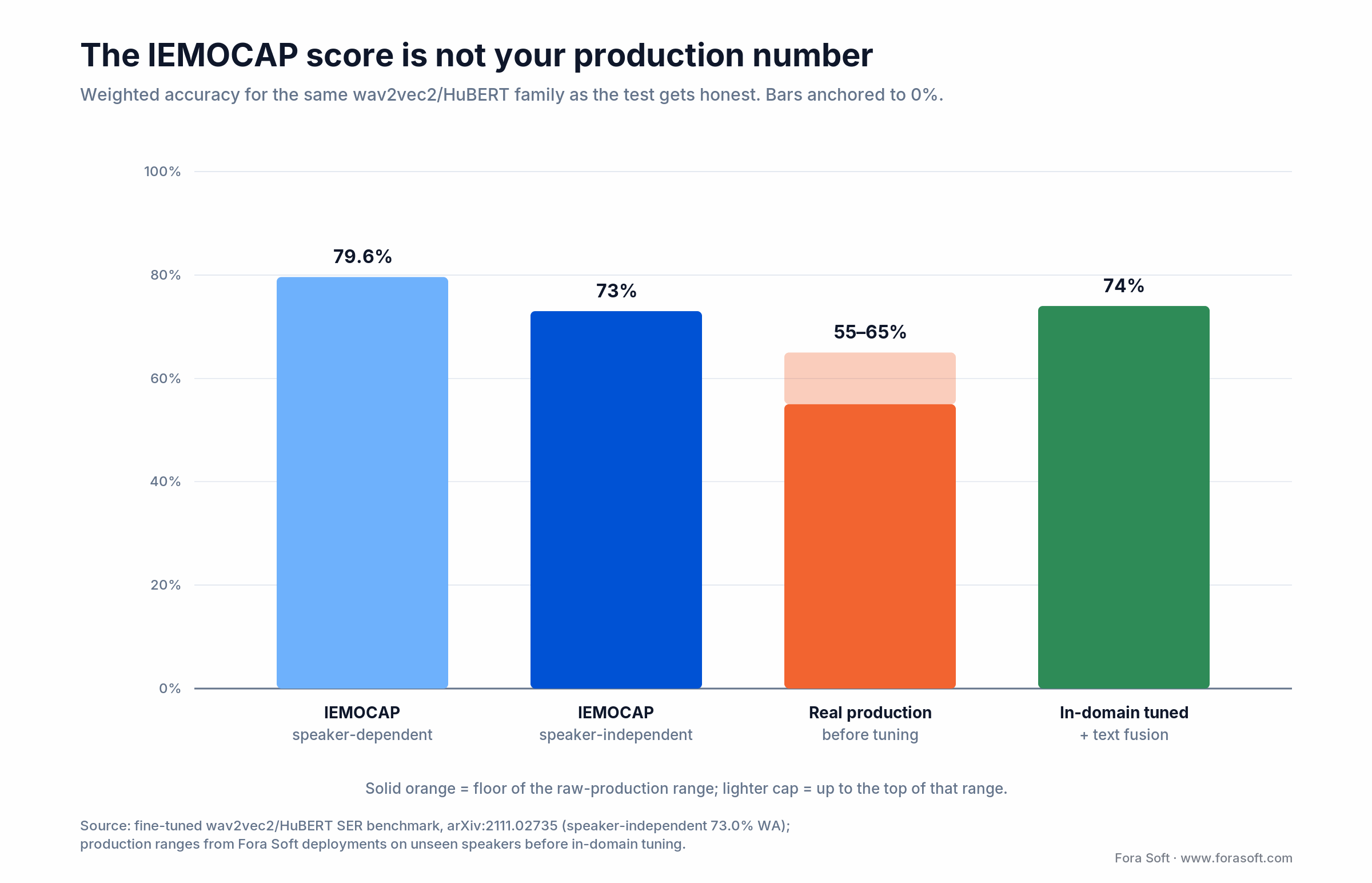
Figure 2. The same model family, four honesty levels. Your production number is the speaker-independent one, minus domain shift.
Commercial providers compared — 2026 feature matrix
Rate cards are public at the time of writing; volume discounts move things 30–50%. “Voice emotion” means direct acoustic modelling; “text emotion” means sentiment inferred from the ASR transcript only.
| Provider | Modality | Latency | Price / min | Best for |
|---|---|---|---|---|
| Hume AI EVI / Octave | Voice + text fusion | <300 ms | $0.04–0.07 (tiered) | Real-time voice agents, 48-class output |
| Deepgram Sentiment | Text on ASR transcript | <500 ms | ~$0.008 (usage-based) | Cost-sensitive analytics, call centers |
| AssemblyAI LeMUR | Text sentiment + topics | batch / near-real-time | $0.012 + add-ons | Post-call analytics, summarization |
| Symbl.ai | Text emotion + intent | near-real-time | Custom | Conversation intelligence |
| NVIDIA Riva | Voice (on-prem) | <100 ms | License | Regulated industries, offline |
| Self-hosted wav2vec2 | Voice (+ optional text) | ~100–200 ms | <$0.001 at scale | High-volume, custom domain |
Reach for Hume EVI when: you’re prototyping a voice agent, need 48-class granularity, or you simply want someone else to own the MLOps. Managed is the right call at low-to-mid volume; once you are into hundreds of thousands of minutes a month, self-hosting is materially cheaper.
Multimodal fusion: why voice alone is never enough
The single biggest jump in SER quality between 2024 and 2026 came from fusing voice embeddings with text sentiment on the transcript. Two reasons. First, prosody is ambiguous — high arousal can be excitement, panic or anger, and voice alone can’t always split them. Second, word choice carries most of the semantic load: “I’m fine” can be said eight different ways, and the text signal removes half of them.
The standard pattern: run streaming ASR (Whisper, Deepgram, AssemblyAI) in parallel with the SER encoder; take the CLS-token embedding from a RoBERTa/DistilBERT fine-tuned for sentiment; concatenate with the voice embedding; pass through a small fusion head. Peer-reviewed 2025 results show 0.83 accuracy on 5-class emotion (vs 0.75 voice-alone, 0.78 text-alone) with this architecture. For us that’s the jump between a demo and a product.
Latency budget: what “real-time” means here
Real-time emotion detection isn’t the same latency problem as real-time ASR. SER needs a window of 1–3 seconds of speech to classify reliably; any shorter and the model is guessing, any longer and the interaction feels ghostly.
Typical budget for a voice-agent loop: 150–300 ms audio buffer, 50–150 ms SER inference (quantized ONNX or GPU), 100–200 ms optional fusion, 200–400 ms downstream LLM response, 100–300 ms TTS first-audio. Total: roughly 600–1,000 ms. Any slower and the user notices the “thinking” moment.
For post-call analytics the budget is minutes, not milliseconds, and you can push HuBERT-large + fusion through batches at a fraction of the unit cost. Don’t over-engineer — use the heavier model where it’s free.
Need an SER benchmark on your own audio?
Send us 10 minutes of real production audio and we’ll benchmark three engines side by side — wav2vec2, HuBERT, and the best-fitting managed API — with a written recommendation inside a week.
Datasets: stop training on acted speech
The single most common production failure is a model that scored 85% on RAVDESS (24 actors performing emotions on command) and then lands in a real call center where nobody is “performing angry.” Accuracy halves. The fix is choosing training data that looks like your users:
RAVDESS — 1,440 clips, 24 actors. Fine for prototypes, nothing else.
IEMOCAP — 12 hours, 10 speakers, acted + improvised. The standard academic benchmark but tiny.
CREMA-D — 7,442 clips, 91 actors, better demographic diversity.
MSP-Podcast — hundreds of hours of naturalistic podcast speech from thousands of speakers, with dimensional (valence/arousal/dominance) annotations. The corpus we build on whenever its licence fits the target domain.
Your own labeled data — always the biggest accuracy lever. 500–1,000 hours of in-domain audio with even noisy labels consistently beats public-only training. Plan the labeling pipeline as part of the project, not as an afterthought.
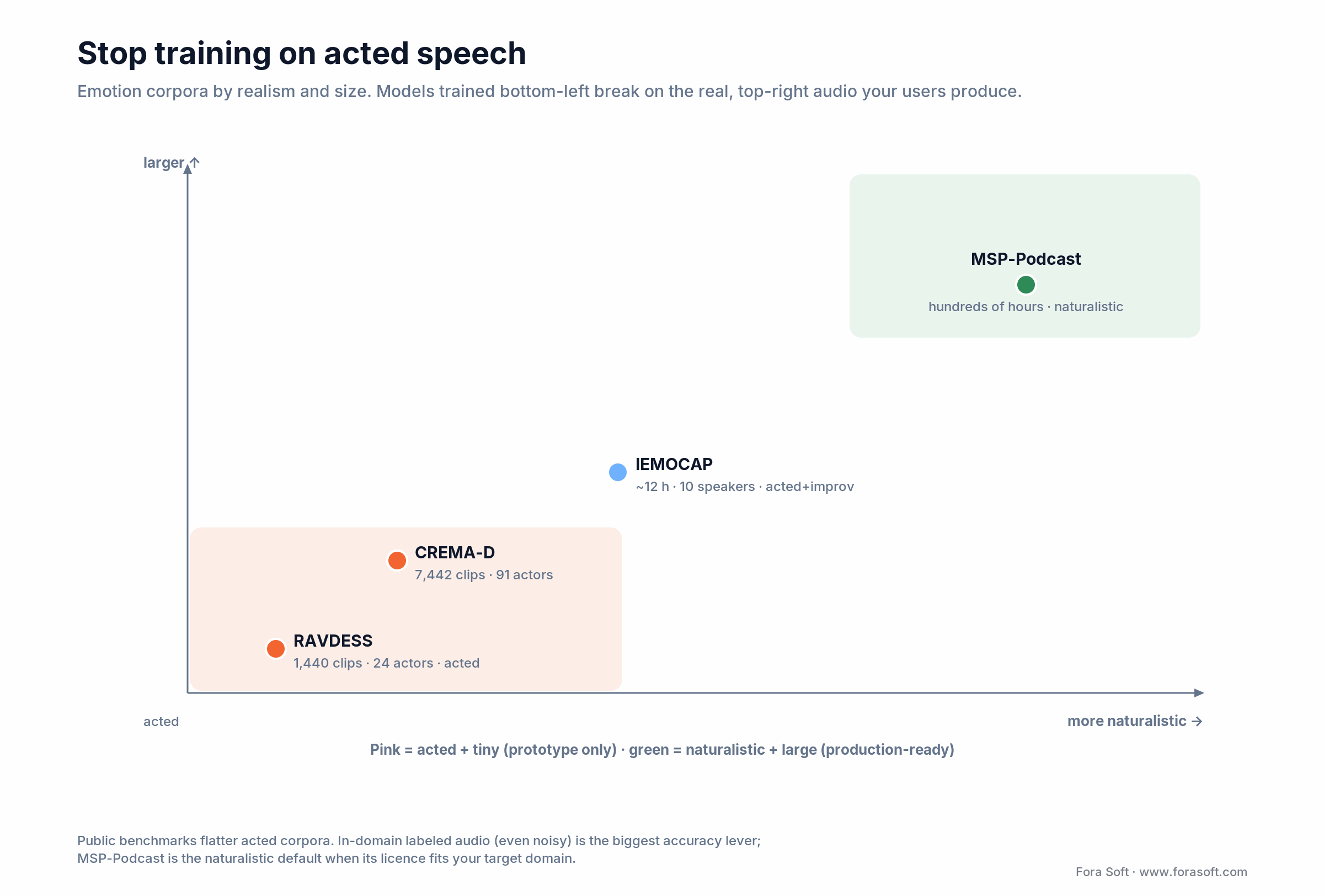
Figure 3. Train bottom-left, ship to top-right, and accuracy collapses. MSP-Podcast or in-domain audio is the fix.
Reach for self-hosted wav2vec2 when: your monthly audio volume sits above ~500k minutes, you already run in-house GPU infrastructure, or your compliance surface (HIPAA, EU data residency) means you can’t ship raw voice to a third-party API. The unit economics below 0.1¢/minute are hard to beat once you’re past the ramp.
EU AI Act, GDPR and HIPAA — the legal surface
EU AI Act, Article 5(1)(f). In force since 2 February 2025. Inference of emotions in workplaces and educational settings is a prohibited practice — with medical-safety exceptions. Fines go up to €35 million or 7% of global turnover. In practice this kills use cases like agent scoring, interview emotion analysis and classroom engagement tracking inside the EU. Customer-facing call-center analytics are still allowed, but you must document the purpose carefully.
EU AI Act, Article 50(3) — the 2 August 2026 transparency duty. This is the rule most teams missed. From 2 August 2026, any deployer of an emotion-recognition system must inform the people exposed to it that it is running — whether or not the system is “high-risk.” The Digital Omnibus package pushed several high-risk deadlines out to December 2027, but it left Article 50 untouched, so this one is live now. Practically: build the disclosure into your consent UX and call flow before launch, not after.
GDPR. Voice emotion is biometric data under Article 9. That means explicit opt-in consent (pre-ticked boxes are void), a clear lawful basis, strict retention limits, and subject-access rights over inferred labels. Bake this into the ingestion pipeline from day one — retrofitting consent UX after launch is a mess.
HIPAA. If SER informs clinical decisions (depression screening, post-op follow-up, telemedicine), voice audio is Protected Health Information. Self-host models, sign BAAs with any cloud vendor, encrypt in transit and at rest, and log access granularly. CirrusMED is the kind of build where we treat the compliance layer as the first architectural constraint.
Bias. Emotion expression varies across culture, gender, age and language. Models trained on US English under-perform by 10–15% on Indian English, Mandarin, Arabic, and on non-native speakers. Publish per-demographic fairness metrics and avoid using voice-only emotion as a single signal for any high-stakes decision.
Where audio emotion detection actually pays off
Call-center analytics. Agent coaching, CSAT prediction, escalation routing. Still the highest-ROI use case — a 10% lift in first-call resolution typically pays for the whole project. Our piece on real-time audio emotion analysis goes deeper on the business case.
Voice agents with emotion-aware responses. Hume EVI is the reference product here. Emotion steers tone selection in the LLM prompt and TTS delivery; the user perceives the agent as “listening.” Easy to demo, harder to operationalize, high stickiness when it works.
Healthcare screening. Depression and anxiety monitoring via vocal biomarkers. Strongly regulated, needs clinical validation, but genuinely useful in telemedicine follow-ups. HIPAA everywhere.
E-learning engagement. Flag disengaged students in live classes. Our emotion analysis for learning playbook and our AI for video engineering course are good starting points.
Content moderation. Toxic or aggressive speech in gaming and social audio. Works alongside text-based moderation, not as a replacement.
Automotive. Driver fatigue or road-rage detection as part of ADAS. Safety exception under Article 5 but still needs careful consent design.
Mini case — call-center emotion analytics in 10 weeks
A US BPO came to us with 1.2 million minutes of English inbound calls per month, a QA team reviewing 6% of them manually, and a leadership team asking why first-call resolution was flat. They had already experimented with a public wav2vec2 checkpoint against RAVDESS and shelved the project because production accuracy came in at 58% and the QA team stopped trusting the dashboard.
Our 10-week rebuild swapped the model to a HuBERT fine-tuned on their 900-hour in-domain corpus plus MSP-Podcast, added a RoBERTa text-sentiment fusion head on the Deepgram transcript, shipped the whole thing on a self-hosted GPU cluster, and rebuilt the QA dashboard to sort calls by confidence-weighted negative-valence score rather than by a hard category label. Latency stayed under 400 ms for the streaming branch; the batch branch ran at roughly $0.0008/min fully loaded.
Result: production weighted accuracy climbed to 74% on a stratified holdout, QA call coverage jumped from 6% to 38% without adding headcount, and agent-coaching sessions tied to the dashboard correlated with a 9.2-point CSAT lift over the following quarter. Want a similar assessment? Book a 30-minute slot and we’ll sketch the path for your stack.
Cost math: what an SER pipeline really costs at scale
A round number for planning: assume 100,000 minutes of audio per month across a small B2B deployment.
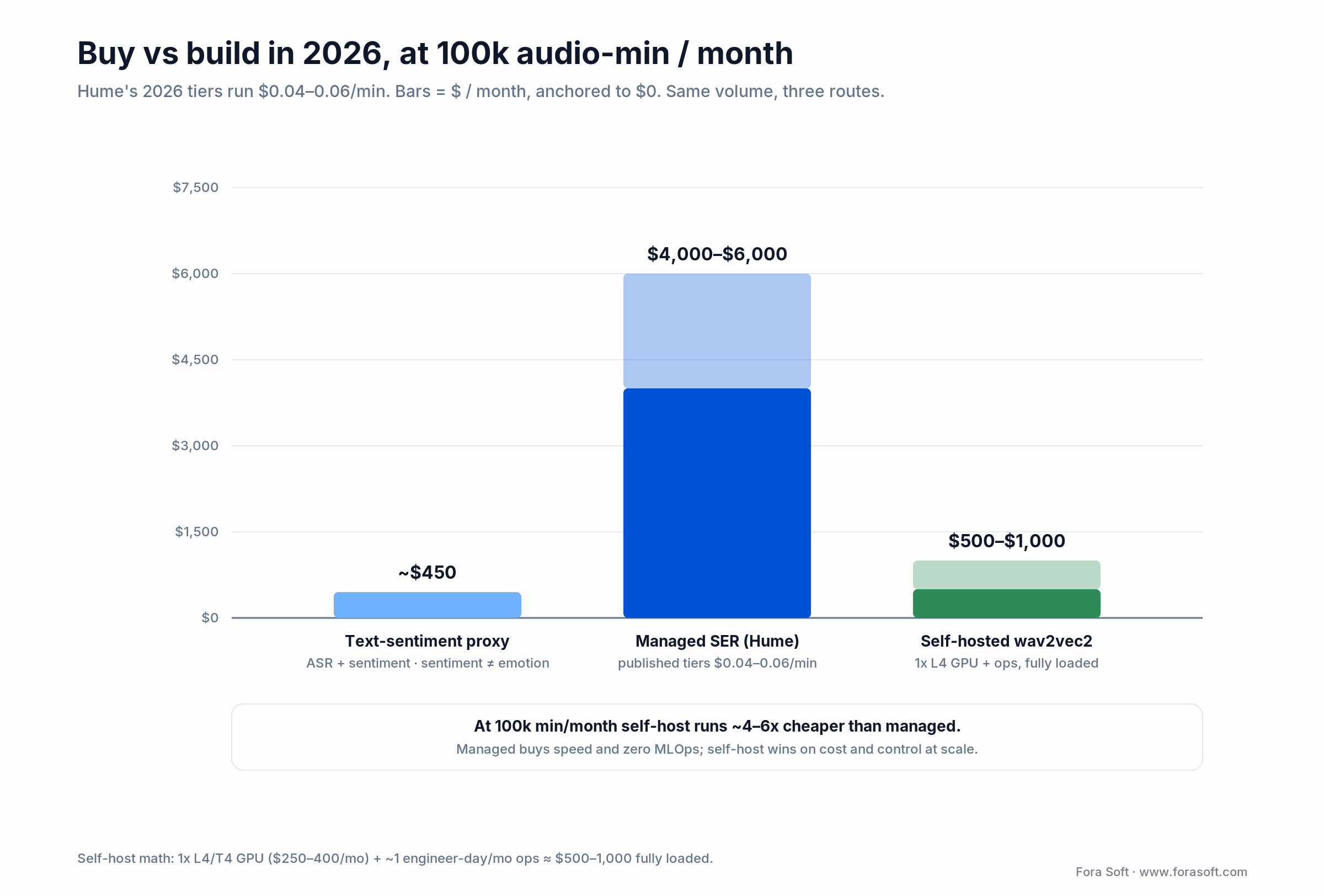
Figure 4. At 100k minutes/month self-host runs several times cheaper than managed. Managed buys speed and zero MLOps; self-host wins on cost at scale.
Managed SER (Hume EVI): at published tier rates of $0.04–0.06/min, roughly $4,000–6,000/month at this volume (enterprise discounts apply). No MLOps overhead, but the per-minute rate dominates once you are past a plan’s minute bucket.
Text-sentiment proxy (Deepgram-style): a few hundred dollars a month for ASR + sentiment, plus your own dashboard. Cheapest route — but sentiment on a transcript is not acoustic emotion, so it answers a narrower question.
Self-hosted wav2vec2 on a single NVIDIA L4/T4: ~$250–400/month in GPU time at the same volume. Add an engineer-day per month for ops and drift monitoring, and the fully-loaded cost sits around $500–1,000/month. Accuracy matches or beats Hume if you fine-tune on domain data.
Crossover rule of thumb (2026): stay managed while your volume fits inside a subscription bucket (up to ~12,500 minutes on Business); above that, self-hosting is several times cheaper per month. Benchmark both around the crossover and choose on total cost plus compliance, not sticker price alone.
A decision framework — pick your SER stack in five questions
Q1. Real-time or batch? Real-time (voice agent, live captions, IVR) means streaming-friendly managed APIs or a tightly tuned self-hosted pipeline. Batch (post-call analytics, research) opens the door to heavier models and lower cost.
Q2. Where do your users live? EU, UK and GDPR-heavy jurisdictions narrow the legal surface sharply. Workplace or school deployments inside the EU basically rule out SER — pivot to customer-facing or medical-safety framings.
Q3. Categorical, dimensional or fine-grained? Match the label space to the downstream decision: categorical for branching agent logic, dimensional for analytics and coaching, fine-grained only when a Hume-style product is the core value.
Q4. What’s the volume horizon? Under 100k min/month — start managed. Between 100k and 1M — decide by accuracy. Above 1M — self-host almost always, unless compliance demands a specific vendor.
Q5. Do you have labeled in-domain audio? If yes, self-hosted wav2vec2/HuBERT fine-tuning is the highest-ROI move. If no, start with managed for a quarter while you collect labels, then migrate.
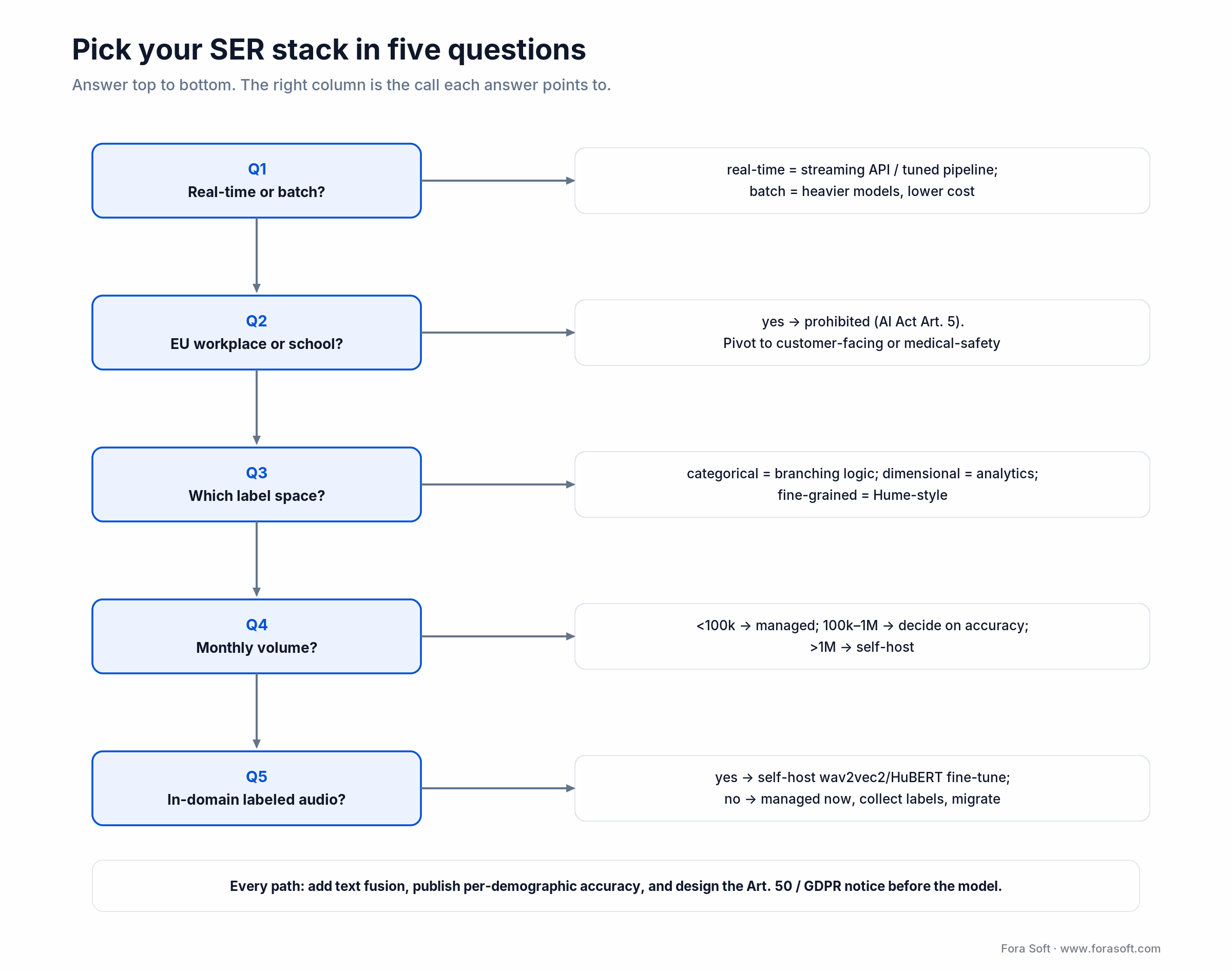
Figure 5. Five questions, one stack. Every path still needs text fusion, fairness metrics and the Art. 50 notice.
Five pitfalls we see on every first project
1. Training on acted data, shipping to natural speech. RAVDESS is a toy. Production needs MSP-Podcast-like data or in-domain labels. Budget the labeling effort up front, not at the end.
2. Voice-only models in a bilingual user base. Prosody collapses across languages. Always add text-sentiment fusion for multilingual products.
3. Confusing categorical and dimensional models. You can’t threshold “sadness” if the model outputs a valence score of 0.32. Pick the label space first, pick the model second.
4. Legal surface as an afterthought. The EU AI Act and GDPR rewrite the architecture — where you store audio, how long, under whose BAA, which fields get redacted. A retrofit costs months.
5. No fairness audit. Aggregate 78% WA can hide 85% on white, 35-year-old, male US English speakers and 62% on everyone else. Per-demographic metrics are table stakes in 2026.
KPIs that matter beyond weighted accuracy
Quality KPIs. Weighted accuracy and unweighted accuracy on a stable in-domain test set (target >70% in real production), per-class F1 (avoid dominating by the “neutral” class), CCC on dimensional outputs (>0.70 for valence and arousal), and per-demographic subgroup accuracy within 5 points of the overall mean.
Business KPIs. Agent-coaching CSAT lift, first-call resolution delta, churn prediction uplift, engagement-based intervention conversion — whichever matches the use case. Without a downstream KPI the model score is vanity.
Reliability KPIs. P95 inference latency (<200 ms streaming, <10 min batch), model-drift detection triggers (weekly KL-divergence on output distribution), fraction of sessions flagged low-confidence (<15%), and incident rate per million minutes processed.
When not to use audio emotion detection
Skip or defer SER if (a) your decision is high-stakes and voice is the only signal — the 2026 evidence doesn’t support that, (b) you’re deploying into a prohibited EU use case (workplace or school) without a medical-safety framing, (c) you don’t have in-domain labeled audio and aren’t willing to collect any, or (d) a text-sentiment proxy would solve 80% of the problem at a fraction of the cost. A text-only sentiment pipeline is a perfectly respectable v1 and often the right answer.
Reach for a hybrid pipeline when: you need real-time response plus deep post-call insight. A quantized wav2vec2 head on the streaming path plus an ensemble HuBERT+fusion on the batch path gives you both without blowing the latency budget.
FAQ
How accurate is audio emotion detection really?
On IEMOCAP, fine-tuned wav2vec2/HuBERT models land about 73% weighted accuracy speaker-independent (roughly 80% in the flattering speaker-dependent split; source: arXiv:2111.02735). Real-world production typically starts at 55–65% until you fine-tune on in-domain data and layer text sentiment on top. Multimodal fusion on a fine-tuned backbone is the 2026 baseline; anything less is a prototype.
Is Hume AI worth it in 2026?
At low-to-mid volume, yes. Hume’s 2026 tiers ($70/month for 1,200 EVI minutes on Pro, dropping to $0.04/min on higher plans) buy you sub-300 ms latency, a 48-class taxonomy, and zero MLOps. Once you are into hundreds of thousands of minutes a month, a self-hosted wav2vec2 pipeline with fusion is several times cheaper — that is where most high-volume teams move in-house.
Can we use audio emotion detection for HR or interview scoring?
Not in the EU. Article 5 of the AI Act explicitly prohibits emotion inference in workplaces and educational institutions as of February 2025, with fines up to €35M or 7% of turnover. In the US there’s no blanket ban but EEOC guidance is tightening, and voice emotion alone is too unreliable to survive a disparate-impact challenge. We decline these engagements and recommend clients do the same.
How long does it take to build a production SER pipeline?
A PoC on open-source models is 3–5 weeks with one engineer. A production streaming pipeline with fusion, dashboards and compliance lands in 8–14 weeks for a small team. A full call-center analytics platform is 12–20 weeks. Our agent-engineering workflow shaves ~20–30% off those numbers by automating a lot of the evaluation and fine-tuning scaffolding.
Do I need a GPU for inference?
Not necessarily. A quantized wav2vec2 model exported to ONNX runs 3-second windows in 40–100 ms on a single CPU core, which is enough for most streaming and all batch use cases. You’ll want a GPU once you run fusion models, HuBERT-large, or serve thousands of concurrent streams — but don’t default to one until load testing says so.
How do we handle multilingual or accented speech?
Use an end-to-end multilingual SSL backbone (XLSR, MMS) and add text-sentiment fusion on the transcript. Cascaded per-language models lose context at code-switch boundaries. Always evaluate per-language and per-accent subgroups and publish the results — aggregate WA hides the failures your users actually experience.
Is voice emotion really biometric data under GDPR?
Yes. Voice recordings plus inferred emotional state are biometric processing under Article 9 — a special category. You need explicit opt-in consent, a documented lawful basis, retention limits, and subject access over the inferred labels (not just the raw audio). Design this into the intake flow from the start.
What’s the single most important KPI?
Downstream business impact — CSAT lift, FCR delta, churn-prediction precision, whatever is closest to the P&L. Weighted accuracy matters, but a model that’s 82% accurate and never changes a business outcome is worse than one that’s 70% accurate and ties directly to agent coaching. Start from the KPI, pick the model that moves it.
What changes for emotion detection on 2 August 2026?
The EU AI Act’s Article 50(3) transparency duty becomes enforceable. From that date, any deployer of an emotion-recognition system in the EU must inform the people exposed to it that the system is running, regardless of whether it is classed as high-risk. The Digital Omnibus package deferred several high-risk obligations to December 2027 but left Article 50 on schedule, so plan the disclosure into your consent flow now.
Is openSMILE free to use in a commercial product?
No. openSMILE is dual-licensed: free for research and personal use, but shipping it inside a commercial product needs a paid audEERING licence, and that restriction extends to features extracted with it. For a commercial build, extract the same MFCC, pitch and prosody descriptors with librosa or torchaudio, which are permissively licensed.
What to read next
Vendor comparison
7 real-time AI emotion software solutions in 2026
Hume, Affectiva and the rest of the commercial field, side by side.
Audio + video
Emotion detection in audio and video
How voice and facial signals combine into a stronger multimodal model.
Business case
Why real-time audio emotion analysis matters
The business-outcome case for contact centers, healthcare and e-learning.
Video conferencing
AI emotion detection in video conferences
Live-meeting applications for sales, support and leadership coaching.
Education
Emotional analysis with machine learning in learning apps
How engagement signals flow into adaptive learning flows.
Ready to ship emotion-aware voice?
Audio emotion detection is no longer a research project — it’s a stack decision. Pick the label space that matches your downstream decision, use wav2vec2 or HuBERT as the backbone, add text-sentiment fusion on the ASR transcript, fine-tune on in-domain data, benchmark honestly per demographic, and design the legal and privacy surface before the model. The products that feel useful are the ones that treat emotion as one signal among several, wrap it in confidence gating and multimodal fallback, and optimize for downstream business KPIs rather than a benchmark score.
If you’d like help getting there, Fora Soft has a standing SER stack — domain-adaptation playbooks, fusion heads, MLOps scaffolding, privacy-by-design data pipelines — and a team that’s shipped it multiple times. We’d rather save you the quarter we spent learning each of those lessons.
Let’s scope your emotion-detection build
Book a 30-minute scoping call: we’ll map your use case to the right ASR + SER + fusion stack, flag the regulatory constraints, and sketch a timeline you can take back to the team.








