



Key takeaways
• Emotion detection in audio and video is a multimodal ML problem, not a single model. The strongest systems fuse face, voice, text, and sometimes physiology — each signal compensates for the others’ blind spots.
• Published accuracy is misleading. Benchmark scores of 90–99% drop to 60–80% in production, and error can climb >70% under real-world lighting, accents, occlusion, or demographic shift.
• The EU AI Act banned most workplace and school emotion recognition on 2 February 2025. If your product touches EU employees or students, scope changes or you shelve the feature — medical and safety exceptions are narrow.
• Buy first, build when the model is a moat. Off-the-shelf APIs (AWS, Google, Azure, Hume, MorphCast, Affectiva) ship in weeks; a custom multimodal stack takes 4–9 months with Agent Engineering and only pays off when data, vertical, or latency requirements are genuinely unusual.
• The ethics work is the delivery risk. Consent, bias audits, demographic accuracy reports, and a clear “do not use for” list are what keep the feature live after launch — not the model architecture.
Why Fora Soft wrote this playbook
Emotion detection in audio and video sits at the intersection of three fields we have shipped for two decades: real-time communications, computer vision, and applied machine learning. We build production video platforms for telehealth, edtech, live-stream, surveillance, and enterprise sales — the exact verticals where “does this user look stressed, disengaged, or in distress?” turns from a research question into a product feature.
Our AI integration practice has explicit Emotion Recognition Dynamics services — we integrate facial affect analysis into live video with Azure Cognitive Services, OpenCV, MediaPipe, YOLO, PyTorch and TensorFlow, and wire the signals into product actions. The sales-intelligence platform Meetric fuses speech and engagement cues during live calls to lift close rates by roughly a quarter. VocalViews, used by Samsung, Google and Netflix research teams, layers AI sentiment analysis over video interviews in 30+ languages for more than 800,000 verified participants. The surveillance platform V.A.L.T runs HD behavioural video across 2,500+ cameras for 50,000 daily users in law enforcement and medical education.
What follows is the playbook we wish we had on day one: how these pipelines actually work, the datasets and APIs that matter, what’s regulated, what goes wrong in production, and the numbers buyers need to make a sane build-vs-buy call. It is biased towards people who will ship this feature, not publish a paper on it.
What emotion detection in audio and video actually is
“Emotion detection” is an umbrella term for systems that infer affective state — happiness, sadness, anger, fear, surprise, disgust, contempt, plus dimensional scores like valence and arousal — from face video, speech audio, text transcripts, or physiological signals. In the literature it is also called affective computing, affect recognition, or multimodal emotion recognition (MER).
The commercial version of the problem is narrower. Teams usually ship one of four things: facial expression classification on a video stream, speech emotion recognition (SER) on a microphone feed, sentiment analysis on the transcribed text, or a fused multimodal classifier that combines two or three of these. The research field adds biosignal inputs (EEG, heart rate, galvanic skin response), but these rarely leave the lab and the EU AI Act now restricts their workplace use specifically.
A useful mental model: the pipeline takes an audiovisual clip, extracts features specific to each modality, runs one model per modality, and then either majority-votes the outputs (late fusion) or jointly learns across them (early or hybrid fusion). The output is a probability distribution over a set of emotion labels, plus confidence. What you do with that distribution — alert a clinician, coach a sales rep, route a support call, throttle a content recommendation — is where the product lives.
Scoping an emotion-aware feature and not sure where to start?
30 minutes with our AI lead will tell you whether your use case is a fit, which modalities to ship first, and a realistic Agent-Engineering-accelerated timeline.
Where emotion detection actually pays off in 2026
The affective-computing market is projected to grow from about $76B in 2025 to roughly $192B in 2030 at a 20% CAGR, with contact-center and customer-experience tooling taking more than half of the narrower emotion-AI slice. The honest truth: not every vertical needs this, but five do, and those are where we see real deals close.
1. Telehealth and behavioural health. Multimodal emotion signals — vocal prosody, facial micro-expressions, linguistic markers in the transcript — are being used to flag depression risk, anxiety, and PTSD severity during virtual consultations, and to help clinicians pace sessions. Usage is growing fastest in platforms that already handle video visits (see our telehealth software guide for the adjacent architecture).
2. Driver and cabin monitoring. Regulators are forcing the issue. Smart Eye’s 2021 acquisition of Affectiva for $73.5M was driven by automotive interior sensing requirements; in-cabin cameras now infer driver state, cognitive load and road rage as part of safety stacks.
3. Contact centres. Real-time speech-emotion coaching — Cogito, Observe.AI, Uniphore — has become a standard tool for enterprise support. Single-modality SER reaches 80–90% accuracy on well-matched training data, which is enough to nudge agent behaviour.
4. Enterprise sales intelligence. Platforms like Gong, Chorus, and our own Meetric use engagement and prosody cues to coach reps, score calls, and auto-fill CRM — Meetric reports 25% higher close rates and 80–100% CRM automation for users who adopt it.
5. Market research, media testing, and UX. Sentiment analysis over video interviews at scale, ad-testing panels, and gameplay reaction studies are where browser-based face analysis SDKs (MorphCast, Realeyes) thrive — they do not need server calls and sidestep a lot of biometric-data arguments. VocalViews uses exactly this pattern across 185,000+ business users.
How a modern emotion detection pipeline works
Every production system we have built or audited shares the same five-stage shape: capture, preprocess, extract features, classify, and act. Figure 1 shows the canonical pipeline.
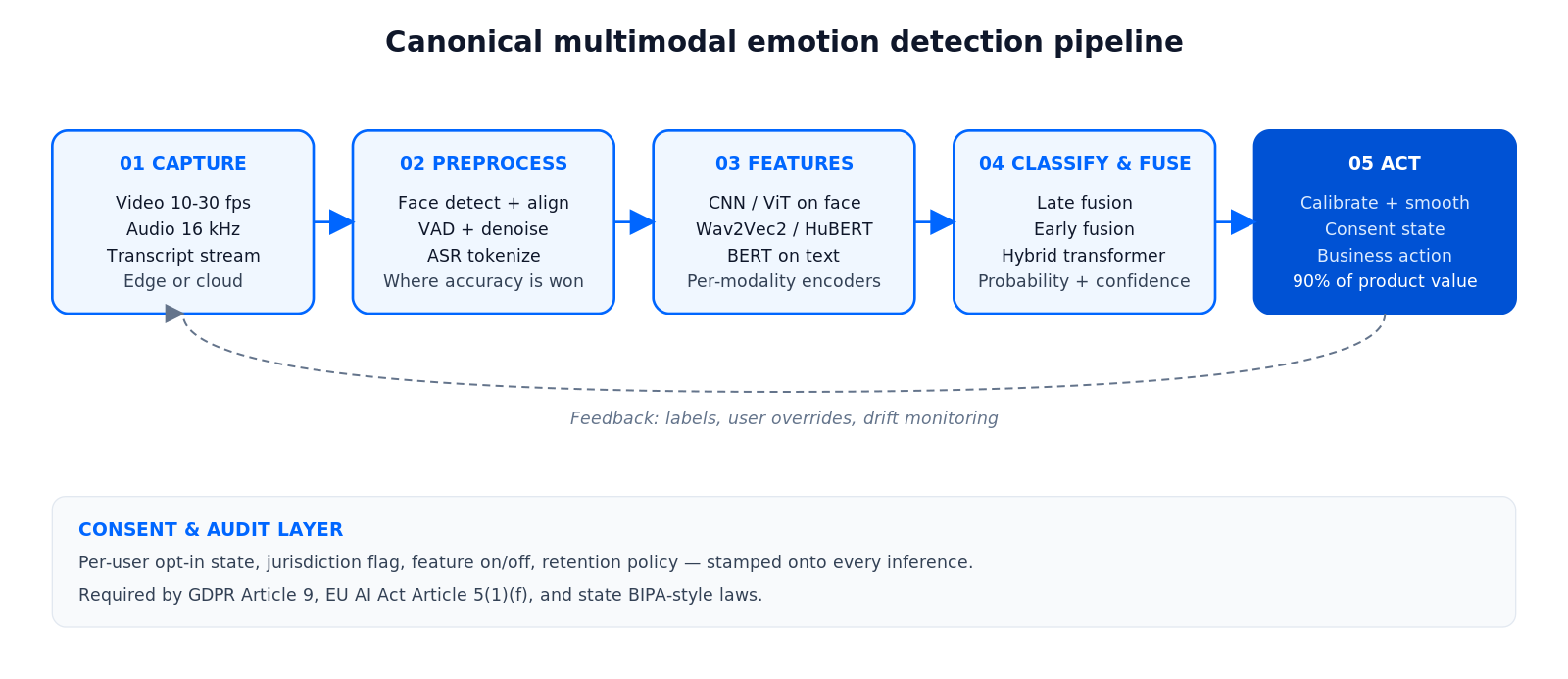
Figure 1. Canonical multimodal emotion detection pipeline, as deployed in production.
Stage 1. Capture
Video at 10–30 fps is plenty — facial expressions are slow relative to frame rate. Audio is usually 16 kHz mono PCM, buffered in 20–100 ms frames for streaming SER. For low-latency contact-center or driver-monitoring use, on-device capture is preferable because shipping raw biometrics to a cloud endpoint raises GDPR and AI Act exposure.
Stage 2. Preprocess
For face: detect (MTCNN, RetinaFace, YOLOv8-face), align to canonical pose, normalise lighting. For audio: voice-activity detection, silence trimming, noise suppression, mel-spectrogram or MFCC feature maps. For text: transcribe with a production ASR (Whisper, Deepgram, AssemblyAI), then tokenize. This stage is where real-world accuracy is won or lost — a weak face detector under poor lighting cascades into meaningless classifier output.
Stage 3. Feature extraction
Modern systems are mostly end-to-end: a CNN or Vision Transformer over aligned face crops; a Wav2Vec2, HuBERT, or Whisper encoder over raw audio; a BERT-style encoder over the transcript. Hand-engineered features (Action Units for face, prosody for voice) still matter for explainability and for the low-latency edge deployments where a ViT is too heavy.
Stage 4. Classification and fusion
Each modality either produces its own label distribution (late fusion, then combine with weighted averaging or a small gating network) or the modal features are concatenated and passed through a joint transformer (early or hybrid fusion). The choice is not religious — see §Multimodal fusion below.
Stage 5. Act
This is where 90% of product value lives and 90% of engineering teams under-invest. A label is not a feature. The label needs calibration, temporal smoothing (rolling window of 3–10 seconds), a suppression logic to avoid alert fatigue, and a per-user consent state. Without that layer you will ship a demo, not a product.
The four modalities, compared
Each input signal has its own strengths, costs, and failure modes. The table below summarises the trade-offs we see in shipping systems.
| Modality | What it captures | Typical benchmark | Production reality | Best for |
|---|---|---|---|---|
| Facial (FER) | Micro- and macro-expressions, gaze, head pose | 82–99% on AffectNet, CK+, RAF-DB | 60–80% in the wild, >70% error under occlusion/lighting shift | Video calls, market research, driver monitoring |
| Speech (SER) | Prosody, pitch, energy, speech rate, voice quality | 84–97% on RAVDESS, EmoDB, IEMOCAP | 65–80%, accent- and language-sensitive | Call centres, IVR, audio-only telehealth |
| Text sentiment | Semantic content, valence, topic, intent | 85–93% on SST-2, MELD text | Most stable cross-context, but misses sarcasm | Chat, support tickets, interview coding |
| Physiological | Heart rate, GSR, EEG, respiration | 70–85% on DEAP, K-EmoCon | Requires wearable; regulated under AI Act | Clinical research, driver fatigue, VR UX labs |
| Multimodal fusion | Any combination of the above | +3–8 pts over best single modality | Most robust to real-world noise | Telehealth, high-stakes decisions |
Reach for face-only when: you already have a video stream, you need <200ms latency, and consent is explicit (for example, a telehealth provider on a paid visit).
Reach for speech-only when: you are in a call centre, your customers will not turn on a camera, or the phone line is the product.
Reach for multimodal when: the cost of a false positive is high (clinical flagging, coaching, safety) and the environment is uncontrolled.
Multimodal fusion strategies, without the jargon
Early fusion concatenates raw or mid-level features from each modality and trains one big classifier. Pros: the model learns cross-modal interactions end-to-end, usually the strongest numbers on benchmarks. Cons: any missing modality poisons inference; training is fragile; latency is dominated by the slowest branch.
Late fusion trains one classifier per modality and combines their outputs (weighted average, voting, or a small MLP gate). Pros: degrades gracefully when one modality is missing; easy to A/B test a new modality; the only realistic option for edge-plus-cloud hybrids. Cons: leaves accuracy on the table in clean lab conditions.
Hybrid (transformer) fusion uses cross-attention between modality encoders — the text decoder attends to audio tokens, audio attends to face tokens, and so on. This is the 2025–2026 SOTA for datasets like CMU-MOSEI and MELD. Accuracy lifts of 3–8 points over single modality are typical; the engineering and inference cost is steep.
Reach for late fusion first. Ship a per-modality classifier per modality, combine at the API layer, and only move to hybrid if an A/B test shows you are leaving real money on the table.
Benchmark vs. real-world accuracy — the uncomfortable gap
Vendors pitch accuracy in the 90s. The literature agrees — on curated benchmarks. Recent peer-reviewed FER models hit 99.26% on CK+ and 82% on RAF-DB; SER ensembles exceed 95% on RAVDESS and 96% on IEMOCAP. That is the upper bound.
Published in-the-wild evaluations show error increases of >70% under corruption, occlusion, lighting shift, or distribution shift. On genuinely unseen users and environments, production accuracy lands in the 60–80% range for facial and speech systems; complex or social emotions (embarrassment, contempt, sarcasm) drop well below 75% regardless of model size.
What this means for product decisions: never promise categorical emotion labels. Ship probabilities with calibrated confidence, expose thresholds as tunable parameters, and treat emotion output as one signal among many. We build customer dashboards that combine emotion confidence with session length, turn-taking, and topic — the blended score is what drives decisions.
Benchmarked model giving you 90%, real world giving you 65%?
Our team has rescued several stalled emotion-AI rollouts with dataset audits, re-labelling, and hybrid-fusion retraining. Let us help yours.
Datasets you should know before training anything
If you are building, the dataset is the feature. If you are buying, the dataset is the bias you inherit. Every API vendor is trained on some subset of these corpora, and their failure modes reflect that.
Facial
AffectNet — over a million unposed internet images, labelled for 8 discrete emotions plus valence and arousal. The industry workhorse; also Western-skewed. FER-2013, 35k images, noisy labels, still the canonical baseline. CK+ and JAFFE are lab-posed and inflate numbers. RAF-DB is real-world. AFEW pulls expressions from films. Aff-Wild2 is the strongest in-the-wild corpus for continuous valence/arousal.
Speech
IEMOCAP — 12 hours, 10 speakers, scripted and improvised, the benchmark for SER. RAVDESS — acted, balanced by gender, widely used. EmoDB (German), CREMA-D (ethnically balanced), MELD (conversational TV). All English-or-German heavy.
Multimodal
CMU-MOSEI and MELD bundle face, audio and transcript and are the go-to for fusion research. DEAP and K-EmoCon add physiological channels.
Build vs. buy — a decision matrix
Teams almost always underestimate the operational cost of owning a model and overestimate the switching cost of starting with an API. Here is the rough shape we talk buyers through.
| Criterion | Buy (API/SDK) | Build (custom) |
|---|---|---|
| Time to first pilot | 2–4 weeks | 3–6 months with Agent Engineering |
| Up-front cost | Low (integration + UX) | Moderate (data, labelling, infra) |
| Accuracy ceiling | Whatever the vendor ships | Higher on your specific population |
| Bias control | Black box, rarely auditable | You own the audit |
| Data residency | Vendor region / on-device SDK | Anywhere you can host |
| Ongoing run-rate | Per-call pricing, usually scales with growth | GPU infra + MLOps + retraining cycles |
| When it wins | Speed, non-core feature, standard vertical | Moat, unusual population, latency/edge, regulation |
Reach for a hybrid build when: an off-the-shelf model gets you to 80% on your population, and an internal fine-tune of the last head plus your own fusion logic closes the gap — this is typically the sweet spot.
The API and SDK landscape
The market has consolidated around a handful of general-purpose cloud APIs, research-led voice/face specialists, browser SDKs for on-device use, and vertical players (automotive, contact-centre). The table below is the current state for buyer scoping — pricing is indicative and changes quarterly, so always confirm with the vendor.
| Vendor | Modality | Deployment | Indicative pricing | Good for |
|---|---|---|---|---|
| AWS Rekognition | Face sentiments | Cloud | ~$0.001/image, $0.10/min video | Quick face pilots inside AWS estates |
| Google Video Intelligence | Face, shot detection | Cloud | Per-minute, volume-tiered | Bulk video annotation, GCP users |
| Azure Face + Video Indexer | Face + speech + sentiment | Cloud | Per-call / per-minute | Enterprise Azure shops; note general-emotion API retirement |
| Hume AI | Voice + face prosody | Cloud, WebSocket streaming | Per-minute, with research tier | Research-grade multimodal, expressive voice UIs |
| Affectiva / Smart Eye | Face, in-cabin | Embedded / OEM | Licensed, custom | Automotive, driver monitoring |
| MorphCast | Face | Browser JS SDK, on-device | Subscription, <1MB SDK | Market research, e-learning, privacy-first deployments |
| Realeyes | Face + attention | Cloud / SDK | Enterprise licensing | Ad testing, media panels |
| Noldus FaceReader | Face, Action Units | Desktop | Annual licence | Academic/behavioural research |
| Symbl.ai / Deepgram / AssemblyAI | Speech sentiment, transcript | Cloud, streaming | Per-minute ASR + sentiment add-on | Meetings, calls, sales intelligence stacks |
Regulation: the EU AI Act changed the market in February 2025
The biggest regulatory shift for emotion detection landed quietly on 2 February 2025: Article 5(1)(f) of the EU AI Act prohibits placing on the market, putting into service, or using AI systems to infer emotions from biometric data (face, voice, gait, physiological signals) in workplaces and educational institutions. Medical and safety exceptions are narrow. Enforcement guidelines were published on 4 February 2025.
A few things that trip up product teams: the ban applies regardless of vendor HQ if the system is offered to people in the EU. It covers voice as well as face. Advertising, customer analytics, and non-workplace consumer use are not banned under Article 5, though they are still subject to GDPR and high-risk classification rules elsewhere in the Act.
Outside the EU: GDPR still treats biometric inference as a special category of data under Article 9, which means explicit opt-in consent or a clear legal basis. In the US, Illinois BIPA-style biometric laws create real litigation risk (Clearview, Facebook have paid nine-figure settlements), and several states followed. UK and Canada broadly align with GDPR. China regulates face recognition specifically; India’s DPDP Act requires consent and purpose limitation.
Practical rule: if your product is B2B sold to EU employers or schools, do not ship emotion inference on staff or students. Period. Consider engagement or attention metrics (task-based, not affective) as an alternative.
Bias, fairness, and what the science actually says
The most important paper in the field is Barrett, Adolphs, Marsella, Martinez, and Pollak’s 2019 review in Psychological Science in the Public Interest. Their conclusion: the leap from facial movement to emotion category is weaker than the field assumed. People smile when they are not happy; facial configurations vary by culture, context, and individual; “universal basic emotions” are a contested model, not settled science.
Translated into product risk: off-the-shelf emotion APIs trained on Western, younger, male-biased datasets mislabel Black women, East Asian speakers, older users, and anyone whose expressive idiom differs from the training distribution — measurably and reproducibly. Documented audits show 5–20 point accuracy gaps between demographic groups on the same benchmark. Ask vendors for demographic accuracy reports; most will not hand them over.
Mitigations that actually work: balanced training data (CREMA-D, CAER-S for face, subset of MELD for text), a post-hoc calibration layer per demographic segment, a “do not infer” list of contexts (hiring, performance management, behavioural medicine without clinician review), and continuous monitoring for drift. None of these are free. All of them are cheaper than a class action.
Reference architecture for a production multimodal system
Figure 2 shows the architecture we use as a starting point for multimodal emotion-aware products. It deliberately pushes lightweight face inference to the edge and cloud-bursts heavier speech and text models — the right trade-off for telehealth, contact-centre, and sales-intelligence workloads.

Figure 2. Reference production architecture for multimodal emotion detection.
The non-obvious pieces: a consent and audit layer stamped onto every inference (user opt-in state, jurisdiction, feature flag), a feature store with 30-day TTL so retraining does not require a fresh data haul, and a feedback channel that lets operators flag false positives — without that loop, models degrade silently for months.
Mini case: what we learned shipping real-time emotion signals in sales video
Situation. A Nordic B2B sales-intelligence platform wanted live engagement signals during Zoom, Teams and Google Meet calls — not labelled emotions, but tractable behavioural cues (attention, agreement, confusion) that could be fed back to the rep in-call.
12-week plan. Week 1–2: consent flow, cross-platform capture bridge. Week 3–6: speech prosody pipeline with Whisper + a lightweight SER head, plus face engagement (gaze, smile, brow) via an on-device WASM model. Week 7–9: late-fusion engagement score, threshold tuning on real customer calls. Week 10–12: in-call rep coaching UX, post-call summary, CRM push.
Outcome. 25% lift in close rate vs. matched pre-launch baseline; 80–100% of CRM fields auto-filled from call metadata and emotion-adjacent signals; qualitative feedback that reps trusted the engagement score more once we stopped labelling it “happy / sad” and started labelling it “attentive” and “objecting”. The product is live as Meetric. If you want a similar assessment for your stack, book 30 minutes.
Cost model — what a realistic engagement looks like
Numbers below assume our Agent-Engineering-accelerated delivery — our AI builds run faster and leaner than a classical outsourcing model. They are ranges, not quotes; real figures depend on your stack, data access, and compliance scope.
| Scope | Typical duration | Indicative build cost | Ongoing run-rate |
|---|---|---|---|
| API integration (face or speech) | 3–6 weeks | $20k–$60k | Vendor API fees, scales with volume |
| Multimodal MVP on your video stack | 8–14 weeks | $60k–$160k | Mixed API fees + modest GPU infra |
| Custom fine-tuned fusion model | 4–8 months | $150k–$450k | GPU cluster, MLOps, labelling retainer |
| Regulated clinical deployment (SaMD-adjacent) | 6–12 months | $300k–$900k | Audit, revalidation, clinical ops |
Our experience: most buyers get the best ROI from the first two rows, then layer a fine-tune on top only once they have real production data and a specific failure mode to close.
A decision framework — pick a path in five questions
1. Who is the subject? Customers, patients, students, employees, drivers, or the general public? If “employees or students” in the EU, stop and rescope — Article 5 applies.
2. What decision does the signal drive? A nudge to the user, a decision about the user, or something in between? Decisions about someone (hiring, credit, clinical triage) raise the regulatory and ethical bar sharply; nudges and coaching are much lower risk.
3. What modality do you already have? If you own the video stream (telehealth, sales call), face plus voice is cheap; if you only own a phone number, SER-only is probably the right scope.
4. How unusual is your population? Children, elderly, masked faces, non-native speakers, accented speech? The more unusual, the more you need your own data pipeline and the less you can trust an off-the-shelf accuracy claim.
5. What is your tolerance for a false positive? Every emotion system has them. If a false “distressed” flag to a clinician is tolerable, proceed; if the same flag triggers an automated action with consequences, do not ship without a human in the loop.
Pitfalls we keep seeing
1. Shipping categorical labels. “User is angry” is a worse UX than “call tone rising, rep should slow down.” Ship calibrated confidence and behavioural signals, not discrete emotion categories.
2. Skipping the consent layer. GDPR Article 9 and the AI Act both require per-user opt-in for biometric inference — and users revoke consent. If your system cannot turn a single user’s inference off without a release, you have a compliance problem.
3. Treating the demographic gap as a rounding error. A 15-point accuracy drop on one ethnic group is not noise, it is a lawsuit. Audit quarterly; rebalance training data; publish internal accuracy cards.
4. Ignoring temporal context. Single-frame or single-utterance classification is unstable. Smooth over a 3–10 second window, weight recent frames higher, require persistence for the signal to actionably fire.
5. Under-instrumenting. Emotion AI drifts. If you do not log predictions, ground truth (when you can collect it), and user feedback, you will not notice until a regulator or a user does.
KPIs: what to measure
Quality KPIs. Per-class precision and recall on a held-out production set (target ≥ 0.75 F1 for your primary class). Demographic parity — absolute accuracy gap ≤ 5 points across race, gender, and age bands. Calibration error (ECE) ≤ 0.05.
Business KPIs. Feature attach rate, action rate per inference (does anyone actually use the coaching nudge?), conversion lift or outcome improvement in a controlled rollout, opt-in rate (a healthy consent flow lands 40–70%).
Reliability KPIs. P95 inference latency (target <250 ms for real-time UX), model drift alarms (weekly distribution checks), incident rate of false-positive escalations, and time to rollback a model version.
When NOT to use emotion detection
Skip the feature if any of the following apply. (a) Your use case is employees or students in the EU and you cannot fit a medical or safety carve-out. (b) The signal would drive a decision about a person without a human in the loop. (c) You have no path to collect demographically balanced evaluation data — you will ship biased inference and not know it. (d) The product already works; emotion signal is being bolted on because it is fashionable. Stand down.
In most of these cases, the better move is a behavioural metric — talk time ratios, silence detection, response latency, keyword extraction — which is cheaper, more stable, and much less regulated.
Ready to scope emotion or engagement signals for your product?
We will audit your video/audio stack, map the right modality, size the build with Agent Engineering, and come back with a one-pager you can take to your board.
FAQ
How accurate is emotion detection in audio and video in practice?
On curated benchmarks, modern facial models reach 82–99% and speech models 84–97%. In production, expect 60–80% for either modality alone, and watch for accuracy cliffs of >70% under lighting, occlusion, accent, or demographic shift. Multimodal fusion typically adds 3–8 points over the strongest single modality.
Is emotion detection legal in the EU?
Since 2 February 2025, AI systems that infer emotions from biometric data in workplaces and educational institutions are prohibited under Article 5(1)(f) of the EU AI Act. Medical and safety carve-outs are narrow. Customer-facing and consumer contexts are not banned under Article 5 but remain subject to GDPR and wider AI Act obligations.
Should we build our own model or use an API?
Start with an API or SDK. Build or fine-tune only when off-the-shelf performance on your population is clearly insufficient, you have differentiated training data, or data residency and latency rule out third-party endpoints. Most deployments we see start as an API integration and move to a hybrid (fine-tuned head + custom fusion) only after a real baseline is measured.
What does it cost to add emotion detection to a video product?
An API integration for a single modality typically runs $20k–$60k and 3–6 weeks. A multimodal MVP on an existing video stack is usually $60k–$160k over 8–14 weeks. A custom fine-tuned multimodal fusion model runs $150k–$450k over 4–8 months. Ranges assume our Agent-Engineering-accelerated delivery.
Which datasets should we train on?
For face: AffectNet and RAF-DB as workhorses, Aff-Wild2 for continuous valence/arousal in the wild, CREMA-D for demographically more balanced audio-visual. For speech: IEMOCAP and RAVDESS for benchmarking, MELD for conversational. For multimodal fusion: CMU-MOSEI and MELD. Mix with your own labelled production data; none of the public sets are globally representative.
How do we handle bias and fairness?
Request demographic accuracy breakdowns from vendors; insist on balanced training or a post-hoc per-segment calibration; audit quarterly on real production data; cap the absolute accuracy gap across race, gender, and age at 5 points; publish internal accuracy cards. Expect to re-label and re-train at least once a year.
Can emotion detection run on-device for privacy?
Yes, increasingly so. Browser SDKs like MorphCast run face analysis entirely in the browser (WASM/WebGL) with a sub-1MB model, avoiding any biometric data leaving the client. Mobile frameworks (Core ML, TensorFlow Lite, ONNX) let you ship a quantised face or speech model on-device. Accuracy is 5–10 points below cloud models but the privacy and latency wins usually justify it.
How long does a real deployment take?
An API pilot in 2–4 weeks; a production-grade multimodal feature with consent, monitoring, and calibration in 10–16 weeks; a regulated clinical or safety deployment in 6–12 months including audits and revalidation. Agent Engineering compresses each of these by a meaningful margin compared with classical outsourced delivery.
What to Read Next
Real-time emotion AI
Real-Time AI Emotion Software
Deeper dive into live affective signals in video calls and contact centres.
Speech emotion
Audio Emotion Detection System Using AI
How SER pipelines are built end to end, with feature choices explained.
Facial emotion
Machine Learning for Video Emotion Analysis
Focused read on the facial side of the pipeline: models, datasets, deployment.
Video conferencing
AI Emotion Detection in Video Conferences
Product patterns for integrating affective signals into Zoom, Teams and Meet.
Services
Fora Soft AI Integration Services
Our stack, case work, and a one-click path to scoping an AI build with us.
Ready to ship emotion detection that holds up in production?
The short answer to “should we add emotion detection in audio and video?” is: only if the signal drives a decision that is cheaper, safer, or better with it, and only after you have decided which modality, which vendor or model, and which compliance regime apply. The failure modes are predictable — benchmark over-claiming, demographic bias, consent gaps, dead labels instead of live signals — and every one of them is fixable by engineering, not evasion.
Fora Soft has shipped emotion-adjacent AI into sales video, video market research, telehealth-adjacent platforms and surveillance-grade behavioural video. We know where the cliffs are, we know what Agent Engineering buys you on timeline, and we will tell you when the answer is “do not build this.” If that is the conversation you need, we are one call away.
Get a second opinion on emotion detection in audio and video
30 minutes with our AI lead, a clear scope and cost range, and honest advice on whether to build, buy, or shelve the feature.








