



Key takeaways
• Real-time language translation is a streaming pipeline, not a single API call. Capture → ASR → MT → (optional TTS or captions) → render — every stage adds latency, error, and cost.
• Aim for <1 second end-to-end for conversations, <3 seconds for broadcasts. The best 2026 stacks (AssemblyAI, Deepgram Nova-3, Gladia Solaria, Azure Speech) hit 270–520 ms ASR latency; translation adds 100–400 ms; TTS another 200–600 ms.
• The market is enterprise-driven. AI simultaneous interpreting was ~$2B in 2025 with a projected ~25% CAGR — mostly conference platforms, telehealth, and global call centres replacing human interpreters in non-critical contexts.
• Buy first, build only the orchestration. ASR + MT + TTS quality from cloud vendors is now strong enough that the differentiator is the streaming glue, the UX, the reliability layer — not the model itself.
• The risks are accuracy, accent bias, domain terminology, and compliance. Plan for human-in-the-loop in regulated content (legal, medical, financial) and ship a “machine translation—may contain errors” disclaimer in regulated regions.
Why Fora Soft wrote this playbook
Real-time language translation lives at the intersection of three things we ship in production every quarter: real-time communications (WebRTC, SFU, MCU), speech AI (ASR, TTS, voice biometrics), and applied machine learning. Our AI integration practice ships speech and language pipelines into video calls, telehealth, sales-intelligence, and global market-research platforms.
A concrete reference: VocalViews — used by Samsung, Google and Netflix research teams — runs AI-powered transcription and live translation across 30+ languages over more than 800,000 verified participants and 185,000+ business users. Different vertical, same plumbing: streaming ASR, low-latency MT, and a UX that handles speaker change, turn-taking and partial-result correction.
This is the playbook we wish we had on day one: the architecture, the latency budget, which APIs win in 2026, what build vs. buy actually means, where the cost lives, and the failure modes that surface only at 1,000+ concurrent calls.
What real-time language translation actually is
Real-time language translation is the streaming pipeline that converts spoken or written content from one language to another with a delay short enough to support live interaction. Three flavours dominate. Speech-to-text translation turns spoken source into translated captions. Speech-to-speech translation additionally renders the output as synthesised speech in the target language. Text-to-text translation is the underlying machine translation step, used in chat, support tickets, and live captions.
The architecturally interesting fact: there is no single “real-time translator” model in production. Every shipping system chains an automatic speech recognition (ASR) model, a machine translation (MT) model, and optionally a text-to-speech (TTS) model, with a streaming orchestrator that feeds partial results forward as they arrive.
Adding real-time translation to a video product?
30 minutes with our speech-AI lead and you walk away with the right ASR + MT + TTS combo, a latency budget, and an Agent-Engineering-accelerated timeline.
Where real-time translation actually pays off in 2026
1. Multilingual conferences and webinars. The largest market segment. Wordly, KUDO, Interprefy, Microsoft Teams, X-doc.AI Translive replace or augment human interpreters at trade shows, all-hands and global town halls. AI live translation reaches ~94% accuracy for general business content and pays for itself when you would otherwise hire 2–6 simultaneous interpreters per language pair per day.
2. Video conferencing and meetings. Zoom, Teams, Google Meet now offer captions and translation natively or via marketplace add-ons (Palabra, Maestra, Jotme, KUDO). Adoption is fastest in companies with distributed teams across ≥3 languages. See our overview of multilingual translation in video calls.
3. Customer support and contact centres. Chat translation is mature; voice translation is now reaching production quality with sub-second latency. Use cases: agent assist with translated transcript, automated translation of inbound chat, IVR with voice translation. Vendors: Google Contact Center AI, Amazon Connect, Genesys, plus speech-AI plays from Deepgram, AssemblyAI and Symbl.
4. Telehealth. Multilingual access is increasingly a regulatory and equity requirement. AI translation reduces the language-barrier burden on clinicians; expect human-interpreter handoff for complex visits and FDA-/HIPAA-aware vendor selection.
5. Live broadcast and streaming. Sports, entertainment, news. Latency tolerance is higher (3–6 seconds) but quality, name handling and profanity controls matter more. Pair MT with closed-caption rendering and human review for high-profile streams. See our AI language translation in live streaming guide.
6. Sales and market research. Live translation in sales calls and qualitative-research interviews unlocks global panels at near-domestic cost. VocalViews is the canonical example we have shipped.
7. Education and e-learning. Auto-captioned and translated lectures across language cohorts; live tutoring across borders.
How a real-time translation pipeline works
Figure 1 shows the canonical streaming architecture used by every production system we have built or audited.

Figure 1. Streaming real-time translation pipeline with per-stage latency budget.
Stage 1. Capture and pre-processing
Audio at 16 kHz mono PCM, frames of 20–100 ms, voice activity detection (VAD) to drop silence, optional noise suppression. The single biggest production-quality lever is upstream — bad audio kills the rest of the chain. WebRTC’s built-in noise suppressor and Krisp/Krispy-style add-ons remove a remarkable amount of error before ASR sees the signal.
Stage 2. Streaming ASR
Convert speech to text incrementally. Streaming ASRs emit a stream of partial hypotheses that stabilise as more context arrives. AssemblyAI advertises ~300 ms streaming latency with 99.95% uptime; Gladia Solaria targets ~270 ms with 100-language coverage; Deepgram Nova-3 ships ultra-low latency in noisy environments. Whisper itself is not natively streaming — production deployments use WhisperX-style chunking (380–520 ms latency) or streaming-tuned forks.
Stage 3. Machine translation
Either text-to-text MT (DeepL, Google Translate, Azure Translator, Amazon Translate, NLLB, M2M-100) or, increasingly, an LLM (GPT-4-class, Claude-class, Gemini) prompted with a glossary and tone instructions. LLMs win on context and named-entity handling but cost more per token; MT services win on cost and per-token latency.
Stage 4. (Optional) TTS rendering
If the output is voice, push translated text through a streaming TTS (ElevenLabs, OpenAI tts-1, Azure Neural TTS, Google Cloud TTS, Amazon Polly). Tip: cache the previous chunk while the next chunk renders, then crossfade — that hides 200–400 ms of synthesis time.
Stage 5. Render
Captions: WebVTT or RTC datachannel feeding a positioned overlay, with a 200–500 ms refresh cadence. Voice: WebRTC playout with adaptive jitter buffer. UX rules of thumb: highlight unstable partials in italics, lock stable text once the ASR commits, never erase visible text more than once per sentence.
The latency budget you actually have
| Stage | Conversation target | Broadcast tolerance | Notes |
|---|---|---|---|
| Capture + VAD | 20–60 ms | 100–200 ms | Frame size + jitter buffer |
| Streaming ASR | 270–500 ms | 500–1500 ms | Vendor-bound; first-word latency |
| Translation | 100–300 ms | 200–800 ms | MT API or LLM completion |
| TTS (if voice) | 200–500 ms | 300–1000 ms | Streaming synthesis preferred |
| Render / playout | 50–150 ms | 100–500 ms | Caption refresh cadence |
| End-to-end (captions only) | ~600–1200 ms | ~1.5–3 s | P95, single language pair |
Reach for caption-only translation when: you can hold the budget ≤1.2 seconds and accuracy matters more than spoken voice. Most enterprise meeting use cases land here.
Reach for full speech-to-speech when: the audience cannot read captions (driving, broadcast voice, accessibility) and you accept ~1.8–3 second end-to-end delay.
The 2026 API landscape: who wins where
| Layer | Vendors that ship in production | Strengths | Watch-outs |
|---|---|---|---|
| Streaming ASR | AssemblyAI, Deepgram Nova-3, Gladia Solaria, Google Speech-to-Text, Azure Speech, AWS Transcribe | Sub-500ms latency, 100+ languages, on-device variants | Accent & dialect bias, domain vocabulary tuning required |
| Self-hosted ASR | Whisper / WhisperX / faster-whisper, NVIDIA Riva, NeMo, SeamlessM4T | Data residency, cost at scale, custom fine-tuning | No native streaming for Whisper; SeamlessM4T quality lower in conversational |
| Machine translation | DeepL, Google Translate, Azure Translator, Amazon Translate, NLLB, M2M-100, GPT-4 / Claude / Gemini | Per-language quality varies; LLMs win on context | Glossary discipline, hallucination risk, tone control |
| Text-to-speech | ElevenLabs, OpenAI tts-1, Azure Neural TTS, Google Cloud TTS, Amazon Polly | Natural prosody, voice cloning, low latency | Voice cloning consent, EU AI Act marking obligations |
| Turnkey RT translators | Wordly, KUDO, Interprefy, X-doc.AI, Palabra, Maestra | Days to live, native Zoom/Teams plug-ins, hybrid AI+human | Per-minute pricing, limited customisation, brand presence |
| RTC + speech bundles | Agora STT, Daily AI, LiveKit transcription, Twilio Voice Intelligence, Zoom AI Companion | Built into the call, simpler ops | Opinionated; less flexibility on language pairs |
Reference production architecture
Figure 2 shows the architecture we recommend for product teams shipping multilingual real-time translation in 2026 — isolating the speech and language services behind a single streaming orchestrator gives you per-language pair routing, vendor failover, and cost control.
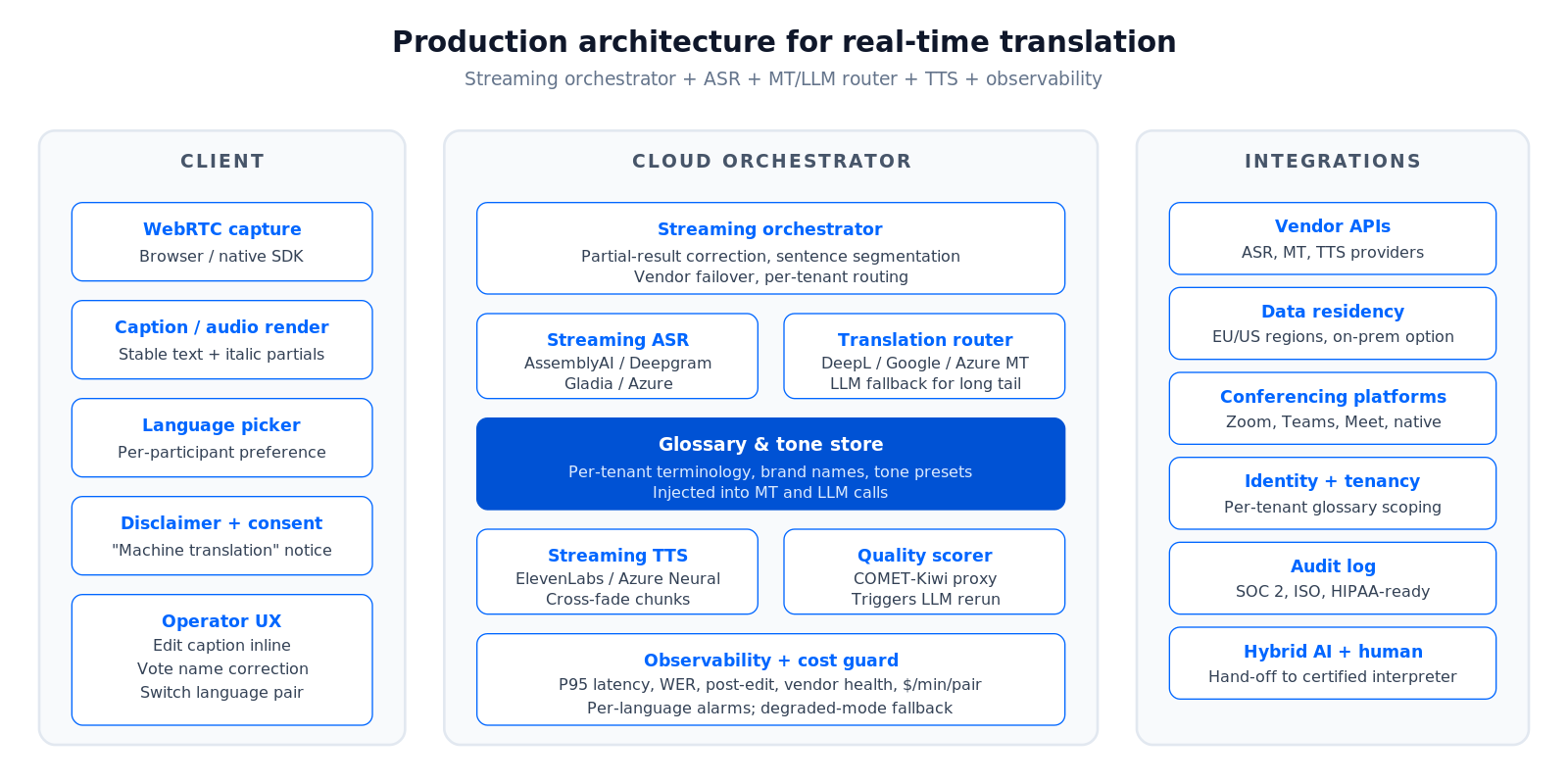
Figure 2. Production architecture for real-time language translation.
Three pieces are non-obvious. The orchestrator owns partial-result correction, sentence segmentation across language boundaries, and TTS chunk planning. The glossary and tone store injects per-tenant terminology and tone constraints into both MT and LLM prompts. The observability layer tracks per-language pair latency, ASR confidence, and post-edit distance so the team can see degradation before customers complain.
LLM vs. classical machine translation: when to switch
Classical MT (DeepL, Google, Azure) is fast, cheap, and deterministic. LLMs are slower per token, more expensive, and sometimes hallucinate — but they handle terminology, idioms, register, code-switching and named entities far better. The 2026 sweet spot is a router: classical MT for the bulk of generic content, LLM call for sentences flagged as terminology-rich, ambiguous, or low-confidence by ASR.
A practical pattern we ship: send every sentence through DeepL, score the output with a small classifier (BLEU/COMET-Kiwi proxies), and re-run the bottom 5–10% through an LLM with a glossary prompt. Costs stay flat; quality on the long tail improves materially.
Mid-build and the latency or accuracy is off?
We have rescued real-time translation rollouts with vendor swaps, partial-result UX fixes, and orchestrator rewrites. Bring us your symptoms.
Build vs. buy — a decision matrix
| Criterion | Buy turnkey (Wordly/KUDO/Palabra) | Build on cloud APIs |
|---|---|---|
| Time to first call | Days | 6–12 weeks with Agent Engineering |
| In-product UX | Vendor-branded | Native, fully customisable |
| Languages & specialism | Pre-set list, generic terminology | Per-tenant glossary, fine-tuning possible |
| Cost shape | Per-attendee or per-minute | ASR + MT + TTS metered separately |
| Data residency | Vendor regions | Anywhere your stack runs |
| Wins when | Conferences, webinars, internal town halls | Product feature, regulated vertical, custom UX |
Cost model: realistic ranges
Numbers below assume our Agent-Engineering-accelerated delivery. Treat as scoping ranges; real numbers depend on language pairs, integrations, and compliance scope.
| Scope | Duration | Build cost | Run-rate |
|---|---|---|---|
| Captions in single language pair | 3–6 weeks | $25k–$60k | ASR + MT per minute |
| Multilingual captions (10+ pairs) | 8–14 weeks | $70k–$160k | Vendor metering scales linearly |
| Speech-to-speech with custom voice | 12–20 weeks | $120k–$280k | +TTS minutes, voice licensing |
| Regulated (medical/legal) deployment | 5–9 months | $200k–$500k | Audit, glossary curation, human-in-loop |
Languages and accents that actually work in 2026
High-resource pairs — English ⇆ Spanish, French, German, Portuguese, Italian, Mandarin, Japanese, Korean — reach business-grade quality with most cloud APIs. Mid-resource pairs (Arabic dialects, Vietnamese, Thai, Polish, Turkish, Hindi) work but expect more variance and budget for a glossary or LLM fallback. Low-resource pairs (Swahili, Yoruba, Bengali, regional Indian languages, Indigenous American languages) need verification on real audio — vendor claims often outpace real WER.
Accents and dialects materially shift accuracy. Independent benchmarks show ASR error rates varying 3–5x across English accents alone (US standard, Indian English, Scottish, Nigerian English, Singaporean English). Test with real users in your top markets before launch and either route to a vendor whose training set covers your audience well or fine-tune on a few hundred hours of accented audio.
Domain accents matter too: medical jargon, legal terminology, finance shorthand and technical product names break generic ASR. Plan for a domain glossary, a custom ASR model when scale justifies it, and a short user-facing “train your assistant” flow that lets early adopters correct names once and never see them mistranscribed again.
Compliance, consent, and the “may contain errors” disclaimer
Real-time translation touches three regulatory zones. Speech and biometric data: voice carries identifying information and falls under GDPR Article 9 in the EU, BIPA-style state laws in the US, and equivalent rules in the UK and APAC — per-user consent and clear retention rules are mandatory. Synthetic voice: EU AI Act transparency obligations (Article 50) require disclosure when content is generated or substantially altered by AI; voice cloning needs explicit consent from the source speaker. Translated medical, legal, or financial content typically requires a clear “machine translation, may contain errors” disclaimer in the target language, and a human-in-the-loop fallback for binding or safety-critical decisions.
Practical patterns we ship: a session-start consent screen with the legal text in every meeting language; a persistent on-screen badge that says “Live machine translation” while captions are active; an audit trail of inferences, vendor used, and consent state; a way for any participant to switch to human-only interpretation mid-session.
Mini case: live transcription and translation across 30+ languages
Situation. A global qualitative-research platform needed live transcription and translation in 30+ languages so research teams in San Francisco could moderate sessions with respondents in Lagos, Tokyo and São Paulo without scheduling human interpreters.
12-week plan. Week 1–2: WebRTC capture bridge + per-region routing. Week 3–6: streaming ASR with vendor failover, MT layered with glossary injection, partial-result UX. Week 7–9: per-tenant terminology, sentiment overlay. Week 10–12: scale tests, observability dashboard, rollout.
Outcome. The platform — VocalViews — serves 800,000+ verified participants and 185,000+ business users across enterprise customers including Samsung, Google and Netflix. Same blueprint plays in adjacent verticals: enterprise sales, telehealth, education.
A decision framework: pick a path in five questions
1. Captions or voice? Captions are the easier ship and serve most enterprise meeting cases at ≤1.2 s. Voice unlocks accessibility and broadcast but adds 600–1500 ms.
2. How many languages and how often? Two language pairs × ad-hoc events — buy turnkey. Ten+ pairs in product × 24/7 — build on cloud APIs.
3. How specialised is the vocabulary? Generic business — classical MT is fine. Medical, legal, financial — LLM with strict glossary or human-in-the-loop.
4. Where can the data live? EU-only, on-prem, US-only? That decides between cloud APIs and self-hosted Whisper/Riva/NeMo.
5. What is the cost ceiling per minute? Anchor between $0.05 (DIY ASR + MT, no TTS) and $0.40 (premium turnkey + voice). Above $0.40 you should buy turnkey; below $0.10 you should build.
Pitfalls we keep seeing
1. Sub-optimising on ASR latency only. A 270 ms ASR feeding a 2,000 ms MT gives you 2.3 s end-to-end. The slowest stage rules; budget the whole chain.
2. No glossary discipline. Brand names, internal terms, product SKUs and people’s names get mistranslated. Inject a per-tenant glossary into every MT call and reject hallucinated translations of named entities.
3. Erasing visible captions too often. ASRs revise partials. UX rule: lock stable text after 600–1000 ms; never re-erase visible content more than once per sentence.
4. Ignoring accent and dialect bias. ASR error rates vary 3–5x across English accents alone. Test with real users in your top markets before launch and consider regional ASR fine-tuning.
5. Forgetting compliance and disclaimers. Machine-translated medical or legal content must carry a clear “machine translation, may contain errors” disclaimer in many jurisdictions, and EU AI Act-aligned transparency for synthesised voice.
KPIs: what to measure
Quality KPIs. Word Error Rate (WER) per language and per accent (target ≤ 8% for English, ≤ 12–15% for under-served languages). Translation BLEU/COMET-Kiwi delta vs. reference. Post-edit distance on a sampled set.
Business KPIs. Feature attach rate, % of meetings using translation, NPS lift among non-native speakers, meeting completion rate, deflected interpreter spend.
Reliability KPIs. P95 end-to-end latency, ASR/MT/TTS uptime, vendor failover events, cost per minute per language pair, model rollback time.
When NOT to use real-time AI translation
Skip pure AI translation when (a) the content is high-stakes legal, medical informed consent, or court testimony — bring in a certified human interpreter; (b) your audience speaks a low-resource language with poor ASR/MT support; (c) the room has heavy crosstalk and accents the vendor cannot handle reliably; (d) you have brand-critical names and terminology and no glossary discipline.
In those situations the better answer is hybrid AI + human: AI for general content, human interpreter for the regulated or brand-critical sessions, with the AI transcript supporting the human.
Ready to scope multilingual real-time translation for your product?
We will audit your video stack, map the right ASR + MT + TTS combo, and come back with a one-page brief you can ship to your board.
FAQ
How accurate is real-time AI translation?
For general business content, ~94% accuracy is achievable for top language pairs. Per-stage error compounds: ASR errors flow into MT, so total fidelity is roughly the product of per-stage accuracies. For specialised domains plan for a glossary, an LLM fallback, or human-in-the-loop.
What is the lowest latency we can hit end-to-end?
For caption-only translation, ~600–1200 ms P95 is achievable with AssemblyAI / Deepgram / Gladia and a fast MT. For speech-to-speech, plan for ~1.8–3 s including TTS. Recent specialised systems with on-device inference have demonstrated <1 s simultaneous interpretation in research demos.
Should I use Whisper or a streaming cloud ASR?
For batch transcription, Whisper is hard to beat. For streaming, cloud ASR (AssemblyAI, Deepgram, Gladia, Azure) is the production default because Whisper is not natively streaming and requires significant chunking and orchestration to feel real-time.
DeepL or Google Translate for the MT step?
DeepL is widely judged stronger for European-language pairs in business writing. Google Translate has wider language coverage and lower cost. Azure Translator integrates well with Azure-native stacks. Test on your domain with COMET-Kiwi or LLM-as-judge before locking in.
Can we use an LLM directly for translation?
Yes, GPT-4-class, Claude-class and Gemini handle translation well, especially for terminology-rich content. Cost per token is higher than classical MT and latency adds 200–800 ms; we recommend a router that uses LLMs only on the long tail.
How do we keep brand names from being mistranslated?
Maintain a per-tenant glossary, inject it into every MT/LLM call, and add a post-translation pass that detects unknown-name hallucinations and substitutes the canonical form back. Most quality complaints we see in production are name-handling issues, not raw model error.
What does it cost to add real-time translation to a video product?
A single-pair captioning MVP runs $25k–$60k over 3–6 weeks. A multilingual captions feature with 10+ pairs runs $70k–$160k over 8–14 weeks. A speech-to-speech build with custom voice runs $120k–$280k over 12–20 weeks. Ranges assume our Agent-Engineering-accelerated delivery.
Is human interpretation still needed?
For high-stakes legal, medical informed-consent, or court use cases, yes — bring in a certified interpreter. For most enterprise meetings, AI translation at ~94% accuracy is enough. The emerging hybrid pattern allocates AI to general content and human interpreters to regulated sessions within the same event.
What to Read Next
Conference tech
AI Simultaneous Interpretation
Deeper dive into video-conference simultaneous interpretation patterns.
Video calls
Multilingual Translation in Video Calls
Patterns for plugging translation into Zoom, Teams, Meet workflows.
Live streaming
AI Language Translation in Live Streaming
Higher-latency tolerance, name handling and broadcast quality controls.
Teleconferencing
Live Real-Time Translation in Teleconferencing
Architecture and product patterns for enterprise teleconferencing stacks.
Services
Fora Soft AI Integration Services
Our stack and a one-click path to scoping a real-time translation build.
Ready to ship real-time translation that actually feels real-time?
Real-time language translation in 2026 is a solved set of services with a hard set of integration problems. Buy turnkey if your use case is conferences and webinars; build on cloud APIs if it is in-product, multilingual, and customer-facing. Either way, the differentiator is not the model — it is the orchestrator, the glossary discipline, the partial-result UX, the observability, and the human-in-the-loop policy that keeps the feature live in regulated regions.
Fora Soft has shipped real-time speech and translation features into market research, sales-intelligence, telehealth-adjacent and enterprise video products at scale, and Agent Engineering is what lets us deliver in months rather than quarters. If that is the conversation you need, we are one call away.
Get a second opinion on your real-time translation plan
30 minutes with our speech-AI lead, a clear scope, and honest advice on build vs. buy.









.avif)
