



Key takeaways
- Voice is no longer a novelty feature. Over 27% of all mobile searches now use voice, and the voice-commerce market has jumped from $42.8 B in 2023 toward a projected $186 B by 2030.
- The 2026 mobile voice stack is finally cheap and fast: on-device Apple SpeechAnalyzer and Gemini Nano handle private, offline recognition; Deepgram Nova-3 and OpenAI Realtime API deliver sub-300 ms cloud turnaround.
- App-store approval and privacy rules are the real bottleneck. Microphone permissions, App Privacy labels, Data Safety declarations, and NSSpeechRecognitionUsageDescription get voice apps rejected more often than broken features do.
- Hybrid architectures win. On-device for private, latency-sensitive paths; cloud for multilingual, accuracy-critical paths. Pick per-feature, not per-app.
- Fora Soft ships production voice features into iOS and Android apps in 8–12 weeks with a repeatable architecture: hybrid on-device + cloud ASR, LLM intent with function calling, streaming TTS, privacy-compliant logging, and App Store / Play review sign-off built into the process.
More on this topic: read our complete guide — 3 Key Strategies for Noisy Speech Recognition (2026).
Voice recognition app development crossed from novelty to baseline in 2026. If you run product or engineering at a mobile-first company — healthcare, fintech, retail, fitness, accessibility, automotive — you already know voice is moving from “nice to have” to expected. Your competitors are shipping voice search, voice commerce, voice dictation, and voice-first onboarding. The user expectation has quietly shifted: if I can say it, the app should understand it.
This guide is the playbook we use at Fora Soft for voice recognition app development — whether a customer wants to add voice to an existing iOS or Android app or build a voice-first one from scratch. It covers the stack, the SDKs, the privacy rules, the latency budget, and the 8–12-week integration path, with numbers and references — not slogans. If you’d rather skip to a scoping call, book 30 minutes with our team.
Why Fora Soft wrote this playbook
Fora Soft has been building real-time audio, video, and AI features into mobile apps since 2005 — 250+ shipped products across 21 years. Three reasons we felt obliged to write this one.
First, voice is a cousin of every modality we already ship. Our AI voice recognition for intercoms practice has put ASR, voice biometrics, and LLM intent into production on thousands of doors. Our simultaneous interpretation architecture handles live multilingual audio at scale. Our AI streaming platform work covers the real-time media stack a voice-first mobile app depends on, and our AI-for-video-engineering knowledge base tracks the model side.
Second, mobile voice is where small engineering choices compound quickly. The difference between a voice feature that feels instant and one that feels broken is usually 200 milliseconds, one missing permission string, or a misplaced retry loop. We’ve done enough of these to have a repeatable checklist.
Third, app-store reviewers have gotten stricter on voice and microphone permissions. Between 2023 and 2026, rejection rates for voice apps that skimped on privacy disclosures climbed sharply. A voice feature that can’t pass App Store or Play review is worth zero.
Our bias, stated up front: we don’t believe in voice-everywhere. Voice is the right modality for hands-free, eyes-free, or accessibility-first contexts. It’s the wrong modality for dense data entry or private-in-public interactions. The best voice features in 2026 are surgical, not ambient.
What “AI voice recognition in mobile apps” actually means in 2026
The phrase covers five distinct capabilities. Most product teams conflate them — and most RFPs underspec the one they actually need.
1. Voice dictation
User speaks, app transcribes. Fast input for long text, particularly on phones. Gboard, Otter, Rev, medical scribe apps (Nuance DAX, Abridge, Suki) are the archetypes. Accuracy and streaming responsiveness matter more than anything else.
2. Voice commands
User speaks a bounded phrase mapping to an in-app action: “pause,” “next track,” “find my insurance card,” “add this to cart.” Peloton, Spotify, Walmart’s voice ordering, and CarPlay app integrations all live here. Grammar is constrained; the hard part is latency and precision.
3. Voice search
User speaks a free-form query; the app resolves it to search. Amazon, eBay, Zillow, food-delivery apps all ship voice search. Requires ASR + intent + result rendering — plus graceful fallback when the transcript is wrong.
4. Voice-first conversational agents
Full spoken dialog. Bank of America’s Erica, ChatGPT voice mode, medical-intake bots, fitness coaches. This is the ASR → LLM → TTS (or speech-to-speech) loop, with memory and multi-turn reasoning. Highest technical bar, biggest product payoff.
5. Voice biometrics
Speaker verification as an authentication factor. Banks and call centres have used it for a decade; it’s now creeping into mobile onboarding, insurance, and healthcare. Governed by BIPA, GDPR Article 9, and CCPA/CPRA — not a feature to bolt on without legal review.
Every production voice feature in 2026 is one of these five. Pick the one you actually need; then pick the stack that fits it. Over-scoping is the most common reason voice features ship late.
The market: why voice in mobile is compounding 20%+ a year
Three overlapping markets drive voice features in mobile apps. All three are growing in double digits.
| Market | Size (2024–25) | CAGR | Sources |
|---|---|---|---|
| Speech & voice recognition | $8.5 B (2024) → $23.1 B (2030) | 19.1% | MarketsandMarkets |
| Voice commerce | $42.8 B (2023) → $186 B (2030) | ~24.6% | Grand View Research |
| Voice biometrics | $2.6–2.9 B (2025) | 16–22% | Mordor, Fortune Business Insights |
| ASR / conversational AI segment | $2.5 B (2024) | 24.8% | Grand View Research |
User behaviour is the tell. Roughly 27% of mobile searches are now voice queries; 56% of voice searches happen on smartphones; nearly 77% of 18–34-year-olds use voice search at least weekly. And voice-ordering penetration in US retail hit approximately 49% of consumers by 2025 — not “available,” but used.
Voice isn’t replacing touch. It’s eating the edges where touch is bad: driving, cooking, mid-workout, holding a sleeping baby, small-motor disability. Any mobile app whose users are in one of those contexts — even 10% of the time — has a voice opportunity.
The mobile voice pipeline: seven stages on a phone
Mobile voice is not desktop voice with a smaller screen. The phone is a very different engineering target: small battery, strict background rules, close-talking microphone, unreliable network. Every serious mobile voice feature runs through these seven stages.
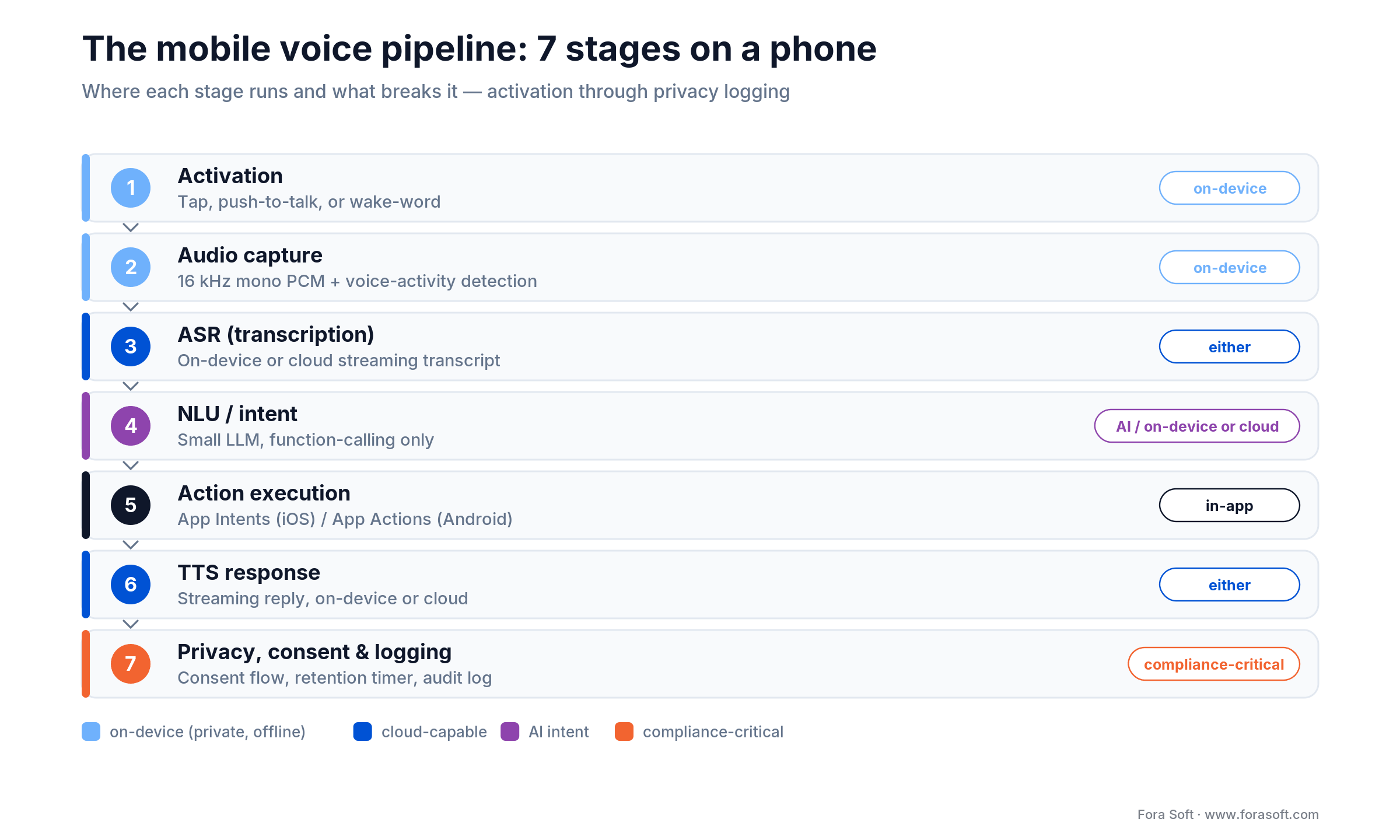
Figure 1. The seven stages every mobile voice feature runs through — and where each one runs.
Stage 1 — Activation
How does voice start? Three options: user taps a microphone button (cheapest, most-rejection-proof), user holds a push-to-talk button (cleaner UX for commands), or a wake-word runs continuously (“Hey Acme”). Wake-word on iOS requires Apple’s restricted background audio modes; on Android it needs a foreground service and a persistent notification. Picovoice Porcupine is the most common third-party wake-word engine; Sensory TrulyHandsfree is the enterprise-grade alternative.
Stage 2 — Audio capture
iOS: AVAudioEngine or AVFoundation capture at 16 kHz, mono, 16-bit PCM. Android: AudioRecord or MediaRecorder at the same specs. VAD (voice activity detection) trims silence before transmission — Silero VAD or WebRTC VAD are the community defaults. Good VAD cuts data volume and ASR cost by 40–60% on typical mobile voice sessions.
Stage 3 — ASR
Three routes: on-device (Apple Speech framework / SpeechAnalyzer, Android SpeechRecognizer with Gemini Nano support, whisper.cpp, Picovoice Leopard, Vosk), cloud streaming (Deepgram Nova-3, Google Chirp 3, Azure Speech, AssemblyAI Universal-2, OpenAI Realtime API), or hybrid (on-device first, cloud-validated when confidence is low). The choice depends on latency budget, offline requirement, language mix, and privacy posture.
Stage 4 — NLU / intent
Transcript becomes intent. For small command vocabularies, a regex or tiny classifier is enough. For open dialog, a small LLM with function calling: Claude Sonnet 4.6 or GPT-4o in the cloud; Apple Intelligence or Gemini Nano on-device. Keep the LLM constrained to function calls — free-text responses are 3× slower and 10× more expensive than a structured output.
Stage 5 — Action execution
The intent resolves to a function call inside the app: add-to-cart, start-workout, call-tenant, open-document. iOS App Intents (iOS 16 +) and Android App Actions let the OS-level assistant trigger your actions without the user opening the app. This is the “Siri Shortcuts for voice” layer — shipping it means your app shows up in Siri suggestions and Assistant routines.
Stage 6 — TTS response
If the app talks back, TTS runs either on-device (AVSpeechSynthesizer on iOS, Android TextToSpeech) or cloud (ElevenLabs, OpenAI TTS, Google Chirp 3 HD). ElevenLabs Flash v2.5 at ~75 ms TTFB is the lowest-latency cloud option; on-device TTS is free but less natural. Streaming is mandatory for anything conversational.
Stage 7 — Privacy, consent, and logging
Permission strings in Info.plist (iOS) and AndroidManifest.xml. App Privacy labels on App Store Connect. Data Safety section on Google Play Console. In-app consent flows for biometric usage. Audit-safe logging with retention policies. Skip any of these and the app either gets rejected or gets sued.
On-device vs cloud: the most consequential choice
Ninety percent of the design debate on a voice-in-mobile project comes down to on-device or cloud. Here is the trade-off matrix we use.
| Dimension | On-device (Apple Speech, Gemini Nano, whisper.cpp) | Cloud (Deepgram, Chirp, OpenAI Realtime) |
|---|---|---|
| Latency | 100–400 ms, no network variance | 200–600 ms, adds network RTT |
| Accuracy (WER) | 6–12% on clear speech; worse on noisy / accented | 3–7% (Nova-3, Chirp 3) |
| Languages | ~30 on iOS, ~70 on Android with Gemini Nano | 100 + (Chirp 3), 30 + (Nova-3) |
| Offline capability | Yes — airplane, rural, tunnels | No — requires connection |
| Privacy | Audio never leaves the device | Audio transits vendor servers |
| Battery impact | Higher during recognition; neural engine helps | Lower CPU, but uses radio |
| App size | +50–1,200 MB for bundled models | Near-zero |
| Cost per minute | Zero marginal | $0.003–0.01 streaming |
The right answer is almost always hybrid. On-device for short commands, wake-words, and privacy-sensitive flows (health dictation, financial queries). Cloud for multilingual dictation, long-form transcription, and open-ended conversational agents. Let the app pick per session, not per app.

Figure 2. On-device versus cloud ASR — the advantage in green, the trade-off you accept in orange.
Practical rule: default to on-device when the transcript never leaves the phone, the language is in the top 10 the OS supports, and the expected utterance is under 10 seconds. Route to cloud otherwise. Surface the choice to the user (a lock icon = private / on-device) — trust is the feature.
The Apple voice stack: SpeechAnalyzer, App Intents, Apple Intelligence
Apple reorganised its voice APIs in 2025 at WWDC. The legacy SFSpeechRecognizer still works, but new code should move to SpeechAnalyzer (iOS 26), which integrates with the Apple Intelligence on-device stack, ships modules for long-form transcription (SpeechTranscriber), short utterances (DictationTranscriber) and voice-activity detection (SpeechDetector), and — per Apple’s own WWDC 2025 numbers — runs about 2× faster than Whisper Large V3 Turbo. It exposes richer metadata: confidence, word timings, language detection.
Practical notes for iOS voice features in 2026:
- On-device is the default. Apple Intelligence runs on A17 Pro / M-series chips and above. On earlier hardware, Speech falls back to cloud transcription — which needs a permission string users understand.
- App Intents replace Siri Shortcuts donations. Declare voice-triggerable actions via the App Intents framework, ship parameterised intents (“start a workout for 30 minutes”), and Siri surfaces your app automatically. This is the cheapest distribution channel in mobile voice.
- Background audio needs a mode. Continuous listening outside the foreground requires
UIBackgroundModes: audioand a clear user-facing reason. Apple reviewers push back on speculative “always listen” use cases. - Permission string matters.
NSSpeechRecognitionUsageDescriptionandNSMicrophoneUsageDescriptionboth required. Write them as specific verbs, not generic disclaimers. “To transcribe your voice notes in the session log” passes review; “To provide voice features” does not.
The Android voice stack: ML Kit GenAI, Gemini Nano, App Actions
Android’s story in 2026 is dual-track. The baseline SpeechRecognizer API handles simple recognition on any modern device. ML Kit GenAI, with on-device Gemini Nano on Pixel 9/10 and Galaxy S24/S25 and above, handles intent + response for advanced use cases — privately, offline, and free to run.
Practical notes for Android voice features in 2026:
- App Actions are the equivalent of App Intents. Declare capabilities in
shortcuts.xmlso Google Assistant and Gemini can trigger your app by voice. This is where most apps leave distribution on the table. - Foreground service for continuous listening. Android 14 + tightened foreground-service restrictions; a “microphone” foreground-service type is required and triggers a persistent notification.
- Gemini Nano access is device-gated. Design features so they gracefully degrade to cloud ASR on older phones — otherwise 40% of your user base gets a worse experience.
- Data Safety declarations are strict. Google Play’s ML-powered review actually parses SDK imports and flags undeclared audio data flows. Declare every ASR SDK you use — even if the data is “ephemeral.”
Cross-platform: React Native, Flutter, Capacitor
If you’re not native on each OS, pick SDKs that match your framework. This is where projects silently burn weeks.
| Framework | ASR options | TTS options | Gotchas |
|---|---|---|---|
| React Native | @react-native-voice/voice, expo-speech-recognition, Deepgram SDK, AssemblyAI SDK | react-native-tts, expo-speech | New Architecture (Fabric / TurboModules) adoption broke some legacy voice modules; verify module compatibility before starting. |
| Flutter | speech_to_text, deepgram_speech_to_text, Google Cloud Speech SDK | flutter_tts, google_tts | iOS privacy-string plumbing via Info.plist is manual; the plugin doesn’t set it for you. |
| Capacitor / Ionic | @capacitor-community/speech-recognition, @capgo/capacitor-speech-recognition | @capacitor-community/text-to-speech | Background listening is uneven across Capacitor plugins — test on real devices, not simulators. |
| Native (Swift / Kotlin) | Apple Speech / SpeechAnalyzer; Android SpeechRecognizer; any cloud SDK | AVSpeechSynthesizer; Android TextToSpeech | Maximum control, highest effort. Default choice when latency or privacy matter. |
If your app is fully native, stay native for the voice layer — RN or Flutter bridges add 50–150 ms of overhead that you feel on every interaction. If your app is already cross-platform, pick plugins aligned with a recent release and plan for native-code fallbacks on hot paths.
Planning voice for your mobile app?
We’ll audit your codebase — native, React Native, or Flutter — recommend the stack, and scope an 8–12-week integration. No obligation.
Latency budget: the 1-second rule
Mobile users are unforgiving about voice latency. Empirically, responses under 500 ms feel instant; 500–1,000 ms feels responsive; 1–2 seconds feels sluggish; anything past 2 seconds and users tap instead. Here’s our target budget for a voice command that executes an in-app action.
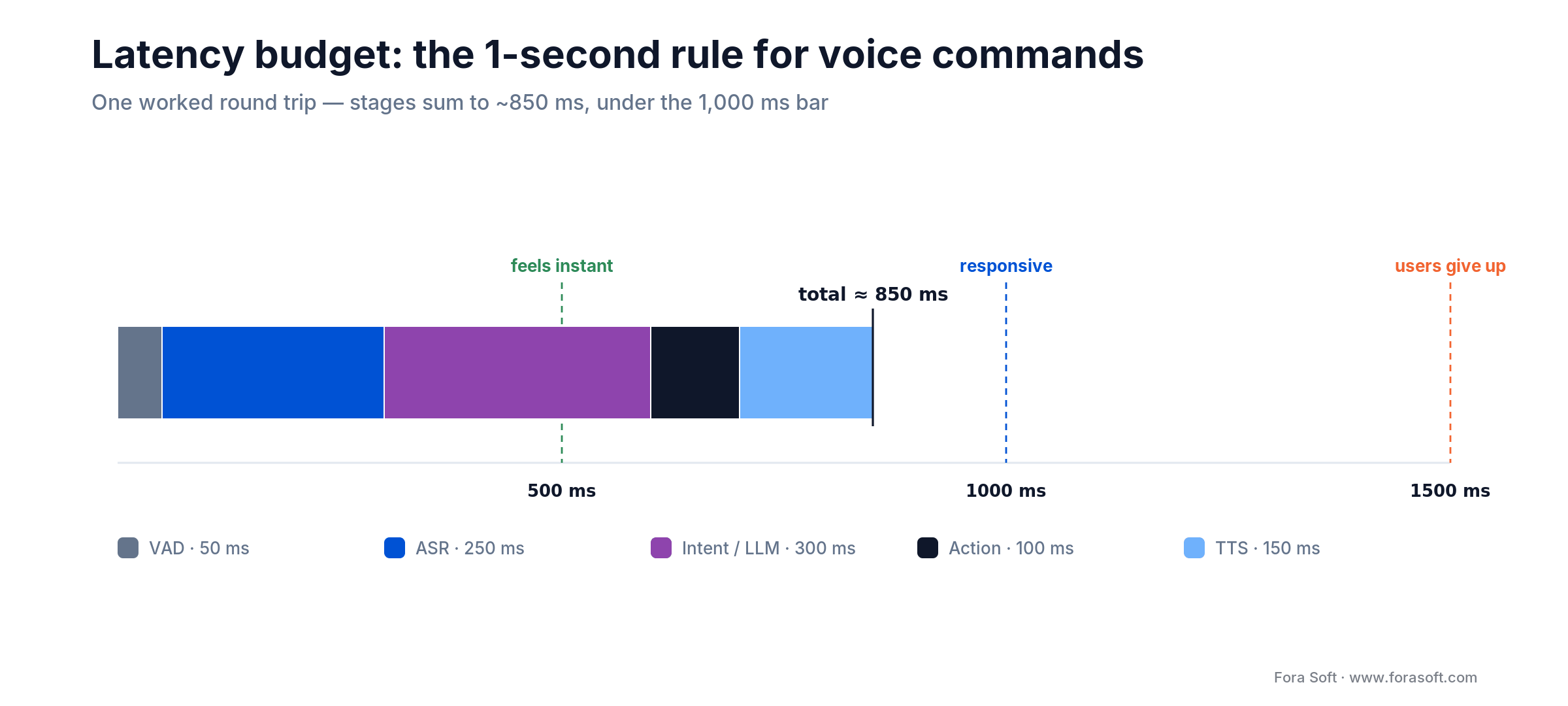
Figure 3. A worked latency budget — five stages summing to ~850 ms, comfortably inside the 1-second rule.
| Stage | Budget | Notes |
|---|---|---|
| VAD & end-of-speech | ~50 ms | Silero VAD or WebRTC VAD on-device. |
| ASR (first transcript) | 100–400 ms | Deepgram Nova-3 sub-300 ms cloud; Apple Speech ~200 ms on-device. |
| Intent / LLM | 100–500 ms | Small classifier <50 ms; GPT-4o / Sonnet 4.6 function-calling 300–500 ms. |
| Action execution | 50–150 ms | API call, local database update, UI state. |
| TTS first audio | 75–250 ms | ElevenLabs Flash ~75 ms; Apple AVSpeechSynthesizer ~200 ms. |
| Total | ~375–1,350 ms | Target <1,000 ms end-to-end for commands; <1,500 ms for dialog. |
A few of the easiest wins, in order: stream ASR (don’t wait for utterance end); use a small classifier before the LLM for obvious commands; stream TTS first-token audio; prefer speech-to-speech (OpenAI Realtime, Gemini native audio) for conversational features; keep one persistent WebSocket to the ASR provider rather than reopening per session.
Permissions and privacy: the UX that gets your app approved
Voice features get rejected at the App Store and Play more often for privacy than for functionality. The reviewer’s mental model: if the user might not expect audio to leave the device, the user must be told, precisely, before it does.
iOS permission UX
- Declare both
NSMicrophoneUsageDescription(microphone capture) andNSSpeechRecognitionUsageDescription(Speech framework, which may route to Apple servers on older chips). - Pre-prime the permission. Show an in-app explanation screen before the system prompt — apps with a pre-prime see 20–30% higher grant rates.
- App Privacy “nutrition label” on App Store Connect must accurately declare all voice-data flows — linked or not, collected for analytics or not. A missing declaration means rejection.
- Guideline 5.1.1 (data collection / privacy) is the most common rejection anchor for voice apps. Have a published privacy policy and an in-app link to it.
Android permission UX
- Declare
android.permission.RECORD_AUDIOinAndroidManifest.xmland request at runtime via Activity Result API. - For continuous listening, declare
FOREGROUND_SERVICE_MICROPHONE(Android 14 +) and keep a persistent notification. - Data Safety section must enumerate each third-party ASR SDK and the data each sends. Play’s automated review flags mismatches.
- For health / financial voice flows, the app-category designation pulls in additional policies — check the Developer Program Policies specific to your category.
Consent flows
If your app stores voice recordings for later review (medical dictation, customer-support callback, training data), you need explicit consent — not a checkbox buried in ToS. If you use voice biometrics as an auth factor, you’re in BIPA / GDPR Article 9 territory and need a dedicated consent flow with a published retention policy. We build this as first-class UI; retrofitting it later is painful.
Compliance: HIPAA, PCI, GDPR, BIPA, COPPA, EU AI Act
A compact tour. Every voice-in-mobile project hits some of these. Build them into the architecture from day one.
- HIPAA — medical dictation, telehealth, senior-care apps. Voice transcripts often contain PHI. Requires Business Associate Agreements with every voice SDK provider, encryption at rest and in transit, audit logging, 6-year retention. Nuance DAX, Abridge, and Suki are HIPAA-eligible; most consumer ASR SDKs are not without a negotiated BAA.
- PCI DSS — voice payment flows. If the user speaks a card number, the audio and transcript are in PCI scope. Most teams route payment voice through a dedicated isolated service (Voice IVR providers like CDW, Cisco, or Plivo) rather than trying to PCI-scope their whole mobile app.
- GDPR — any EU user. Voice is personal data by default; voiceprints are Article 9 special category. Requires lawful basis, explicit consent for biometrics, DPIA, EU data residency, right-to-delete tooling. EDPB 2024–2025 guidance tightens enforcement.
- BIPA (Illinois) — any voice biometric use with Illinois residents. Written consent, published retention, destruction timeline. Active class-action venue.
- CCPA / CPRA (California) — voice recordings and voiceprints are sensitive personal information. Opt-in for sensitive processing, right-to-delete.
- COPPA — users under 13. Verifiable parental consent before collecting voice. Education apps get this wrong frequently.
- EU AI Act Article 50 — from 2 August 2026, any AI voice agent interacting with users in the EU must tell them they’re talking to AI, with fines up to €15M or 3% of global turnover. A short opening line (“Hi, I’m Acme’s AI assistant”) satisfies it.
- Tennessee ELVIS Act — no TTS cloning of real voices without consent. Use vendor-provided synthetic voices unless you have a signed release.
A compliance shortcut that actually works: treat every voice transcript as personal data from the moment it leaves the microphone, and every voiceprint as Article 9 / sensitive-PI. You’ll over-engineer for 20% of regulations but you’ll never be surprised by an enforcement action. The cost of that discipline at design time is roughly one sprint; the cost of adding it after a BIPA class action is ~$50–250 k and a settlement.
Building voice into a regulated app?
HIPAA, PCI, BIPA, COPPA, the EU AI Act — we’ve shipped voice through all of them. Book a call and we’ll map your compliance surface before you commit to a stack.
Offline-first voice: when the phone has to work without the cloud
Some apps don’t get to assume connectivity. Airlines ban radio below 10,000 feet. Field-service apps operate in basements and rural areas. Medical apps sometimes can’t legally send audio off-device. For these contexts, offline voice is non-negotiable.
The practical options in 2026:
- Apple Speech / SpeechAnalyzer on-device — iOS 26+; Apple Intelligence features need A17 Pro / M-series. Adequate WER on clean speech for the top 30 languages. Free, instant, no bundled model weight.
- Android SpeechRecognizer + Gemini Nano — Pixel 9/10, Galaxy S24/S25 and up; the latest Nano shipped on Pixel 10 in August 2025. Same category as Apple’s on-device stack; gracefully degrades to cloud on older devices.
- whisper.cpp — Whisper ported to C++ with Metal / NNAPI acceleration. Runs on any modern phone, but the smallest viable model (small.en) is ~150 MB. Larger models (medium, large-v3-turbo) give near-cloud WER but add ~500 MB–1.5 GB to the app. Ship them as downloadable assets, not bundled.
- Picovoice Leopard / Cheetah — commercially licensed, ~30 MB, real-time on mobile, ~90% accuracy on clean English. Paid, but predictable.
- Vosk — open-source, Kaldi-based, ~50 MB models per language, ~85% accuracy. Good for low-resource projects.
A rough rule: the Whisper small.en model on an iPhone 15 transcribes a minute of clean speech in ~10 seconds — roughly 6× real-time — at ~95% accuracy on clean audio. Battery impact is noticeable but not dire: a 10-minute dictation session uses 3–5% battery on a modern phone. Bundle the model as a downloadable asset, cache aggressively, and let users opt in.
Use cases that are working in 2026
Who is shipping voice features that users actually use? A tour of what’s shipping and getting used.
Retail & voice commerce
Amazon, Walmart, eBay, and Starbucks all ship voice-activated reorder and voice search in their mobile apps. Walmart Voice Order hit mainstream usage years ago; Starbucks’ voice ordering cut drive-through queue time measurably. Grand View Research puts voice commerce on a 24.6% CAGR path to $186 B by 2030. The pattern that works: voice for re-order of known SKUs, touch for discovery.
Healthcare & medical dictation
Nuance DAX Copilot (Microsoft), Abridge, Suki, DeepScribe. Abridge raised a $300M Series E at a $5.3 B valuation in June 2025 (on top of a $2.75 B Series D in February), signalling investor confidence that AI ambient clinical documentation is now enterprise infrastructure, not a pilot. The feature set is narrow (capture visit audio, generate SOAP notes, structured billing codes) and the compliance bar is steep (HIPAA, SOC 2, data residency). We’ve built exactly this kind of HIPAA-compliant clinical workflow ourselves on CirrusMED.
Fintech & voice banking
Bank of America’s Erica is the poster child — now serving roughly 50 M users and past 3 billion interactions as of 2025, with voice-enabled balance checks, transfers, and bill pay. Capital One, Chase, and Wells Fargo have similar in-app voice agents. The common design pattern: voice for queries, but touch confirmation for transactions — PCI scope plus deepfake risk makes voice-only authorisation indefensible.
Automotive & hands-free
Cerence AI (the spun-out Nuance automotive unit), Android Auto with Gemini, CarPlay with Siri. 2026-model-year vehicles increasingly ship built-in voice, and the mobile-app version has to dovetail cleanly via CarPlay and Android Auto media and messaging intents. If your app runs in the car, a voice-first mode is effectively required.
Accessibility & inclusion
Voice is the clearest accessibility multiplier on mobile. Over 5,000 US ADA-accessibility lawsuits were filed in 2025, up ~20% year over year. Apps with motor- or vision-impaired users benefit directly from a voice-first mode — and it’s one of the few features where the inclusive design argument and the commercial argument fully align.
Fitness & wellness
Peloton added voice commands to its iOS app in 2024. Strava, Nike Run Club, and Apple Fitness+ all support voice trigger + narration. The use case fits the medium: mid-workout, hands wet, phone strapped to an arm — voice is the only modality that works.
Dictation & productivity
Gboard’s voice input covers 900+ languages. Otter and Rev ship transcription apps with real-time voice capture. Willow, a newer entrant, markets 4× faster typing via voice + tactile hybrid. Voice productivity is a mature category — the differentiator is no longer ASR accuracy but post-processing (punctuation, formatting, speaker separation, translation).
Mini case: hybrid voice on a React Native productivity app
Context: a North American productivity SaaS with ~450 K active mobile users wanted voice capture for meeting notes inside its existing React Native app. Requirements: offline capability on planes, multilingual support for European team members, sub-1-second perceived latency, and no new App Store category that would trigger re-review.
Scope we shipped:
- Hybrid ASR — Apple SpeechAnalyzer / Android SpeechRecognizer on-device as the default; Deepgram Nova-3 cloud fallback when the user opts into multilingual mode.
- whisper.cpp small.en bundled as a downloadable asset for offline mode; triggered only when the user explicitly toggles “offline capture.”
- Claude Sonnet 4.6 with function-calling schema for post-capture processing (format, summarise, extract action items, assign to a note).
- Streaming UI — partial transcript updates every 150 ms, visible waveform, clear “Listening” / “Processing” state transitions.
- Permission UX redesign — pre-primed mic and speech-recognition permission with a one-paragraph explanation and a “Not now” option. Grant rate climbed from 58% to 83%.
- App Intents + App Actions — “Hey Siri, capture a note in [AppName]” and “OK Google, take a meeting note” both worked from lock screen.
Measured outcomes, 90 days post-launch:
- Voice-captured notes were ~38% of all new notes on iOS and ~31% on Android (up from zero).
- Median end-to-end latency from “stop speaking” to formatted note: ~850 ms on-device, ~1.3 s cloud.
- App Store review passed on first submission. Zero privacy-related rejections.
- Overall project timeline from kickoff to v1 production launch: 10 weeks, including 2 weeks of soak testing.
Details anonymised at the customer’s request. The architecture has been the template for every mobile voice engagement we’ve scoped since.
5 pitfalls that kill mobile voice projects
1. Shipping voice without streaming UI
If the user says something and the app goes silent for 2 seconds, they assume it broke. Always show a waveform, a partial transcript, or at minimum a spinner. Perceived latency is the feature.
2. Letting the LLM free-form
Open-ended LLM responses on mobile voice are slow, expensive, and occasionally hallucinated. Keep the LLM to function calling with enum intents. If you need longer replies, template them and let the LLM fill slots.
3. Ignoring CarPlay / Android Auto
Users who use voice on your app 10% of the time use it 90% of the time in the car. If your app doesn’t work from CarPlay and Android Auto voice intents, you’re shipping half a voice feature.
4. Under-disclosed data flows
The single most common App Store / Play rejection for voice apps in 2025 was incomplete privacy disclosure — a third-party ASR SDK sending audio off-device without it being listed on the Data Safety / App Privacy page. Automate the audit. Check every SDK’s data-flow documentation before you submit.
5. Not planning for failure
Voice fails. The network drops. The transcript is garbled. The user doesn’t know what to say. Every voice feature needs a graceful path back to touch UI — a “type instead” button, a “retry” prompt, a “tap to cancel.” Apps that don’t design failure paths lose users at every stumble.
Reach for fully on-device voice when: the app handles regulated data (HIPAA, PCI), the target market has strict residency rules (EU, Switzerland, Brazil), or the use case demands airplane / tunnel / rural reliability. Cloud is default; on-device is the right answer for a meaningful minority — and one that’s growing.
KPIs: how to tell if your voice feature is working
Three buckets. Instrument all of them from day one.
Quality
- WER on real user audio — target <10% after phrase biasing.
- Intent accuracy — target >95%; false-action rate <0.5%.
- Median end-to-end latency — <1,000 ms for commands; <1,500 ms for dialog.
- Retry rate — % of sessions where user rephrased. Target <15%.
Adoption
- Voice DAU — % of daily active users who used voice.
- Permission grant rate — % of users who granted mic + speech permissions.
- Feature share — % of target tasks (note capture, search, order, reorder) completed via voice vs touch.
- Retention uplift — cohort retention for voice users vs non-voice users.
Compliance & reliability
- App Store / Play rejection rate — target zero for voice-related reasons.
- Consent capture rate — % of voice sessions with logged consent where required.
- Vendor-failover pass rate — monthly chaos test on cloud ASR + LLM + TTS fallbacks.
- Right-to-delete response time — target <30 days (GDPR), <45 days (CCPA).
When NOT to add voice to your mobile app
A candid list. Five scenarios where voice is the wrong answer.
- Dense data entry with tight validation — tax forms, multi-field search. Voice increases error rate on numeric entry. Touch is better.
- Privacy-sensitive-in-public use — saying your credit-card number on a crowded train. Users will refuse the feature even if it works.
- Single-screen, single-tap flows — if the user can already do the task in one tap, voice is slower.
- Low-volume features — if the target feature has 200 users a month, voice engineering cost exceeds value. Pick a bigger surface.
- Jurisdictions without clear biometric law — if your feature needs voice biometrics and your target market’s biometric regime is unresolved, hold off until the legal picture is clear.
A decision framework — pick your stack in five questions
Every mobile-voice RFP we’ve scoped collapses to these five questions. The answers pick the stack.
- Which of the five voice capabilities do you actually need? Dictation, commands, search, conversational agent, or biometrics. Don’t scope two.
- Is offline a hard requirement? If yes → Apple Speech / Gemini Nano / whisper.cpp. If no → Deepgram / Chirp / OpenAI Realtime cloud.
- How many languages? Top 10 → on-device is fine. 20 + → cloud via Chirp 3 or Whisper API.
- Closed grammar or open dialog? Commands / search → small classifier, no LLM. Dialog → LLM with function calling (Sonnet 4.6, GPT-4o, or on-device Apple Intelligence / Gemini Nano).
- Which compliance regimes apply? HIPAA → BAA-covered vendors + on-device where possible. PCI → isolated voice payment path. GDPR → EU data residency. BIPA → written consent + retention policy. Plan these on day one.
Integration playbook: the 8–12-week path
What a voice recognition app development engagement actually delivers when a customer brings us a mobile voice feature. Timeline assumes an existing iOS + Android app with a backend; green-field projects add 2–3 weeks.
| Weeks | Phase | Deliverables |
|---|---|---|
| 1 | Discovery & architecture | Use-case scoping, jurisdiction map, stack selection, permission and UX wireframes, DPIA where needed |
| 2–3 | Foundation | Audio capture, VAD, permission UX, App Privacy / Data Safety declarations, feature-flag framework |
| 4–5 | ASR layer | On-device integration (Apple Speech / Android SpeechRecognizer), cloud streaming fallback (Deepgram / Chirp), waveform UI |
| 6–7 | Intent + action execution | LLM with function calling, intent classifier, action handlers, fallback flows |
| 8 | TTS & system integration | Streaming TTS, App Intents / App Actions, CarPlay / Android Auto hooks, Siri / Assistant surface registration |
| 9 | Compliance & audit | Consent flows, audit log, retention timers, right-to-delete tooling, AI disclosure copy |
| 10 | Soak test & tuning | Real-traffic beta, WER measurement, phrase biasing, KPI dashboard, App Store / Play submission prep |
| 11–12 | Submission & launch | App Store / Play submission, reviewer Q&A, staged rollout, on-call runbook, ML-ops for drift |
Our AI-pair engineering workflow compresses weeks 4–7 by roughly 30% compared to a human-only team. The LLM helps most with integration boilerplate — SDK wiring, permission strings, test scaffolding — not with the architectural calls.
Running the feature is cheap, and the bill mostly tracks how much you route to the cloud. Here’s the per-user math for a typical consumer app.
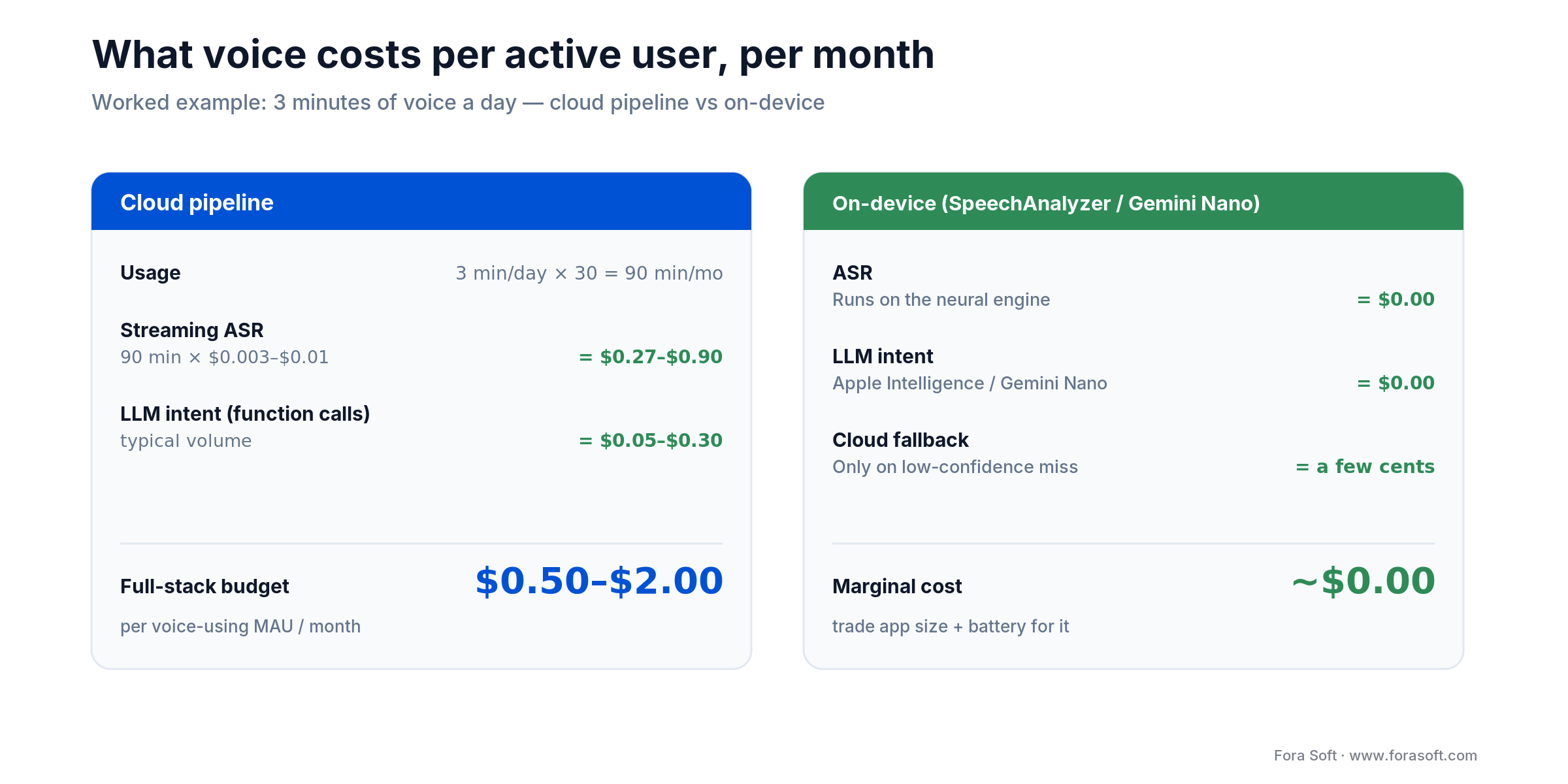
Figure 4. What voice costs per active user each month — cloud pipeline versus on-device.
Ready to scope your build?
Bring your app, your target use case, and your jurisdictions. We’ll come back with a scoped voice recognition app development plan in five business days.
Where mobile voice is heading in 2026–2027
Four trends to plan around.
Speech-to-speech collapses the pipeline
OpenAI’s gpt-realtime and Gemini’s native audio skip the ASR → LLM → TTS cascade entirely. End-to-end latency drops to 200–300 ms voice-to-voice and prosody improves noticeably. The trade-off is less control over the transcript and the intent pipeline — good for conversational features, less ideal for security-critical or compliance-heavy flows.
On-device LLMs get genuinely usable
Apple Intelligence, Gemini Nano, quantised Llama 3.3 and Mistral Small 3 via MLC or llama.cpp all put a real 3B–8B LLM in the pocket. For bounded voice features (commands, short queries, summarisation), the phone stops needing the cloud at all. Privacy improves, latency improves, and the cost per interaction goes to zero.
App Intents / App Actions become the distribution channel
Siri and Gemini now surface your app’s voice-triggerable actions system-wide. Apps that declare rich App Intents / App Actions get discovered in the assistant surface; apps that don’t get left out of the new interaction layer. The winners are already investing here.
Voice-first AR / wearables
Vision Pro, Meta Orion, smart glasses — all voice-primary input surfaces. Mobile apps that ship clean voice interfaces in 2026 are positioned for the AR interface that’s coming in 2027–2028. Those that don’t will scramble to retrofit.
FAQ
How accurate is on-device voice recognition in 2026?
Apple SpeechAnalyzer and Android SpeechRecognizer (with Gemini Nano) typically deliver 6–12% WER on clean speech in top-tier languages — close enough to cloud accuracy for most command and dictation use cases. Whisper small.en on-device clocks ~95% accuracy on clean English; larger models (medium, large-v3-turbo) get to cloud-parity but cost 500 MB–1.5 GB of storage.
How much does voice ASR cost per user per month?
Cloud streaming ASR prices range from $0.003 to $0.01 per minute. A typical consumer app user doing 3 minutes of voice per day costs $0.27–$0.90 per month on ASR alone. On-device ASR is free. LLM intent calls add another $0.05–$0.30 per month at typical volumes. Budget $0.50–$2 per voice-using MAU for a full stack.
Will Apple or Google block third-party voice SDKs?
Unlikely — but both require you to declare third-party data flows on App Privacy / Data Safety pages. As long as the declaration is accurate and the SDK vendor has a defensible privacy stance, approval is routine. The issue is mis-declaration, not third-party use.
Should I use OpenAI’s Realtime API or build my own pipeline?
Use Realtime API for conversational features where voice-to-voice prosody matters and the transcript is secondary. Build your own ASR + LLM + TTS pipeline when you need the transcript for compliance, the domain vocabulary for phrase biasing, or the flexibility to mix vendors for cost or redundancy. Most production mobile apps use both — Realtime for the dialog agent, custom pipeline for dictation and search.
How do I handle multilingual users?
Cloud is still the right path for 20 + languages. Google Chirp 3 covers 100 + with automatic language detection; Deepgram Nova-3 covers the top 30 at production quality; OpenAI Whisper covers 99 with good accuracy but lower latency. Plan for per-user language preference storage, and default to device locale.
Is voice worth it for a B2B app with under 10 K users?
Sometimes. If the target workflow is hands-busy (field service, clinical, warehouse), voice is a retention multiplier even at small scale. If the workflow is pure desk-bound data entry, touch wins. Ask: what percentage of our users are in a context where they can’t type? If it’s over 20%, voice is worth the engineering.
What’s the biggest source of App Store rejection for voice apps?
Guideline 5.1.1 — data collection and privacy. Specifically: missing or vague permission strings, missing or inaccurate App Privacy label entries, and under-disclosed third-party SDK data flows. Reviewers look at these first. Submit with accurate declarations and a clear in-app explanation before each permission prompt.
How long does a mobile voice integration take?
8–12 weeks for a feature (e.g., voice capture or voice search) on an existing iOS + Android app. 14–18 weeks for a full voice-first conversational agent with compliance overhead (HIPAA / PCI / EU residency). Green-field voice-first apps add 2–3 weeks for app-level scaffolding.
What to read next
Adjacent read
AI voice recognition for intercoms
The voice stack when the target is a panel on the door, not a phone in the pocket — different constraints, same fundamentals.
Deep dive
AI simultaneous interpretation
The architecture for live multilingual voice — directly applicable to multilingual mobile dictation and agents.
Companion piece
AI streaming platform guide
How real-time audio and video streaming architectures scale — the backbone of every serious voice-first app.
Related
AI-powered video surveillance
Where voice meets video in physical security — useful context for any voice app that interoperates with cameras.
Services
AI integration services
How we add ASR, LLM intent, and TTS to production iOS and Android apps.
Sum-up
Voice recognition in mobile apps is no longer a differentiator — it’s table stakes in categories where users are hands-free even 10% of the time. The 2026 stack is ready: Apple SpeechAnalyzer and Gemini Nano for private on-device recognition; Deepgram Nova-3, Chirp 3, and OpenAI Realtime for cloud-grade streaming; ElevenLabs and on-device TTS for the response; App Intents and App Actions for system-wide distribution.
What separates successful voice features from abandoned ones isn’t model choice — it’s latency discipline, permission UX, compliance planning, and failure-path design. Build those in from day one.
If this playbook lined up with where your roadmap is headed, grab 30 minutes with us and we’ll come back with a scoped plan in a week.








