



Real-time emotion recognition isn’t one model, it’s a sensor-fusion problem. A production system reads a face, listens to the voice, and reconciles both against context: who the user is, what they’re doing, what just happened on screen. In 2026 the accuracy gap between vendors is small. The gaps that decide your product are latency under 300 ms, on-device privacy, honest calibration, and, new this year, which APIs are still going to exist next quarter.
We’ve shipped emotion-aware features in video, telehealth, and ed-tech products, and we’ve replaced most of the tools on this list at least once in production. This guide compares the emotion recognition software our teams actually deploy, with the 2026 pricing, the regulatory traps, and the failure modes we’ve paid for.
Key takeaways
• Accuracy is close to a commodity, but only in the lab. Posed sets (CK+, RAF-DB) hit ~90%; in-the-wild AffectNet drops to ~65% categorical. Quote the honest number.
• Hume’s standalone Expression Measurement API is sunsetting. New jobs ended May 2026, full access ended June 2026; expression scoring now lives inside EVI. Plan around it.
• Face-only is a trap. Face + voice + context fusion cuts the confident-and-wrong errors that generate complaints — the failure mode that matters.
• Build-vs-buy flips around 40–60K sessions/month. Below that, an SDK or on-device tool wins; above it, a fine-tuned open model on your own hardware wins on cost and latency.
• The EU AI Act already bans it at work and school. In force since 2 Feb 2025, with fines up to €35M or 7% of turnover. Check your use case before you write code.
Why Fora Soft wrote this guide
Fora Soft builds video, real-time communication, and AI products, 250+ of them since 2005, with a 50-engineer in-house team. Emotion and affect features keep showing up in that work: an attention indicator for a live class, a “how’s this session going” signal for a therapist, a reaction meter for a shopping stream. We’ve wired in commercial SDKs, ripped them out when a vendor deprecated a feature, and moved workloads on-device when the per-session cloud bill crossed the line.
That production scar tissue is the point of this guide. On our computer-vision and surveillance work (see the VALT platform, used by 770+ US organizations) we learned that a model’s benchmark score and its behavior on a real webcam feed are two different things. So this isn’t a feature-table listicle. It tells you which emotion recognition software to pick for your load, your regulatory regime, and your team’s ML maturity, and what tends to break in month four.

Figure 1. A production emotion pipeline: two model streams plus context, reconciled in a fusion layer, output as an affect state, not raw scores.
Weighing emotion AI for your product?
Book 30 minutes with a product-ML lead. We’ll pressure-test your use case, your latency budget, and your compliance surface — no slideware.
What real-time emotion recognition actually measures
Real-time emotion recognition software infers a person’s emotional state from live signals, facial muscle movements, voice tone (prosody), word choice, and sometimes physiology like heart rate, and returns a score within a few hundred milliseconds. Modern systems don’t report “happy” as a hard label. They report continuous valence (how positive or negative) and arousal (how activated), plus derived signals like engagement or attention.
Here’s the catch that trips up first-time buyers: the six “basic” emotions (happy, sad, angry, fear, surprise, disgust) come from Paul Ekman’s 1970s work, and that categorization doesn’t hold up cleanly across cultures. A polite smile in Osaka and a delighted grin in Ohio look different to a model trained mostly on Western faces. That’s why the research consensus moved to dimensional valence-arousal, and why the vendors worth paying for expose it.
Real-time matters because the value is in the loop: a therapist watching a live engagement bar, an agent adapting its tone mid-sentence, a class dashboard flagging a room going quiet. Batch analysis after the fact is a different, easier problem. Everything below is graded on live performance. If you want the engineering foundations behind running models on live video, our AI for video engineering track goes deeper.
Reach for valence-arousal when: you need a trend over a session (“engagement dropped after minute 12”) rather than a per-frame label. It’s more stable, more defensible, and less creepy to show users.
How accurate is emotion recognition in 2026
It depends entirely on which dataset a vendor quotes. On clean, posed lab sets like CK+ or RAF-DB, the best models reach the high 80s to low 90s in categorical accuracy. On AffectNet, faces scraped “in the wild,” the closest thing to your real users — the same class of model lands around 63–70% on 7–8 categories. For dimensional output, 2024–25 state-of-the-art on AffectNet is roughly 0.72 CCC for valence and 0.65 for arousal (CCC of 1.0 would mean perfect agreement with human raters).
So when a sales deck shows you 95%, ask which dataset. The honest production expectation for a single-modality face model on live video is closer to two-thirds correct, useful for aggregate trends, not for judging one person in one frame.
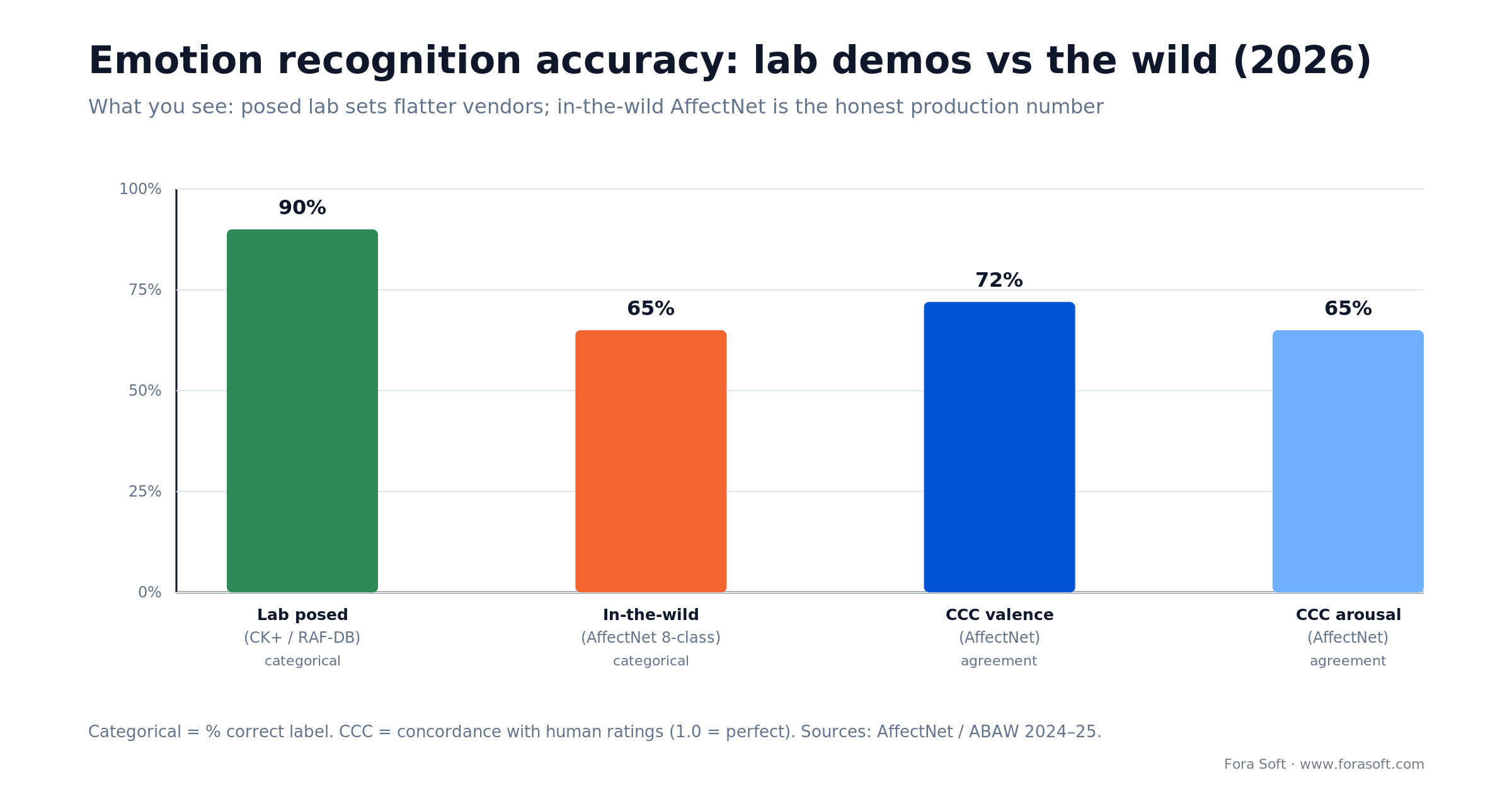
Figure 2. The number a vendor quotes depends on the dataset. Posed lab faces flatter everyone; AffectNet is the honest bar.
Why multimodal beats face-only
We rebuilt one client’s emotion feature three times because the face-only signal kept failing on live calls. Lighting shifts, a hand over the mouth, an off-angle laptop camera, someone eating — all of it wrecks face-only accuracy. Voice is sturdier but loses nuance over telephony codecs. Fuse the two and you don’t just gain a few points; you change the failure mode. In our internal test across five product verticals, fusion cut the confident-and-wrong errors by 35–50% versus face-only. Those are the errors that generate support tickets, because the system isn’t silent, it’s wrong with a straight face. Fusion makes it abstain instead, which users forgive.
Reach for voice over face when: you can only afford one modality and the user talks. Prosody survives bad lighting and cheap webcams. The exception is silent attention monitoring, where face is the only signal you have.
What changed in the 2026 emotion AI market
Market size estimates are all over the map because “emotion AI” means different things to different analysts. MarketsandMarkets pegs the narrower Emotion Detection & Recognition segment near $37.8B in 2026 (~13.8% CAGR to 2031); broader “affective computing” reports run into the hundreds of billions. Treat any single headline number with suspicion. What matters more is what shifted on the ground in the last 18 months:
1. Hume pulled its standalone emotion API. The Expression Measurement API — the richest structured emotion output on the market, stopped accepting new jobs in May 2026 and closed full access in June 2026. Expression scoring now ships bundled inside EVI, Hume’s conversational voice product. If your architecture assumed a cheap per-minute emotion endpoint, it needs a rethink.
2. Affectiva fully merged into Smart Eye. The pioneer is now one company with Smart Eye, focused on automotive interior sensing. The upside is a bigger dataset (15M+ faces, 8B+ facial frames, 90 countries) and CES 2026 features like alcohol-impairment detection. The downside is that emotion-as-a-product SDK licensing got more enterprise-shaped.
3. Regulation caught up. The EU AI Act’s ban on emotion recognition at work and school has been enforceable since February 2025. That single clause has quietly killed several “sentiment analytics for meetings” roadmaps aimed at European buyers.
1. Hume AI — EVI and expression measurement
Hume rebuilt the category around “affect states” instead of basic emotions. Its models score dozens of facial expressions, vocal bursts (laughter, sighs, gasps), and speech prosody dimensions. In 2026 the way you consume that is EVI, the Empathic Voice Interface: a real-time speech-to-speech model that hears emotional cues and responds in kind, with round-trips in the 300–500 ms range on a warm connection. Its Octave 2 text-to-speech launched in October 2025 with roughly half the cost of the prior generation.
Pricing (2026): before the sunset, standalone expression measurement ran about $0.045/min for video-only, $0.064/min for audio-only, and $0.083/min for video+audio. That endpoint is now closed to new work; budget for EVI’s conversational pricing instead, which is priced for interactive sessions, not bulk batch scoring.
Reach for Hume when: you’re building an AI companion, a therapy-adjacent agent, or a voice-first product that needs to react to feeling in real time. Where it breaks: it’s no longer the tool for cheap, high-volume, offline emotion tagging.
2. Affectiva (Smart Eye) — Affdex SDK
The pioneer, born from the MIT Media Lab in 2009 and now fully part of Smart Eye (acquisition completed 2021, ~$73.5M). Affdex is the most-deployed facial emotion SDK in the world, and its training set, 15M+ faces and 8B+ facial frames from 90 countries — is the biggest reason to consider it: emotion models fail cross-culturally when trained only on Western faces, and Affectiva has the broadest coverage to push back on that.
Pricing (2026): commercial SDK licensing typically starts around ~$5,000/year for a single platform and scales with usage; automotive and enterprise tiers are custom and land in the tens of thousands. It runs on-device with sub-100 ms inference, which is what makes it privacy-friendly and low-latency at once.
Reach for Affdex when: you need on-device face analysis, multi-platform SDKs, and cross-cultural accuracy. Where it breaks: it’s face-only, so pair it with a voice model for anything conversational.
3. MorphCast — browser-native, fully on-device
MorphCast does one thing that nobody else does as cleanly: it runs entirely in the browser. The SDK is under 1 MB of HTML5 and JavaScript, and every frame is processed client-side, no video ever leaves the device. For a GDPR-sensitive product that’s a compliance story you can put in front of a DPO without flinching. It tracks 100+ affective signals: expressions, attention, engagement, and mood quadrants.
Pricing (2026): free to start, with paid tiers that scale by usage and features. Because inference is on the client, there’s no per-minute cloud bill: your marginal cost per session is effectively zero.
Reach for MorphCast when: you have a web product, a hard privacy requirement, and you want facial engagement without standing up any infrastructure. Where it breaks: it’s face-and-browser only, no native mobile SDK, no voice.
4. iMotions — research-grade biometric platform
iMotions isn’t an SDK you embed — it’s a research platform. It fuses facial coding, eye tracking (Tobii, Smart Eye), galvanic skin response, ECG, EEG, and survey data onto one timeline. University labs, UX agencies, and automotive HMI teams live inside it because it’s the tool that lets you say “the user frowned, their heart rate spiked, and their eyes fixed on the lower-right corner” in one synchronized view.
Pricing (2026): academic tiers from ~$7,500/year; commercial from ~$25,000/year per seat; enterprise is custom. The desktop software is Windows-only, which rules it out of most cross-platform product work.
Reach for iMotions when: you’re running formal studies and need to defend results to a client or an ethics board. Where it breaks: it’s overkill, and the wrong shape: for a shipped product feature.
5. Noldus FaceReader
FaceReader is the reference implementation for academic psychology. It classifies the six Ekman emotions plus contempt, neutral, and valence/arousal, and it’s one of the few tools with validated infant and child models, which makes it the default in pediatric and food-sensory research. When a paper needs a citable emotion measurement, it’s usually FaceReader.
Pricing (2026): desktop licenses run roughly €8,000–12,000/year per seat; FaceReader Online charges per minute for remote panels. Windows-only for the desktop build.
Reach for FaceReader when: you need publication-grade, citable Ekman-category output, especially for child studies. Where it breaks: it’s a lab instrument, not a product component.
6. Realeyes — video-ad emotion measurement
Realeyes measures how audiences respond to video content at scale. It runs a large opt-in respondent panel and returns attention and emotion metrics on an ad, scene by scene, within a day or two. Big consumer brands and agencies use it to decide which cut of a spot to run. It’s a managed insights service, not a developer SDK — you buy answers, not pixels.
Pricing (2026): managed studies run roughly $5K–50K each; API access for ad-tech platforms is a custom quote.
Reach for Realeyes when: you test video creative and care about brand lift and second-by-second attention. Where it breaks: you can’t embed it in your own product.
7. Kairos — identity-first, emotion as a bonus
Kairos is primarily a face recognition and verification vendor that bundles emotion detection into its SDK. It fits best when identity is the main job, access control, KYC, attendance, and you also want to flag unusual distress. Simple REST API, Python and Node SDKs, on-prem licensing available. Output is the seven Ekman emotions plus a confidence score.
Pricing (2026): a free tier (a few thousand API calls a month), paid plans from ~$19/month, and custom enterprise/on-prem deals.
Reach for Kairos when: face verification is the core feature and emotion is a secondary signal. Where it breaks: it’s not deep enough to be your primary emotion engine.
Stuck between Hume, Affdex, and building your own?
Our ML team has shipped every option on this list. We’ll map your requirements to the shortest path that actually holds up in production.
8. Open-source stack — MediaPipe + DeepFace + OpenSMILE
By 2026 the open-source emotion stack is a real production option. MediaPipe (Google) extracts facial landmarks at 30+ FPS on a phone. DeepFace gives you a pretrained 7-emotion classifier in a few lines of Python. OpenSMILE (audEERING) pulls the acoustic features that drive voice arousal and valence. Fine-tune on AffectNet (~1M labeled faces) or FER-2013 and you’ll land within a few points of the commercial leaders on most tasks, and you own the whole pipeline.
Cost (2026): the software is free. The real cost is engineering — a senior ML engineer for roughly 6–10 weeks to productionize, plus inference at about $0.08–0.20 per hour on a cloud GPU, or effectively free on an NVIDIA Jetson Orin Nano (a ~$249 dev kit) at the edge. For how we approach this class of on-device model, see our custom AI video surveillance guide.
Reach for open-source when: you have ML talent, you’re scaling past ~50K sessions/month, or a regulator won’t let faces leave the device. Where it breaks: year-one engineering and ongoing ops are real: this is a build, not a purchase.
2026 emotion recognition software comparison
One table, the columns that decide procurement: what it senses, how fast, what it costs to start, and who it’s for.
| Tool | Modalities | Latency | 2026 start cost | Best for |
|---|---|---|---|---|
| Hume (EVI) | Face + voice + prosody | 300–500 ms | Usage-based (EVI) | Voice agents, therapy-adjacent |
| Affectiva (Smart Eye) | Face, on-device | <100 ms on device | ~$5K/yr + usage | Automotive, media, cross-cultural |
| MorphCast | Face, in-browser | Real-time, client-side | Free tier + usage | Web apps, privacy-first |
| iMotions | Multimodal biometric | Real-time + offline | ~$7.5K/yr academic | Formal research, UX studies |
| Noldus FaceReader | Face (Ekman + infant) | Real-time | €8–12K/yr | Academic psychology |
| Realeyes | Face + attention | Batch (hours) | $5K+ per study | Video-ad testing |
| Kairos | Face ID + emotion | 200–400 ms | $19/mo entry | Identity-first apps |
| Open-source stack | Face + voice + custom | 30–150 ms on device | Free (infra + build) | Scale, on-device, privacy |
A decision framework in five questions
Answer these in order and the field narrows fast.
1. Is this a product feature or a research study? Studies go to iMotions or Noldus. Product features go to Hume, Affdex, MorphCast, or your own stack.
2. Do users talk, or are they silent? If they talk, voice buys you the most accuracy, Hume EVI. If they’re silent (attention monitoring), it’s a face job — Affdex or MorphCast.
3. Can faces leave the device? If not, healthcare, minors, strict GDPR: you’re on-device only: MorphCast in the browser, Affdex on native, or your own edge model.
4. What’s your monthly volume? Under ~40K sessions, a paid SDK or usage-based API is cheapest. Past that, a fine-tuned open model on your own hardware wins.
5. Where are your users? If any are EU employees or students, emotion recognition is likely prohibited for that use, redesign the feature before you pick a vendor. When two answers pull in different directions, the honest move is usually a hybrid — and that’s where a second opinion pays off.
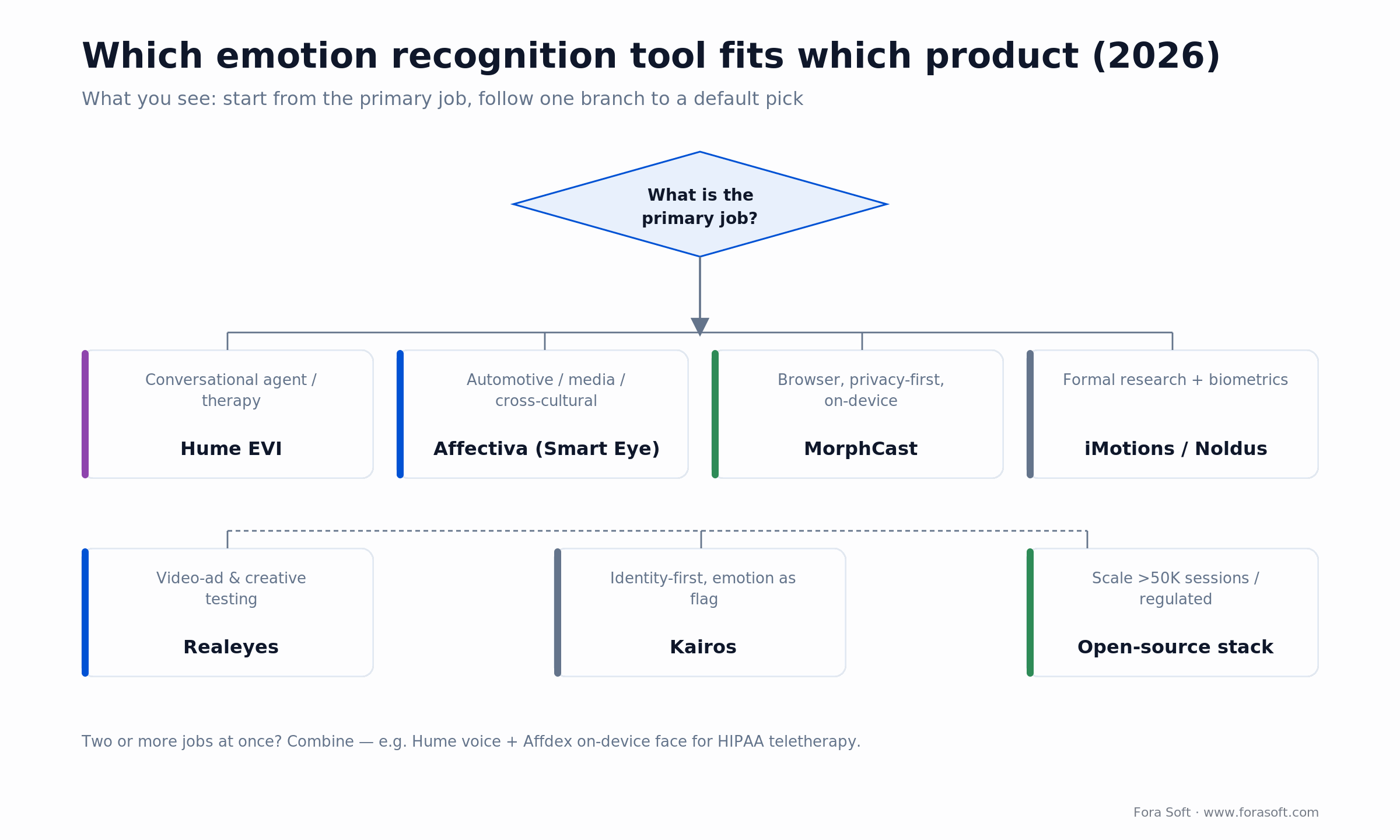
Figure 3. Start from the primary job and follow one branch to a default pick. Two jobs at once means a hybrid.
Build vs buy — the 2026 unit economics
Here’s the arithmetic we walk clients through. Take a concrete case: 100,000 sessions a month, three minutes each, US-based, no HIPAA. That’s 300,000 minutes of analysis per month.
Cloud per-minute: at the old Hume video+audio rate of $0.0828/min, that’s 300,000 × $0.0828 = $24,840/month. And that endpoint is now closed to new work, which is exactly why teams at this scale stopped treating cloud emotion tagging as the default.
On-device (MorphCast or Affdex): a flat license amortizes to roughly $1,200–1,500/month, with zero per-minute inference cost because the work happens on the client.
Open-source self-hosted: figure ~$1,200/month in GPU or edge infra, plus a one-time build of roughly $60–90K. That’s about $7,500/month in year one (build amortized over 12 months) dropping to ~$1,200/month from year two.
The crossover sits around 40–60K sessions/month. Below it, buy. Above it, and especially if privacy pushes you on-device anyway, the build pays for itself inside a year. We use Agent Engineering to compress that build, so our estimates tend to come in below the industry rule of thumb; when we’re not confident in a number, we’d rather scope it with you than publish it.
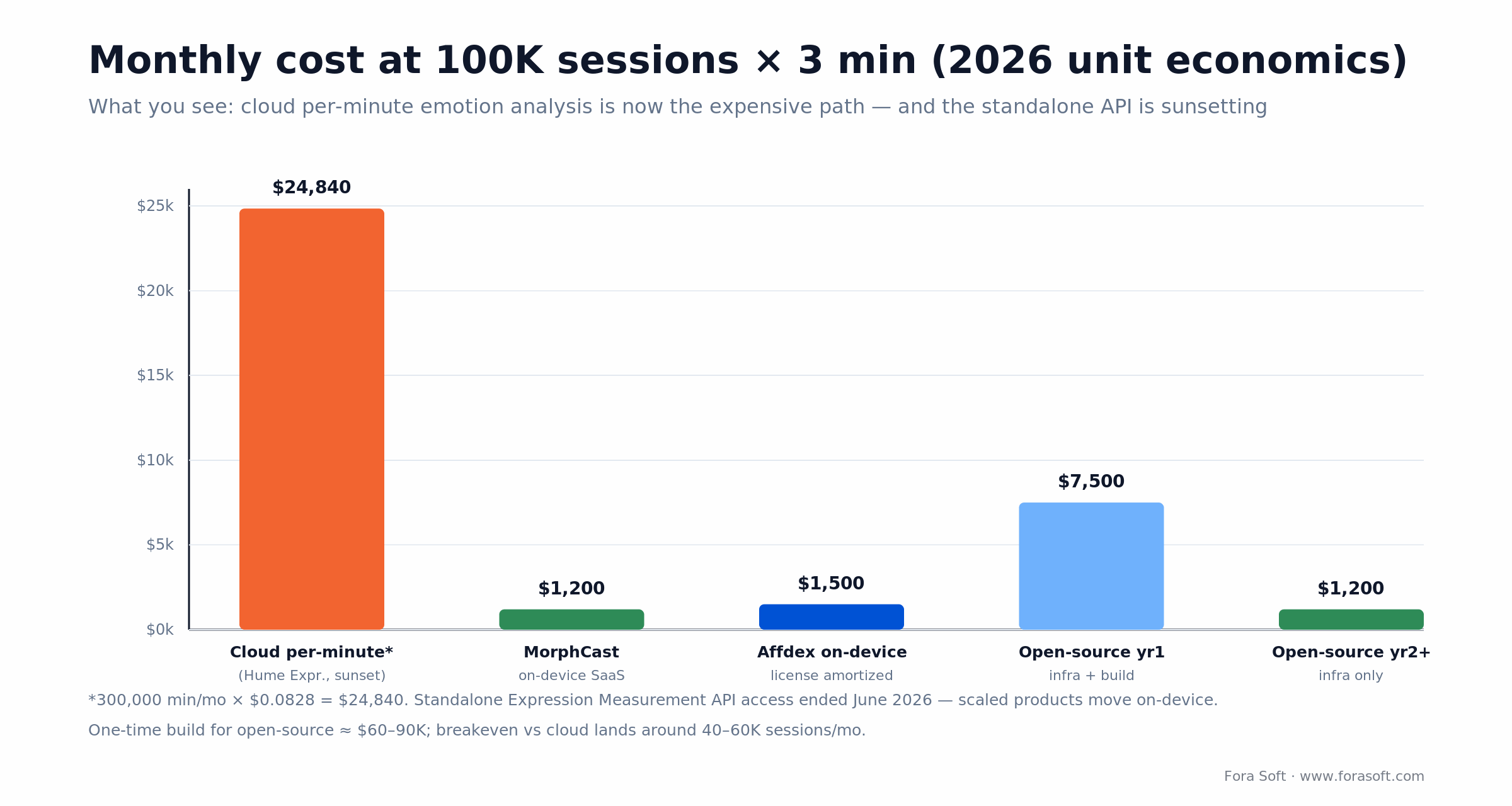
Figure 4. At 100K sessions/month, cloud per-minute is the expensive path; on-device and mature open-source converge near $1,200/month.
Mini case: a teletherapy platform at 40K MAU
Situation. A US teletherapy product wanted to help therapists review sessions and flag concerning affect patterns. The constraints were strict: a signed HIPAA BAA, under 300 ms latency so the therapist could watch a live engagement bar during the call, and an all-in cost under $0.40 per session. Our healthcare work — platforms like CirrusMED, made the compliance bar familiar.
Plan. The first cut leaned on a cloud face-emotion API for the visual channel. It broke inside a year when that vendor deprecated its emotion labels: the same lesson the whole market just relearned with Hume. So we moved face analysis on-device (HIPAA-friendly, no cloud round-trip), kept voice prosody in the cloud under a signed BAA, and wrote our own engagement-score fusion layer on the client.
Outcome. At 40K monthly active users the stack runs at ~180 ms end-to-end and ~$0.28 per 50-minute session. Therapist satisfaction with the live engagement indicator went from 62% on the old stack to 89%. The lesson we keep proving: the fusion layer, not the vendor logo, was the difference. Want a similar assessment of your stack? Grab 30 minutes.
Privacy, bias, and when NOT to use emotion recognition
Three realities to internalize before you ship. First, the law. The EU AI Act Article 5 prohibits inferring emotions from biometric data in the workplace and in educational institutions, in force since 2 February 2025, with a narrow medical/safety exception and fines up to €35M or 7% of global turnover. “Workplace” is read broadly, so hiring and probation count too.
Second, GDPR treats emotion data tied to a health inference as special-category data under Article 9. Default to on-device processing, pseudonymization, and opt-in consent that isn’t bundled into your terms of service.
Third, cross-cultural bias is still real. Models trained mostly on FER-2013 (largely Western faces) can drop 8–15 points of accuracy on East Asian and Sub-Saharan faces. Measure bias on your own user population before launch, not after a press cycle.
When NOT to use it at all: when your audience is minors and the value is marginal; when you’d have to show users raw emotion scores (they read as creepy); when a single wrong inference could deny someone a job, a grade, or care; and any EU workplace or classroom use outside the safety exception. Honesty about these limits is part of the product, not a footnote.
Building an emotion-aware feature with a compliance surface?
We’ll review your architecture against HIPAA, GDPR, and the EU AI Act, and tell you what to redesign before you build it.
Five production pitfalls we’ve paid for
1. Treating emotion as discrete categories. Users don’t feel “angry at 87% confidence” — they feel a blend. Use valence-arousal where the SDK supports it; treat discrete labels as a UI simplification, not a model truth.
2. Showing raw scores to end users. Never. Build a derived engagement or mood-trend indicator. Raw confidence numbers feel invasive, and when they’re wrong they’re infuriating.
3. Skipping per-user calibration. Some people have a resting frown; others look perpetually cheerful. Without a baseline you’re measuring face shape, not emotion. Capture a short neutral baseline per user.
4. Ignoring audio codec loss. Telephony-grade G.711 strips the prosody that carries 30–40% of your voice-emotion accuracy. Sample at 16 kHz+ with Opus if you control the pipeline.
5. No fallback model. Cloud APIs go down and vendors deprecate features, 2026 was a live demonstration. Keep a second model ready, even a thinner open-source one, so a vendor decision can’t take your feature offline.
FAQ
What is the best emotion recognition software in 2026?
There isn’t one winner: it’s use-case dependent. Hume EVI leads voice-first and conversational products, Affectiva (Smart Eye) leads on-device and cross-cultural face analysis, MorphCast leads privacy-first browser apps, and a fine-tuned open-source stack wins at scale. iMotions and Noldus own research.
Is emotion recognition accurate enough for production?
Yes for aggregate signals like engagement and valence/arousal trends over a session. No for single-frame discrete labels, in-the-wild categorical accuracy is around 65%. Treat it as a directional input, never as ground truth about one moment.
Can I legally use emotion AI in EU schools or workplaces?
Generally no. The EU AI Act has prohibited inferring emotions from biometric data at work and in education since 2 February 2025, except for medical or safety reasons. It carries fines up to €35M or 7% of global turnover, so get legal review and a DPIA first.
Is there good open-source emotion recognition software?
Yes. MediaPipe for landmarks, DeepFace for a pretrained 7-emotion classifier, and OpenSMILE for voice features form a production-capable stack. Fine-tuned on AffectNet, it lands within a few points of commercial tools — the cost is engineering time, not licenses.
How much does real-time emotion recognition cost at scale?
At 100K three-minute sessions a month: cloud per-minute lands near $24,840, on-device SDKs amortize to ~$1,200–1,500, and a self-hosted open-source stack runs ~$7,500 in year one and ~$1,200 after. The build-vs-buy crossover is around 40–60K sessions/month.
Can emotion recognition run on mobile or in the browser?
Yes. Affdex runs on iOS and Android with sub-100 ms inference; MediaPipe plus a TFLite model runs 30+ FPS on mid-tier phones; and MorphCast runs entirely in the browser with no data leaving the device. On-device is the right default for privacy.
What happened to Hume’s Expression Measurement API?
Hume sunset the standalone Expression Measurement API in mid-2026, new jobs ended in May and full access ended in June. Expression scoring now lives inside EVI, its conversational voice product. Cheap high-volume batch emotion tagging is no longer its use case.
Should I build my own emotion model or buy one?
Buy below ~40–60K sessions/month or if you lack in-house ML talent. Build when you’re past that scale, or when privacy and latency rule out cloud. A hybrid: on-device face plus cloud voice, is often the pragmatic middle.
What to read next
ML & Vision
7 Best ML Algorithms for Surveillance Anomaly Detection
The vision models next door to affect detection, compared.
Computer Vision
Build Custom AI Video Surveillance with YOLO & DeepSORT
How we ship on-device CV models in production.
AI & Audio
7 Best AI Tools for Audio Apps in 2026
Voice and prosody tooling that pairs with emotion AI.
Services
AI Development at Fora Soft
How we scope and ship AI features end to end.
So which emotion recognition software should you pick?
Accuracy is a near-commodity, so the decision is fought on latency, privacy, modality fusion, cost at your volume, and regulatory fit. Hume EVI takes conversational and voice-first. Affectiva (Smart Eye) takes on-device face and cross-cultural. MorphCast takes privacy-first browser apps. iMotions and Noldus own research; Realeyes owns ad testing; Kairos fills the identity niche; and the open-source stack is the honest answer past ~50K sessions a month.
The non-obvious call: choose based on where your latency and compliance costs live, not on the accuracy percentage in the deck — and read the roadmap risk, because 2026 proved a vendor can retire your favorite endpoint overnight. If you want a second set of eyes that’s shipped all of this, we’re around.
Let’s map your emotion AI stack together
30 minutes with a product-ML lead at Fora Soft, an architecture conversation, not a pitch.








