


Key takeaways
• AI in software development is now a seven-stage discipline, not autocomplete. Requirements, architecture, code, review, test, deploy, and operate all run an AI step in 2026.
• Throughput went up, stability did not. The 2025 DORA report found AI’s link to delivery throughput flipped positive year-over-year, but its link to stability stayed negative. Governance is the difference.
• Two tools cover 90% of teams. GitHub Copilot as the baseline plus one agentic tool (Cursor or Claude Code) is $30–$40 per developer per month.
• A 50-engineer stack runs about $637k in year one — roughly 6.4% of a $10M engineering payroll, and the two governance hires cost more than the tools.
• Name an AI champion before you buy seats. EU AI Act high-risk duties, SOC 2 Type II, and license scanning are the 2026 procurement floor.
Why Fora Soft wrote this playbook
Most guides on AI in software development are written by people selling one tool. This one is written by an engineering team that has shipped production software since 2005, across 250+ projects, and now runs AI across every stage of the lifecycle for clients — and reports the throughput and stability numbers back to them every quarter. We have watched a $500k tool budget produce zero throughput lift because nobody owned governance. We have also cut a client’s change-failure rate below its pre-AI baseline in eight weeks. This is the checklist we hand engineering leaders who want the first outcome, not the second.
Our own engineers use Claude Code, Cursor, and GitHub Copilot in the IDE; Claude for architecture decision records and first-pass code review; Sealights and mabl for test engineering; and GitHub Actions with AI triage in CI. On our telemedicine work for CirrusMED and our e-learning platform work for BrainCert, the AI layer never touches a merge without a human gate in front of it. That distinction — AI drafts, a person approves — is the whole ballgame.
Want a 30-minute scoping call on your stack, tools, and rollout plan? Book time with our CEO Vadim. We’ll tell you where AI moves the needle in your SDLC and, just as usefully, where it doesn’t.
What “AI in software development” actually means in 2026
Short answer: an AI step now sits inside all seven stages of the software development lifecycle, not just the code editor. The 2023 wave was autocomplete — Copilot suggested a few lines, developers accepted them, productivity ticked up single digits. The 2026 reality is an order of magnitude bigger, running from the product-discovery call all the way to the on-call pager.
Here are the seven stages, plainly. Requirements: language models draft user stories from sales-call transcripts and Slack threads. Architecture: AI co-designs with humans, rendering C4 diagrams and running fitness functions. Code: agentic tools write multi-file changes with full-repo context. Review: AI critiques the pull request before a human does. Test: defect-prediction models skip low-risk tests while AI generates the rest. Deploy: AI-assisted canary analysis halts a bad rollout automatically. Operate: AI reconstructs incident timelines and suggests root causes.
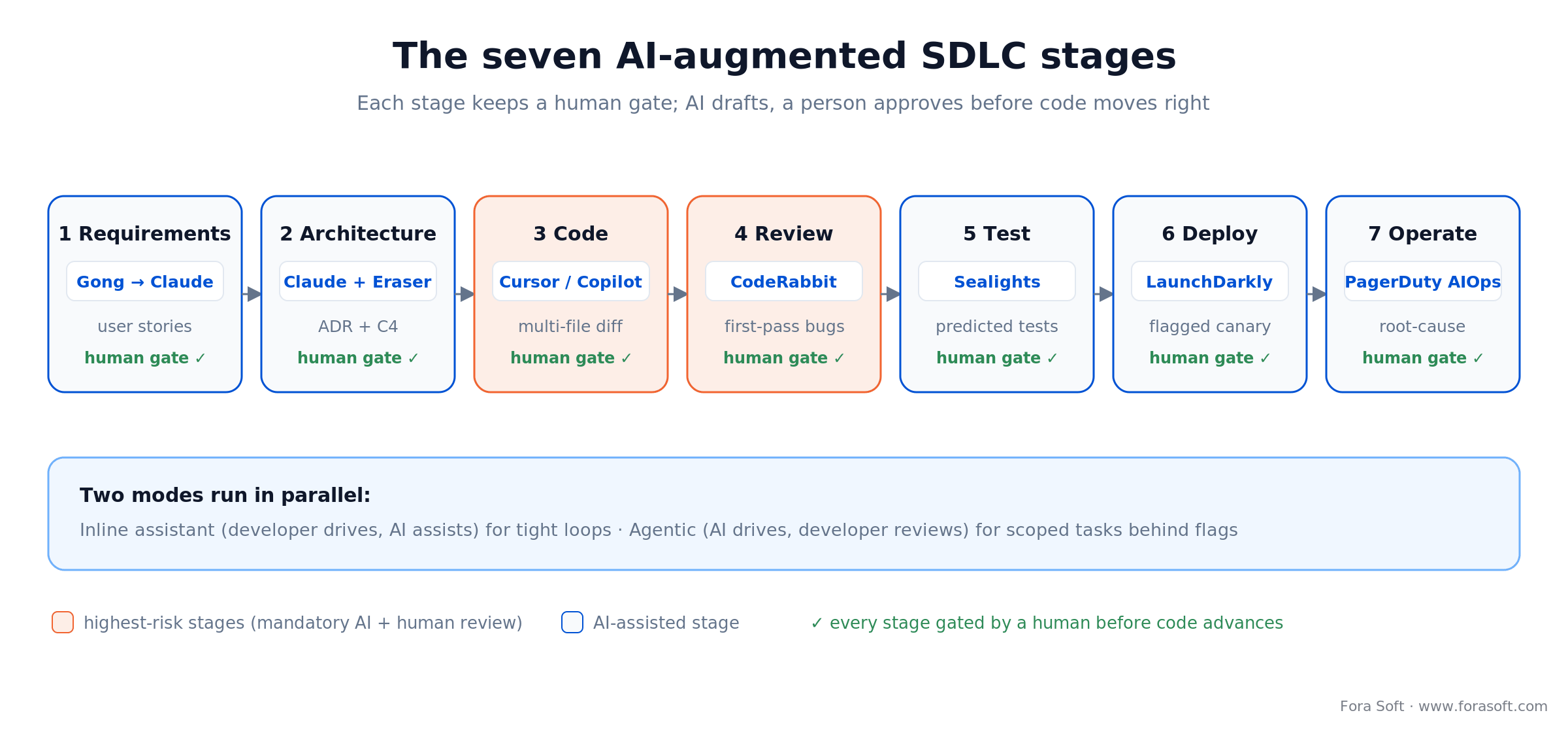
Figure 1. The seven stages of AI in software development. Code and review carry the highest risk, so both keep a mandatory AI-plus-human gate.
Inline assistant vs agentic AI — the two modes
Every tool on the market runs in one of two modes, and the winning teams use both on purpose. Inline assistant mode — the developer drives, AI assists — still dominates daily work: you type, it completes, you accept or reject in a tight loop. Agentic mode — the AI drives, the developer reviews — ships whole multi-file changes for a scoped task, then hands them back for review. At our more aggressive clients, agentic tools now produce 15–25% of merged code, all of it behind feature flags.
The rule we give teams: inline for tight-loop refinement, agents for isolated, well-specified tasks with a clear test to check against. Point an agent at a vague ticket in a tangled codebase and you get confident nonsense. Point it at “add pagination to this endpoint, here’s the test” and it earns its seat. Generative AI in software development is only as good as the boundary you draw around the task.
Market snapshot — adoption, spend, and DORA 2025
Adoption is effectively universal. The 2025 Stack Overflow Developer Survey put AI use (or planned use) at 84% of developers, up from 76% a year earlier, with 51% of professionals using it daily. The 2025 DORA report went higher, reporting roughly 90% AI adoption among the teams it studied. Whatever the exact figure, “are we using AI?” is a settled question; “are we using it well?” is not.
The most important 2026 finding is the reversal in the 2025 DORA report. In 2024, AI adoption correlated with lower delivery throughput and lower stability. In 2025, the throughput relationship flipped positive — teams got faster — but the stability relationship stayed negative. DORA’s own framing is that AI is an amplifier: strong teams with good tests, version control, and fast feedback got stronger, while shaky teams got shakier. Tools alone do not buy a DORA-elite outcome; process does.
On market share, the picture is a two-horse baseline plus a fast-moving agentic tier. GitHub Copilot has the widest installed base. Anthropic’s Claude models are the professional favorite — used by 45% of professional developers in the Stack Overflow 2025 data. Cursor leads the IDE-native agentic category, Windsurf wins on value, and Google Antigravity, OpenAI Codex, and Kiro make up the emerging tier.
The honest limits — where AI in software development still fails
Straight answer: AI is fast but not trustworthy on its own, and pretending otherwise is how stability craters. The same 2025 Stack Overflow survey that reported 84% adoption also found trust falling — only 29% of developers highly trust AI output, down 11 points year-over-year. The single biggest frustration, cited by 66%, is code that is “almost right, but not quite.” And 45% said debugging AI-generated code takes them longer than writing it themselves.
That is not an argument against AI. It is an argument for where you place it. AI shines on boilerplate, test scaffolding, first-pass review, and documentation — work with a cheap, fast way to check the answer. It struggles on novel algorithms, cross-service coordination, and anything where the correct answer is subtle and the failure is silent. The teams that win treat every AI output as a draft from a fast, confident junior who has never seen your production incidents.
Reach for agentic AI when: the task is scoped, the test exists, and a wrong answer is cheap to catch — add pagination, migrate a config, write the missing unit tests. Keep it on a leash for anything novel or silently failing.
The 2026 tool map — seven stages, sixty names
Here is the shortlist we actually reach for, stage by stage. You do not need all of it on day one — start with code authoring and review, add the rest as your rollout matures.
Stage 1 — Requirements and product discovery
Gong, Chorus, and Otter.ai capture calls; Linear AI, ClickUp AI, and Productboard AI draft stories; Claude and GPT handle open-ended synthesis; Dovetail organizes research. Budget $15–$40 per product manager per month, plus $20–$30 for the Linear or ClickUp AI add-on.
Stage 2 — Architecture and design
Eraser AI, Structurizr, and IcePanel render diagrams and C4 models; Infracost and Vantage estimate cloud spend; ArchUnit enforces fitness functions; Snyk, Socket, and Endor Labs guard the supply chain. Our companion AI in software architecture playbook goes deep on this layer.
Stage 3 — Code authoring
Claude Code (terminal-native agentic, $20 Pro to $200 Max), Cursor (IDE-native, $20 Pro to $200 Ultra, Business $40/user), GitHub Copilot (widest IDE coverage, $10 Pro / $39 Pro+, Business $19/seat), and Windsurf (best value, $20 Pro to $200 Max). Google Antigravity, OpenAI Codex, Kiro, JetBrains AI, Tabnine, Amazon Q Developer, and open-source Continue.dev round out the field. Most teams converge on Copilot plus one agentic tool.
Stage 4 — Code review
CodeRabbit ($12–$24 per developer per month), Graphite AI Review, GitHub Copilot’s bundled PR review, CodeScene, Codacy, SonarQube AI, Greptile, and Ellipsis.dev. A first-pass AI review on every pull request catches a meaningful share of issues before the human reviewer opens it — and stops rubber-stamping of large agentic diffs.
Stage 5 — Test engineering
mabl, Testim, and Applitools author UI tests; Sealights, Launchable, and Predictive Test Selection cut test runtime by skipping low-risk tests; Diffblue Cover and Qodo generate unit tests. Our AI-driven testing guide and AI in QA buyer’s guide cover this stage in depth.
Stage 6 — Deploy and release
LaunchDarkly, Statsig, Argo Rollouts, and GitHub Actions with AI triage. AI-assisted canary analysis is 2026 table stakes: the system watches error rate, latency, and revenue metrics during a progressive rollout and halts it the moment a metric deviates.
Stage 7 — Operate and incident response
Datadog Bits AI, PagerDuty AIOps, New Relic AI, Splunk ITSI, Rootly AI, and incident.io AI. Mean-time-to-resolution drops sharply when AI correlates alert storms, reconstructs the timeline, and drafts the post-incident writeup for a human to sign off.
Not sure which two tools to standardize on?
We’ll benchmark Copilot, Cursor, and Claude Code against your actual repos and hand you a one-page recommendation.
Comparison matrix — which coding tool for which team
Code authoring is the single highest-impact category, so here is the 2026 trade-off table for the four tools that matter, with 2026 list prices.
| Dimension | GitHub Copilot | Cursor | Claude Code | Windsurf |
|---|---|---|---|---|
| Interface | Plugin (VS Code / JetBrains / Neovim) | Forked IDE | Terminal / CLI | Forked IDE |
| Price / dev / mo | $10–$39 ($19 Business) | $20–$200 ($40 Business) | $20–$200 ($25 Team) | $20–$200 |
| Strongest at | Daily autocomplete, compliance | Multi-file agentic edits | Terminal agents, CI scripts | Cascade workflows, value |
| Enterprise compliance | SOC 2, FedRAMP path, BYOK | SOC 2, privacy mode | SOC 2, BYOK | SOC 2 |
| IDE lock-in | None | High (forked VS Code) | None (terminal) | High (forked VS Code) |
| Best for | Large-enterprise baseline | Startups, product teams | Power users, platform eng | Cost-conscious teams |

Figure 2. The same four tools scored at a glance. Copilot wins on compliance and portability; Cursor and Claude Code win on agentic work.
The recommendation we give roughly 90% of clients: GitHub Copilot Business ($19/dev/mo) as the baseline, plus Claude Code or Cursor ($20–$25/dev/mo) for the power users. That is $30–$40 per developer per month for the most productive configuration we have measured — and it keeps everyone on a portable plugin while letting the heavy hitters go agentic.
Reach for GitHub Copilot when: your developers span four or more IDEs, compliance is the gating concern, or you want one portable baseline everyone shares. It ships everywhere and has the strongest enterprise story.
Reach for Cursor when: your team is unified on VS Code and wants the tightest multi-file agentic experience in a familiar editor, and you can live with the fork lock-in.
Reach for Claude Code when: your power users live in the terminal, you want agents wired into CI scripts, and you value staying IDE-agnostic. It’s the platform-engineer’s pick.
Reach for Windsurf when: budget is the hard constraint and you still want a real agentic IDE. Its Cascade workflows deliver most of Cursor’s value at the low end of the price band.
Reference architecture — the seven AI-augmented stages
This is how the seven stages wire together in a production SDLC that keeps stability intact.
Stage 1 — Requirements. Customer calls record in Gong; Claude drafts weekly summaries into Linear as user stories with acceptance criteria. A product manager reviews, approves, and tags priority.
Stage 2 — Architecture. A new feature triggers an architecture decision record. Claude drafts the trade-offs, Eraser renders the C4 diagram, Infracost estimates the cloud-spend delta, and Snyk scans the proposed dependencies.
Stage 3 — Code. The developer opens the ticket in Cursor or Claude Code, the agent reads roughly 200k tokens of repo context, proposes a plan, writes the multi-file change, and runs tests locally. Inline Copilot keeps the small-edit loop tight during manual refinement.
Stage 4 — Review. The pull request opens. CodeRabbit or Graphite scans first and posts structured comments on bugs, security, and style. The human reviewer then spends their attention on architecture and product semantics instead of typos.
Stage 5 — Test. CI runs only the tests predicted relevant (Launchable or Sealights), saving a large share of runtime minutes. AI-generated Playwright tests cover new UI flows, and mutation testing gates the merge.
Stage 6 — Deploy. A feature flag ships the change to 1% of traffic; LaunchDarkly watches error rate, latency, and revenue; auto-rollback fires on anomaly. The rollout progresses to 5%, 25%, then 100% over 2–24 hours.
Stage 7 — Operate. PagerDuty AIOps correlates alert storms, Rootly drafts the incident timeline, Claude summarizes the post-mortem and files follow-up Linear tickets, and Datadog Bits AI answers on-call questions about service dependencies. A human owns every decision; AI owns the typing.
Cost model — what a 50-engineer org actually spends
Fifty engineers, five product managers, a modest enterprise-compliance bar. Here is the annual spend at 2026 list prices, layer by layer.
| Layer | Stack | Year-1 cost |
|---|---|---|
| Requirements | Gong + Linear AI | $18,000 |
| Architecture | Eraser + Infracost + Snyk | $36,000 |
| Code authoring | Copilot Business + Claude Code (50 devs) | $23,400 |
| Code review | CodeRabbit Pro | $14,400 |
| Test engineering | Sealights + Diffblue Cover | $95,000 |
| Deploy | LaunchDarkly + Argo | $48,000 |
| Operate | Datadog Bits AI + Rootly | $62,000 |
| Tool subtotal | $296,800 | |
| People (AI champion + DevEx lead) | 2 senior hires | $340,000 |
| Year-1 total | $636,800 | |
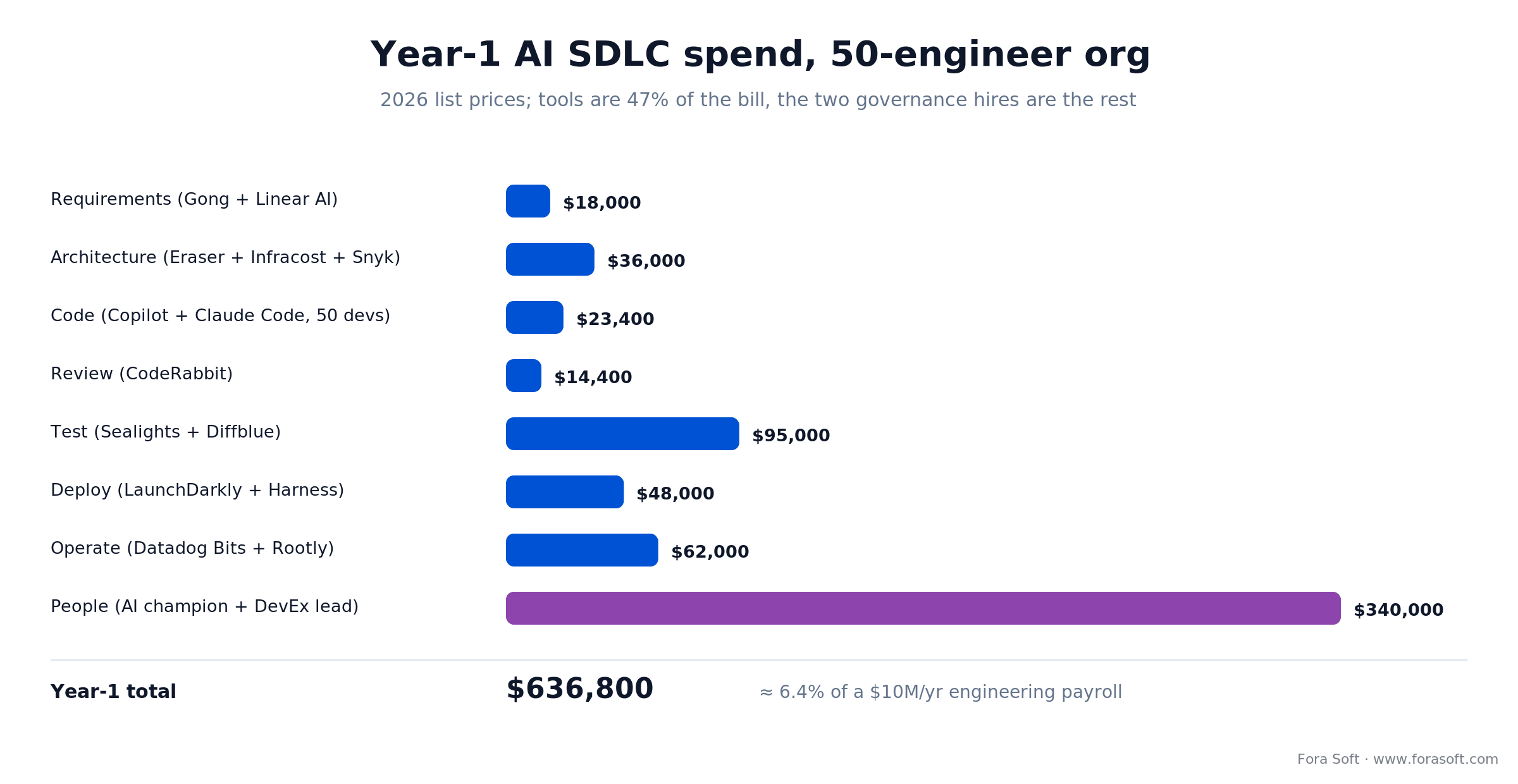
Figure 3. The bill in one picture. Tools are the smaller half; the two governance hires are where the money goes — and where the results come from.
Do the arithmetic on the payoff. At 50 engineers loaded at $200k each, the fleet costs $10M a year. The AI program is $636,800, or 6.4% of payroll. If it lifts effective output even 15% — the low end of what a governed rollout delivers — that is $1.5M of capacity against a $637k spend. The risk is never the dollars; it is the stability dip, which is a people-and-process problem, not a budget one.
Mini case — the stability dip a client fixed in eight weeks
A 40-engineer SaaS client rolled Cursor out to the whole team in late 2025 with no governance change. The first month looked great and then didn’t: throughput up 31%, but change-failure rate jumped from 8% to 19%, with two customer-facing incidents traced directly to AI-generated code that had merged without a real review.
We ran an eight-week fix. Weeks 1–2: audit, then CodeRabbit installed as a mandatory first-pass AI reviewer. Week 3: feature-flag gating required for any AI-authored path over 30 lines. Week 4: LaunchDarkly progressive rollout wired to error rate. Weeks 5–6: training and a brown-bag series on prompt and review discipline. Weeks 7–8: metrics review and a published governance doc.
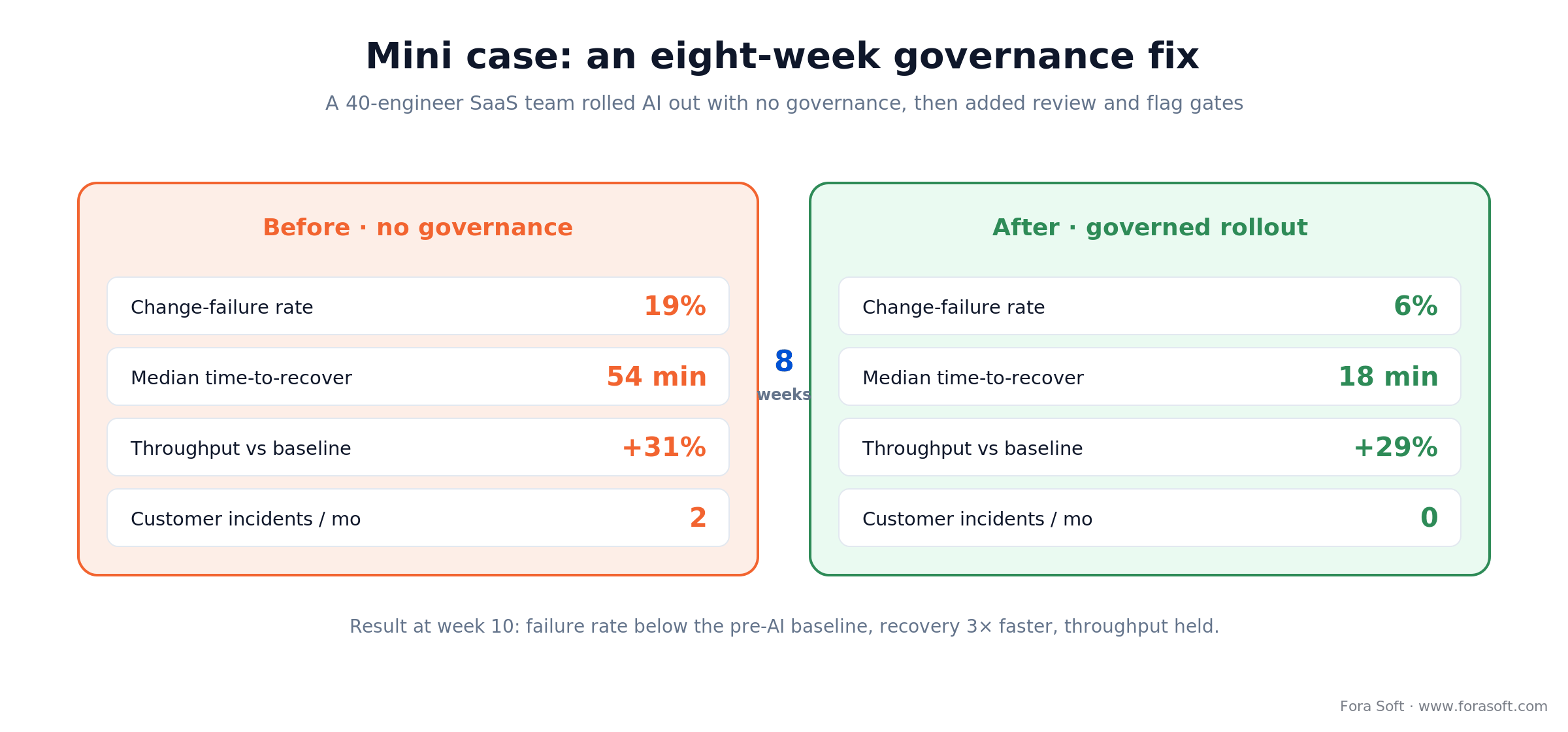
Figure 4. The same team, eight weeks apart. Governance recovered stability without giving back the throughput gain.
By week 10, change-failure rate was back to 6% — below the pre-AI baseline — and throughput held at 29%, barely off its 31% peak. Time-to-recover for the two incident categories fell from a median of 54 minutes to 18 with Rootly in the loop. Want a similar assessment of your own rollout? Grab a 30-minute slot and we’ll read your DORA numbers together.
Compliance — EU AI Act, SOC 2, data residency, IP
EU AI Act. General-purpose developer tools are limited-risk (transparency and disclosure obligations, which apply from 2 August 2026). The risk transfers downstream: if your AI writes code that ships into a high-risk system — recruitment, credit, education, or critical infrastructure under Annex III — the deployer inherits the high-risk duties in Articles 6–15 (risk management, human oversight, traceability). After the Digital Omnibus package (Council green-lit 29 June 2026), those standalone high-risk obligations now apply from 2 December 2027, and AI embedded in regulated products under Annex I from 2 August 2028 — a real deadline shift from the original August 2026 date, and one worth putting in your roadmap correctly.
SOC 2 Type II. Copilot Business, Cursor Business, Claude Code Team, and Windsurf Team all ship SOC 2 Type II reports. Require them in procurement; do not accept a marketing page in place of the report.
Data residency and “no-training.” Every major tool in 2026 offers a contractual “your code is not used for model training” guarantee at the Business or Enterprise tier. Verify the exact clause — a handful still train on free-tier usage by default.
Intellectual property. Updated 2025 US Copyright Office guidance treats purely AI-generated code as uncopyrightable absent substantial human creative input. For most functional commercial code this is a non-issue; for novel creative work (a game engine, a proprietary algorithm), document the human authorship steps.
License contamination. Turn on GitHub Copilot’s “code referencing” feature, which flags suggestions that closely match public code under a non-permissive license. Do not ship AI code without scanning for copyleft (GPL, AGPL) contamination through an SBOM tool in CI.
ISO/IEC 42001. The 2023 AI management-system standard is turning up in 2026 enterprise RFPs. Start mapping controls now — they overlap heavily with the ISO 27001 program you likely already run.
Shipping AI code into a regulated product?
We build AI features under HIPAA, SOC 2, and EU AI Act constraints every quarter — and we’ll map your obligations to your SDLC.
A decision framework — pick the stack in five questions
Question 1 — What is your DORA baseline? If you sit at low or medium DORA performance today, AI will widen the gap between your strong and weak teams. Fix trunk-based development, CI discipline, and observability first. If you are high or elite, AI accelerates you cleanly.
Question 2 — What is your compliance bar? Limited-risk commercial SaaS: any major tool. Regulated (FinTech, HealthTech, GovTech): pin to Copilot Business, Cursor Business, or Claude Code Team with BYOK and SOC 2 Type II. High-risk under the EU AI Act: document human oversight per Article 14.
Question 3 — How unified are your IDEs? One editor across the team: Cursor or Windsurf gives the tightest agentic loop. Four or more editors in play: Copilot (it ships in everything) plus Claude Code in the terminal covers everyone.
Question 4 — What is your budget ceiling? $10/dev/mo: Copilot alone. $30: Copilot plus Claude Code. $80+: the full seven-stage stack. Start at $30/dev/mo and scale up after three months only if the data supports it.
Question 5 — Who owns governance? Name one AI champion (a staff or principal engineer) and one DevEx lead. No champion, no rollout. We have watched a $500k budget evaporate with no throughput lift because nobody owned the rules, the training, and the metrics.
Five pitfalls that kill AI SDLC rollouts
1. Rolling out tools without governance. Buy seats, announce, walk away. Throughput blips up, stability craters, and six months later the CFO asks where the productivity went. Assign a named AI champion on day one.
2. Skipping AI code review. Agentic tools ship 40–200 line diffs in a single pull request, and tired human reviewers skim them. AI review catches the bugs a rushed human misses. Without it, change-failure rate climbs — exactly what the mini case above shows.
3. No feature-flag gate. AI code should ship behind flags for its first 30 days. If the error budget blows, flip the flag in seconds. Teams that skip this take hours to recover from an AI-introduced regression instead of moments.
4. Measuring only throughput. If your only metric is lines-per-week or PR count, you reward AI noise and punish stable engineering. Measure the DORA four — deploy frequency, lead time, change-failure rate, MTTR — plus a quality metric like escape rate.
5. Training debt. The spread between a skilled AI-tool user and an unskilled one is wide. Teams that run weekly prompt-discipline sessions, share prompt libraries, and record demos pull ahead fast. Teams that don’t stay stuck at a 15% lift while their competitors hit 45%.
KPIs — what to measure on day one
DORA four. Deploy frequency, lead time for change, change-failure rate, MTTR. Elite looks like multiple deploys a day, under a day of lead time, under 5% change-failure rate, under an hour to recover. Baseline these before AI; measure weekly after.
AI acceptance rate. The share of suggestions or agentic changes your team keeps. Watch the trend, not the absolute number — a rate below 50% usually means prompting discipline or tool fit is off, not that the tool is bad.
Escape rate. Defects reaching production per 1,000 lines shipped. Expect a short-term rise under AI; target a 20–30% cut against your pre-AI baseline by month six of a governed rollout.
AI-authored share. The percent of merged lines produced by AI, tracked through Git blame and tool telemetry. Healthy mid-market orgs land at 30–55%. Above 70% without strong review is a stability red flag.
Developer satisfaction. A quarterly seven-point survey. AI should raise it. If satisfaction drops, you have a tool-fit or workflow problem worth chasing before you scale further.
Industries shipping real value in 2026
B2B SaaS. Greenfield product teams ship 35–50% faster on a governed Cursor-plus-Copilot stack. Multi-product platform teams see smaller lifts (15–25%) because their complexity lives in coordination, not typing.
FinTech. Copilot Business with “block public code” plus Sealights defect prediction pulls release cycles from biweekly toward daily. Compliance teams value the SOC 2 and SOC 1 audit trails.
HealthTech. Heavier review, slower adoption. HIPAA and the EU AI Act push teams toward BYOK or self-hosted setups. The biggest wins show up in test generation and documentation, not greenfield code — which matches what we see building for telemedicine clients like CirrusMED.
Media, streaming, and e-learning. The domains we know best. AI accelerates CRUD, admin tooling, and cross-platform work; the hard real-time video and encoding paths stay human craft. Our AI for video engineering course covers where the line falls.
Government and defense. Slowest to adopt, for good reasons. When they do, Copilot on a FedRAMP path and self-hosted Continue.dev over open-weight models are the winning patterns.
Build vs buy vs adapt
Buy. Roughly 95% of teams should buy. Commercial vendors invest more in models and tooling than any single engineering org can match. Lock procurement down, pick the stack above, and spend your energy on governance.
Adapt. A minority build thin internal wrappers around commercial models: custom context retrieval, domain-specific prompt libraries, an org-specific evaluation suite. Worth it once you have 200+ engineers and enough proprietary context to justify a $500k platform investment.
Build. Self-hosting open-weight models (Llama, Mistral, DeepSeek Coder) on your own GPUs makes sense only for government, defense, or hard sovereignty requirements. Budget $500k–$2M of CapEx and a platform team to match.
Reach for build-your-own when: your data legally cannot leave your network, or you have 200+ engineers and proprietary context worth a dedicated platform. Everyone else buys the stack and invests the savings in governance and training.
When not to adopt AI in the SDLC (yet)
Weak CI/CD foundation. Without a reliable test suite and fast CI, AI generates more noise than signal. Fix CI first — it is the control system DORA says AI amplifies.
No code-review discipline. If pull requests land today with a cursory glance, AI turns the volume up and the quality down. Introduce real two-reviewer discipline before you scale AI authoring.
Classified work with no self-hosted option. If your data cannot leave the network, the buy and adapt paths do not apply. Wait for self-hosted open-weight coding models to clear your quality bar, or fund a build.
Tiny team, high novelty. A three-person team writing a genuinely new numerical-methods library will spend more time rejecting AI suggestions than writing the code. Revisit in six months as model coverage of the domain improves.
A 12-week deployment playbook
Weeks 1–2 — baseline. Collect the DORA four, escape rate, and developer satisfaction. Pick the AI champion and DevEx lead. Sign procurement.
Weeks 3–4 — pilot one team. Six to eight engineers, one product area, Copilot plus Claude Code, weekly office hours. Measure acceptance rate and DORA.
Weeks 5–6 — governance artifacts. Write the AI code-review policy, the feature-flag policy, the prompt library, and the training materials. Install CodeRabbit.
Weeks 7–8 — expand to half the org. Onboard, measure, clear blockers. Add defect prediction (Sealights) and release intelligence (Argo Rollouts).
Weeks 9–10 — full rollout. All engineers and product managers, complete stack live, operate-stage tools (Rootly, Datadog Bits) online.
Weeks 11–12 — review and tune. Formal DORA and escape-rate readout, adjust the tool mix, publish the governance doc, and schedule quarterly reviews.
Want this delivered in 12 weeks?
Fora Soft runs fixed-scope AI SDLC rollouts for mid-market and enterprise teams — tools, governance, training, and dashboards. We can start next week.
FAQ
Does AI really make developers faster?
On throughput, yes: the 2025 DORA report found AI’s relationship with delivery throughput turned positive year-over-year. On stability, no — that relationship stayed negative. And 45% of developers in the Stack Overflow 2025 survey said debugging AI code takes longer than writing it. The speed is real but conditional on review and feature-flag discipline.
Which single tool should I pick if I can only have one?
GitHub Copilot. Widest IDE coverage, strongest enterprise compliance story, and cheapest at $10–$19 per developer per month. It won’t give you agentic power, but it moves your baseline developer experience forward without lock-in.
How do you use AI in software development without hurting quality?
Put a gate in front of every merge: mandatory AI first-pass review, mandatory human review, and feature-flag gating for the first 30 days. Scope agentic tasks tightly and give the agent a test to check against. The teams that keep quality high never let AI code merge unreviewed.
Will AI replace software engineers?
Not in 2026. AI absorbs boilerplate, accelerates test writing, shortens review cycles, and drafts documentation. Architecture, product judgment, cross-team coordination, and incident response under pressure still need humans. Engineers who pair well with AI out-produce those who don’t — that is the actual shift.
Is it safe to let agents write production code?
Yes, behind a governance wall: mandatory AI first-pass review, mandatory human review before merge, feature-flag gating for 30 days, and full telemetry. Without those controls, agentic code is a stability risk, as the mini case in this guide shows.
What is the EU AI Act risk for my dev tools?
The tools themselves are limited-risk (transparency duties from 2 August 2026). The risk transfers: if your tool ships code into a high-risk Annex III system, the deployer bears the high-risk obligations, now applying from 2 December 2027 after the Digital Omnibus deferral. Document human oversight per Article 14 in your SDLC.
How do I prevent license contamination from AI code?
Turn on Copilot’s “block public code” and “code referencing” features, and run an SBOM scanner (Snyk or Socket) in CI. Reject any suggestion that flags against copyleft licenses (GPL, AGPL) unless your product is also copyleft.
How does Fora Soft run an SDLC transformation?
A 12-week, fixed-scope engagement. We handle tool selection, governance artifacts, CodeRabbit and feature-flag wiring, training, and metrics dashboards. Book a scoping call and we’ll size it to your team and compliance exposure.
Read next
AI architecture
AI in Software Architecture Design
The stage-two layer in depth: tools, reference architecture, and a 2026 cost model.
AI QA
AI in Quality Assurance: A Buyer’s Guide
The nine-category QA stack, its cost model, and the compliance duties that come with it.
AI testing
AI in Software Testing Without Tech Debt
How we use AI for QA on the test stage without piling up maintenance debt.
Services
AI Integration Services by Fora Soft
Your engineering partner for AI-assisted SDLC rollouts, review, and release intelligence.
To sum up
AI in software development is the 2026 default, not a side bet: seven stages, two modes, and a governance layer that decides whether you get the upside. Throughput comes cheaply now; stability comes only from review and feature flags. Pick the right two tools, name an AI champion, measure the DORA four plus escape rate, and you sidestep the stability trap that snared early adopters.
And get the compliance dates right — high-risk EU AI Act duties now land in December 2027, not August 2026. Want to run the rollout in twelve weeks with the numbers watched from day one? Book a 30-minute scoping call with Vadim and we’ll map your DORA baseline, compliance bar, and tool mix to a concrete plan.
Ready to make AI in your SDLC actually pay off?
We’ll audit your stack, show where AI moves the needle, and hand you a 12-week rollout plan — the first call is free.








