



Podcast accessibility stopped being an ethical nice-to-have. Since 28 June 2025 accessible podcasts are a legal requirement across the EU under the European Accessibility Act, and from 24 April 2026 US public entities above 50,000 population are bound under the revised ADA Title II rule. This playbook is how Fora Soft engineers ship production-grade accessibility into podcast and audio platforms: the ASR and enrichment stack, the Podcasting 2.0 namespace, the compliance matrix, the real cost per episode, and the 10-to-14-week rollout that clears an audit.
Key takeaways
• Accessibility is compliance-driven in 2026. The EAA (live 28 June 2025), ADA Title II (24 April 2026 for entities above 50k), WCAG 2.2 AA, CVAA, and the EU AI Act all now touch podcast products.
• ASR has settled into three serious options. Deepgram Nova-3, AssemblyAI (Universal-2 and the newer Slam-1), and OpenAI Whisper v3. Lab WER of 5-8% is marketing; real podcast audio lands at 12-20% once jargon and multiple speakers show up.
• Podcasting 2.0 is the delivery layer, and Spotify finally joined it. As of late 2025 Spotify renders RSS-linked <podcast:transcript> files, so three of the five biggest apps now show creator transcripts. Ship your own; do not lean on auto-generation.
• The full suite costs $0.80-$2.30 per episode hour. That covers ASR, diarization, three-language translation, AI summaries, and chapters. Transcripts also add crawlable text that pulls organic traffic.
• Ship transcripts first, dubs second, audio description third. Most teams under-build the web player's screen-reader and keyboard support, and that is exactly where the auditor writes the finding.
Why Fora Soft wrote this playbook
Fora Soft has built audio and video streaming products since 2005, 250+ shipped projects across 21 years. Between 2024 and 2026 we added accessibility layers to three audio-first products: an AI learning platform (Scholarly, 15,000 users) that serves lectures as podcasts with synchronized transcripts, a corporate-training platform under EAA review, and a multi-language interview show that now ships in nine languages with consent-based voice preservation. Each one broke in a different place, and each one taught us something the vendor docs skip.
We also ship faster than we used to. Our delivery runs on Agent Engineering: Claude Sonnet 4.6 pair-programs our senior engineers on every story, which cuts time-to-first-production-deploy by roughly 30-45% on recent work. Accessibility is a good fit for that model. It is a long catalog of small, high-certainty changes, alt text, ARIA roles, focus management, keyboard order, where machine-assisted refactoring is reliable and cheap.
Scoping a podcast accessibility rollout?
We audit your ingest pipeline, transcript delivery, and web player against EAA, ADA Title II, and WCAG 2.2, then send back a written teardown with priorities.
What podcast accessibility actually means in 2026
Podcast accessibility is not one feature. It is a stack of eight listener-visible capabilities plus three invisible delivery capabilities, and all of them have to be right for the product to clear WCAG 2.2 AA and EAA baseline conformance. Miss the invisible layer and your visible features never reach the apps that render them.
Visible to every listener: synchronized transcripts, chapter markers, variable-speed playback (0.25× to 3×), translated transcripts, dubbed audio, episode summaries and key-point extraction, search within an episode, and search across the whole catalog.
Visible to the assistive-tech user: a screen-reader-compatible web player, keyboard-only navigation, font-size and contrast controls, correct focus management, captions for video podcasts, and audio descriptions for visual-only segments.
Invisible to both, but required: the Podcasting 2.0 namespace in the RSS feed, a structured transcript format (WebVTT or SRT, plus JSON for semantic search), and a delivery layer of CDN-hosted transcript files that Apple Podcasts, Spotify, Fountain, Podverse, and Overcast can consume.

Figure 1. The four-layer accessibility stack. Each layer has a job and a place where audits fail if you skip it.
The numbers driving the category
Podcasts are not a niche. About 165 million Americans aged 12+ listen monthly (Edison Research, Infinite Dial 2026), the global market runs near $39.6 billion (Grand View Research, 2026), and vision-disabled listeners over-index on podcast consumption. Accessibility widens an already large audience and, because transcripts add crawlable text, it feeds search at the same time.
| Metric | Value | Source (year) |
|---|---|---|
| Global podcast market | $39.6B | Grand View Research (2026) |
| US monthly listeners (12+) | ~165M (55%) | Edison Research (2026) |
| Apple auto-transcripts issued | 125M+ episodes, 13 languages | Apple Newsroom (2024-25) |
| US adults with hearing trouble | ~37.5M | CDC / NIDCD (2025) |
| Big-5 apps rendering RSS transcripts | 3 of 5 (Apple, Spotify, Pocket Casts) | Podnews (2026) |
| Podcasters using AI transcription | ~70% | Industry surveys (2026) |
The read is simple. The audience is huge, roughly one in five weekly listeners reports a disability, and the compliance clock is running. The question moved from “should we” to “how fast, and what does an audit actually check.”
The four-layer reference stack
Every accessible podcast system we have shipped decomposes into four layers. Treat them as separate services with clean contracts between them, and you can swap any one, a better ASR model, a cheaper CDN, without rebuilding the rest.
| Layer | Job | 2026 representative tools |
|---|---|---|
| 1. Ingest + ASR | Speech to word-level timestamps | Deepgram Nova-3, AssemblyAI Universal-2 / Slam-1, Whisper v3 / v3-turbo, NVIDIA Parakeet TDT |
| 2. Enrichment | Diarization, chapters, summary, translation, dubbing | pyannote 3.1, WhisperX, ElevenLabs dubbing, Respeecher, DeepL, Claude Sonnet 4.6 |
| 3. Delivery | Serve transcripts + metadata to apps and web | Cloudflare R2, Backblaze B2, S3, Podcasting 2.0 RSS, WebVTT / SRT, HLS for video |
| 4. Web player + search | Render accessible UI + semantic navigation | WCAG 2.2 React player, ARIA live regions, Pinecone / Weaviate / Qdrant vector search |
Reach for the player-first budget when: you have finite money and a live deadline. A 92%-accurate transcript in a WCAG-compliant synchronized reader beats a 98%-accurate transcript trapped behind broken keyboard navigation. Spend on the player, then on the pipeline.
ASR models: which one for which podcast
Which ASR model should you pick? For a batch podcast pipeline, Deepgram Nova-3 or AssemblyAI wins on the quality-to-cost curve; Whisper v3 wins only when you must self-host. The vendor WER numbers below are clean-read benchmarks. Budget against the real-world column, which is what your listeners and your auditor will actually see.
| Model | Lab WER | Real podcast WER | Where it wins / breaks |
|---|---|---|---|
| Deepgram Nova-3 | ~5% | 12-15% | Wins: latency, accents, code-switching. Breaks: fewer self-host options |
| AssemblyAI Universal-2 | ~9% | 15-18% | Wins: cheapest at scale, strong alphanumerics. Breaks: English-first |
| AssemblyAI Slam-1 | ~8% | 13-16% | Wins: prompt-steerable, understands context (late 2025). Breaks: newer, pricier |
| OpenAI Whisper v3 | ~7% | 13-20% | Wins: 99 languages, open-weight, self-host. Breaks: no built-in diarization |
| NVIDIA Parakeet TDT | ~6% | 12-16% | Wins: per-GPU throughput on H100/H200. Breaks: English only |
| whisper.cpp (tiny/base) | 12-14% | 18-22% | Wins: on-device, zero cloud cost. Breaks: accuracy on hard audio |
Our default: Deepgram Nova-3 for quality plus latency plus accents, or AssemblyAI Universal-2 when cost at scale dominates and the show is English-first. Slam-1 earns its price when you need to steer the model with a prompt (custom vocabulary, speaker roles, domain terms). Whisper v3 is the answer only when legal mandates on-prem processing, or the language sits outside the big vendors' strongest tier.
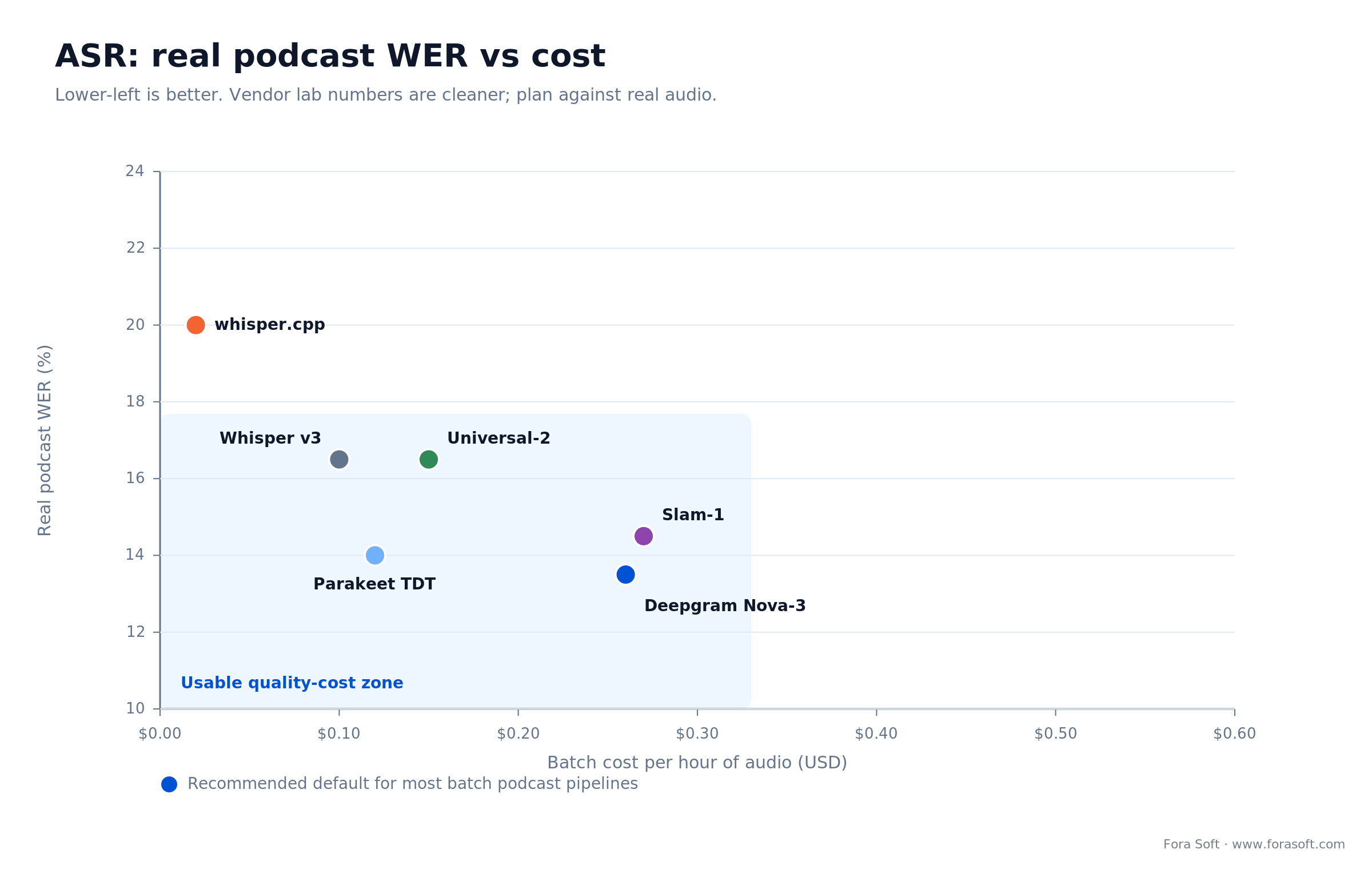
Figure 2. Real podcast WER against batch cost per hour. The bottom-left zone is where most shows should live.
Diarization, translation, and dubbing: the enrichment layer
Diarization: who spoke when
Diarization is the second-hardest problem after transcription itself. pyannote 3.1 lands near 11% DER on VoxConverse (clean two-speaker audio) and about 20% on DIHARD III (overlapping, many speakers). Deepgram and AssemblyAI ship integrated diarization that handles two-to-four-speaker conversations well. Above five speakers, error climbs fast. If your show is a panel, budget for manual correction of speaker labels on roughly 10% of turns.
Translation, dubbing, chapters
Translation. DeepL and Google Cloud Translate handle major European and East-Asian languages with BLEU above 40 on formal speech. Colloquial and idiomatic speech drops that by 15-20 points. For translated transcripts in the web player, that quality is fine. For dubbed audio, get a native speaker to review before publish.
Dubbing. ElevenLabs dubs into around 32 languages with timing and tone preservation; Respeecher and Resemble AI offer consent-based voice preservation, the speaker's own voice in another language. Consent is not optional. Under EU AI Act Article 50, from 2 August 2026 dubbed content that uses voice cloning must be disclosed as AI-generated, with a machine-readable marking transition running to 2 December 2026. For the deeper audio pipeline background, see our audio-for-video engineering guide.
Chapters and summaries. Claude Sonnet 4.6 or Gemini 2.5 Pro, given the transcript and a structured-output prompt, returns a clean chapter list (title, start_ms, summary) plus a 120-word abstract. Cost per episode: $0.10-$0.30 for one to two hours of audio.
Reach for voice cloning when: the speaker signed a documented consent form and you have the Article 50 disclosure wired into the player. Skip it otherwise; a well-cast human dub carries less legal risk than an undocumented clone.
Podcasting 2.0: the delivery standard
The Podcasting 2.0 namespace is the RSS-level standard for accessibility metadata. If you ship a podcast product in 2026 without at least <podcast:transcript> and <podcast:chapters>, you are leaving capability on the table that Apple Podcasts, Spotify, Fountain, Podverse, Podcast Addict, and Overcast already render natively.
| Namespace tag | Purpose | App support |
|---|---|---|
| <podcast:transcript> | VTT / SRT / JSON transcript reference with language tag | Apple, Spotify, Fountain, Podverse, Podcast Addict, Overcast |
| <podcast:chapters> | JSON chapter file: start_time, title, optional image | Most Podcasting 2.0 apps, Apple Podcasts |
| <podcast:person> | Speaker metadata: name, role, image, link | Fountain, Podverse, Podcast Guru |
| <podcast:alternateEnclosure> | Audio-description track, translated dub, alternate bitrate | Fountain, Podverse, custom players |
| <itunes:transcript> | Apple's parallel tag, VTT / SRT only | Apple Podcasts |
Apple Podcasts auto-generates transcripts (125M+ episodes across 13 languages) but accepts creator-provided VTT and SRT through <itunes:transcript> or <podcast:transcript>. The creator version overrides the auto one, so always ship your own when quality matters.
Spotify changed the game in late 2025. It now supports the Podcasting 2.0 <podcast:transcript> tag, displays RSS-linked creator transcripts in-app, and lets creators download, edit, and re-upload them. That closes the single largest platform gap of the last three years. The old advice, “Spotify won't take your transcript, plan around it,” is out of date; the new advice is to serve one clean VTT per episode and let Apple and Spotify both pick it up.
Compliance: what binds in 2026
| Framework | Scope | Key 2026 requirement |
|---|---|---|
| European Accessibility Act | EU podcast / streaming / e-book / audiobook services | Live 28 Jun 2025. Per-country penalties (~€60k to ~€900k, up to ~€3M); references WCAG 2.1 AA, EN 301 549 |
| ADA Title II (DOJ 2024 rule) | US state + local government web, mobile, audio, video | Above 50k pop: 24 Apr 2026. Below 50k: 26 Apr 2027. WCAG 2.1 AA |
| WCAG 2.2 (W3C, Oct 2023) | All web content, podcast web players | 9 new criteria: focus-not-obscured, 24×24 target size, dragging alternatives, consistent help |
| Section 508 | US federal agencies and their vendors | Aligns with WCAG 2.0 AA today; 2.2 AA review under way |
| CVAA + FCC IP captions | Video podcasts distributed over IP | Closed captions required; quality rules on accuracy, sync, completeness, placement |
| EU AI Act Article 50 | AI voice cloning, dubbed audio, synthetic speech | Disclosure + machine-readable marking from 2 Aug 2026; marking transition to 2 Dec 2026 |
One honest note on enforcement, because the scare numbers get thrown around loosely. As of mid-2026 there are no confirmed fines yet levied specifically under national EAA laws. What has happened is real, though: the first EAA lawsuits were filed in France in November 2025, and French regulator DGCCRF sent formal enforcement notices to several large retailers over keyboard-navigation and alt-text failures. Enforcement is ramping, not theoretical. Ship conformance now and you stay off that list.
The shortcut we use: write a one-page Accessibility Conformance Report (ACR / VPAT 2.5) mapping the product to WCAG 2.2 AA, Section 508, and EN 301 549. Auditors and procurement teams read that first. Ship it with the product, not in response to a complaint, and government and enterprise deals clear faster.
Not sure which regulations bind your product?
Send us your listener geography and content type. We map it to EAA, ADA Title II, CVAA, and the EU AI Act, and tell you what an audit will check first.
Cost model: per episode and per catalog
What does the full accessibility suite actually cost per hour of audio? Between $0.80 and $2.30, depending on how many languages you dub. Here is the line-by-line, using batch (pre-recorded) rates, which is the right mode for a podcast that is not live.
| Line item | Per hour of audio |
|---|---|
| ASR (AssemblyAI Universal-2) | $0.15 |
| ASR (Deepgram Nova-3, batch) | ~$0.26 (streaming ~$0.46) |
| Diarization (cloud tier) | +$0.02-$0.10 |
| Translation + dubbing (3 languages) | $0.50-$1.50 |
| Chapters + summary (Claude / Gemini) | $0.10-$0.30 |
| CDN + storage (R2 / B2) | <$0.02 |
| Total per hour of audio | $0.80-$2.30 |
Work it through. A show that produces 40 hours a month, transcribed and enriched with three-language dubs, runs 40 × $2.00 ≈ $80 per month in API and delivery cost. A network of 200 shows at the same cadence: 200 × $80 ≈ $16,000 per month. Strip the dubs and keep transcripts plus chapters, and the per-hour cost falls under $0.50, so the same 40-hour show drops to about $20 a month. Against a per-country EAA exposure measured in six figures, this is one of the cheapest compliance investments a platform makes.

Figure 3. Where the money goes per hour of audio. Dubbing dominates; transcripts alone are nearly free.
Architecture: the pipeline we ship
Every podcast-accessibility system we have shipped maps to the same seven stages. Skip one and that is where the audit finding surfaces.
1. Ingest. A new episode enclosure lands on an RSS feed; a webhook or scheduled poller queues a job. Kafka, SQS, or a lightweight pub/sub (Redis Streams, NATS) handles fan-out.
2. ASR. A batched call to Deepgram Nova-3 or AssemblyAI (or an on-prem Whisper worker if privacy demands it). Output: word-level JSON with timestamps, confidence, and speaker hints.
3. Enrichment. pyannote diarization overlay, Claude Sonnet 4.6 chapters and summary, optional DeepL and ElevenLabs translation and dubbing per target language.
4. Transcript assembly. Merge ASR, diarization, and translation into one canonical JSON, then emit WebVTT and SRT sidecars. Store all three in R2 / B2 / S3 under versioned keys.
5. RSS enrichment. Update the feed with <podcast:transcript>, <podcast:chapters>, and, for dubs, <podcast:alternateEnclosure>. Ping via Podping or WebSub so apps re-poll quickly.
6. Semantic index. Chunk the transcript (60-second windows, 10-second overlap), embed with Gemini Embedding or Qwen3-Embedding, upsert to Pinecone / Weaviate / Qdrant. This powers in-episode search, cross-catalog discovery, and episode Q&A.
7. Web player. React plus ARIA live regions render the synchronized transcript; WCAG 2.2 AA controls (24×24 targets, focus-not-obscured, keyboard order). Test with NVDA, JAWS, and VoiceOver before ship, not after.
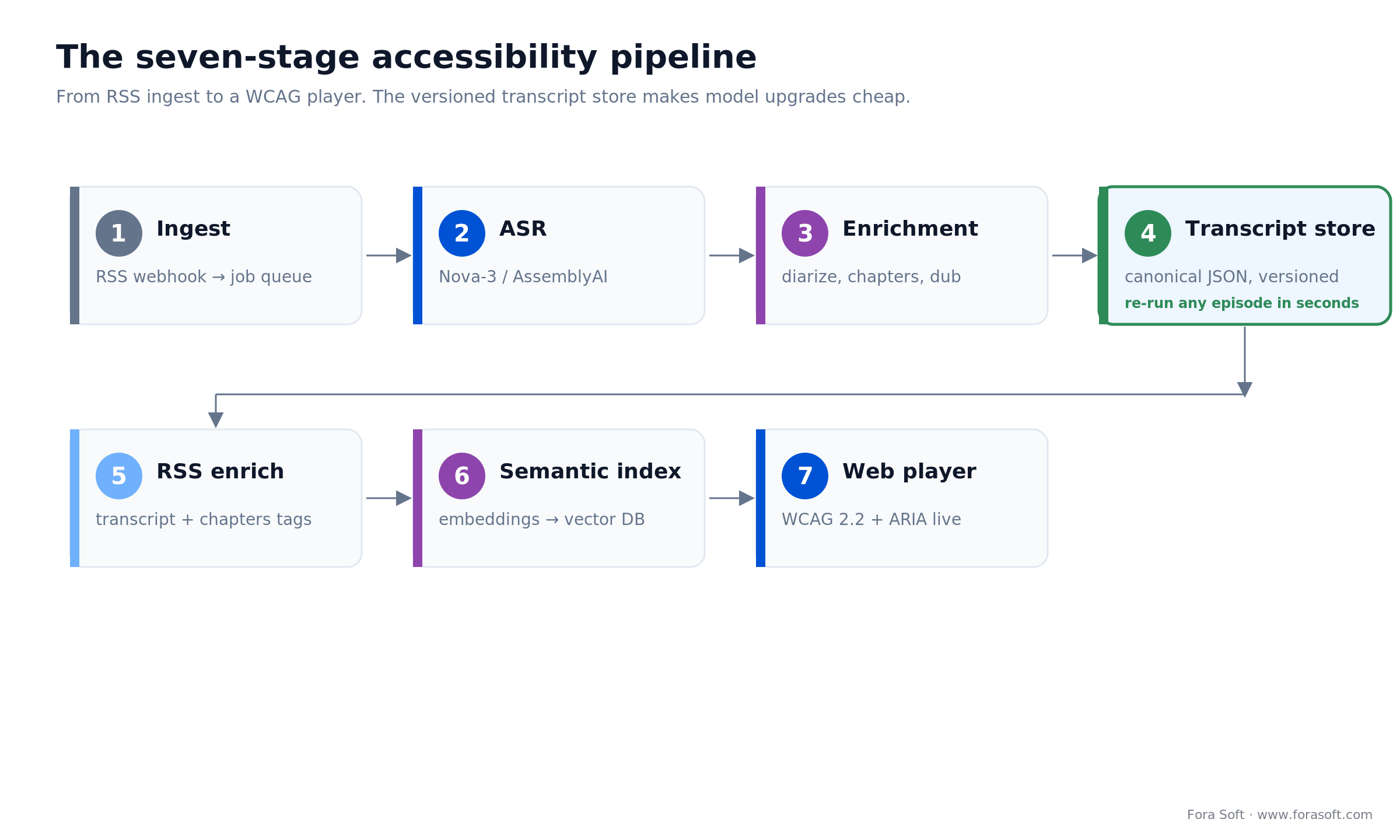
Figure 4. The seven-stage pipeline. The versioned transcript store in stage 4 is what makes model upgrades cheap.
Reach for an idempotent transcript store when: you expect to run for years. ASR vendors reprocess old audio when a better model ships. Treat the JSON transcript as the canonical artifact, with a version field and deterministic keys, and you can re-run any episode in seconds instead of rebuilding the whole enrichment stack. This one decision is what lets us ship accessibility upgrades far faster than teams bolting transcripts onto a legacy CMS.
Mini case: an EdTech audio platform ships EAA-ready in nine weeks
A Fora Soft client runs a European corporate-learning platform that delivers about 4,000 lectures a year as audio-first content, the same lineage as our Scholarly learning-platform work. The EAA went live on 28 June 2025, and their legal team gave us 12 weeks to be compliant or cancel the EU rollout. We shipped in nine.
The plan. Deepgram Nova-3 for ASR (accents, code-switching, integrated diarization for the typical two-to-three speakers), DeepL to six EU languages, Claude Sonnet 4.6 for summaries and chapters, Cloudflare R2 plus a Podcasting 2.0 feed for delivery, a new WCAG 2.2 AA React player tested on NVDA and VoiceOver, and a Pinecone serverless index over roughly 6,000 hours of archive for in-catalog search.
The result, 90 days in production. The EAA conformance audit passed on first review with an externally signed VPAT 2.5. Episode-completion rate rose 14% on a CUPED-adjusted cohort. Transcript pages added about 38,000 organic visits a month within the quarter. Support tickets asking “can I get a transcript” fell 94%. Total infrastructure cost held near $2,400 a month for 4,000 lectures a year with six-language translation. Want a similar readiness assessment? Book a 30-minute call.
Five pitfalls that kill podcast-accessibility projects
1. Treating the transcript as the deliverable. The transcript is raw material. The deliverable is the synchronized, searchable, accessible reader in your web player and in third-party apps. Teams that stop at the JSON file fail audits.
2. Under-building the web player. Wrong ARIA live regions, broken focus management, contrast below 4.5:1, targets under 24×24: any one fails WCAG 2.2. Test with a real screen reader (NVDA, JAWS, VoiceOver) every sprint, not just at release.
3. Skipping consent for voice cloning. ElevenLabs, Respeecher, and Resemble AI all require verifiable consent for voice reuse. EU AI Act Article 50 (from 2 August 2026) requires disclosure that dubbed audio is AI-generated. Running a cloned voice in production without documented consent and disclosure is a straight-line fine.
4. Trusting platform auto-transcripts. Apple auto-generates but lets creators override; Spotify now takes creator uploads via RSS too, but auto-quality still varies by language and show. Ship your own corrected transcript so you control accuracy, language coverage, and timing rather than inheriting whatever the platform produced.
5. Ignoring RSS propagation delay. Aggregators re-poll on 15-minute to 24-hour cycles. If your pipeline updates the RSS after the episode goes live, accessibility features can lag by hours. Serve transcripts ready from the publish event, not from a post-publish job.
KPIs: what to measure
Accessibility quality. Transcript WER on a sampled test set, diarization DER, caption accuracy (auditors expect roughly ≥95% word accuracy on a sampled review), WCAG 2.2 AA conformance on the player, axe-core automated score, and NVDA / VoiceOver manual pass rate.
User impact. Episode-completion lift, transcript-view rate, transcript-to-search click-through, time spent per episode, catalog search usage, and per-language engagement for translated content.
Compliance and ops. Days from publish to transcript live, share of episodes with transcript plus chapters plus summary, count of disability-related support tickets, and the outcome of each quarterly external audit.
When NOT to build this in-house
Honesty sells better than a pitch, so here is where an in-house build is the wrong call.
Fewer than about 50 episodes a month. Managed tools (Descript, Podcastle, Castos, Buzzsprout with integrations) cover this for under $200 a month with no engineering to maintain.
No web-player team. If you do not own your player, about 40% of WCAG 2.2 AA criteria sit outside your control. Fix ownership first, then add accessibility to it.
No semantic-search ambition. If you never plan to search inside or across episodes, a transcription-plus-delivery SaaS is cheaper than a pipeline you have to run.
A decision framework in six questions
1. Am I subject to the EAA, ADA Title II above 50k, or a federal 508 procurement? If yes, the answer is a full pipeline plus a VPAT, not a SaaS wrapper.
2. Do I need low latency (live captions, real-time translation)? If yes, Deepgram Nova-3 streaming. If not, batch on AssemblyAI for roughly half the cost.
3. Do I need dubs, not just translated transcripts? If yes, DeepL plus ElevenLabs, and budget the consent and Article 50 disclosure workflow.
4. Does content carry jargon, accents, or code-switching? If yes, plan for real-world WER of 12-20% and human review on your most-listened episodes.
5. Do I need search inside and across episodes? If yes, index embeddings from day one. Retrofitting a semantic layer later costs about three times as much.
6. Do I own my web player? If no, expect to fail half the WCAG criteria until you do. Prioritize that refactor above everything else.
Want us to run this framework with you?
In 30 minutes we walk your current player, ingest, and RSS output, then send a written EAA / ADA Title II readiness teardown.
Integration playbook: the 10-to-14-week path
| Weeks | Phase | Deliverables |
|---|---|---|
| 1-2 | Discovery + VPAT draft | WCAG 2.2 gap analysis, EAA scope, player audit, VPAT 2.5 skeleton |
| 3-4 | Pipeline v1 | Deepgram / AssemblyAI integration, storage, transcript schema, RSS enrichment |
| 5-7 | Player refactor | WCAG 2.2 AA player, synchronized transcript, keyboard nav, ARIA live, font + contrast controls |
| 8-9 | Enrichment + search | Chapters, summaries, translation, dubbing, semantic index in Pinecone / Weaviate |
| 10-11 | Audit + remediation | External WCAG 2.2 audit, NVDA / JAWS / VoiceOver testing, remediation sprint |
| 12-14 | Launch + monitoring | Signed VPAT, accessibility statement, monitoring, retrain cadence, team training |
Where podcast accessibility is heading in 2026-2027
On-device ASR. NVIDIA NIM, AMD Ryzen AI, whisper.cpp, and Apple's on-device models are pulling transcription onto the listener's device for privacy-sensitive verticals. Expect “private podcast” apps (therapy, corporate training, journalism sources) where transcripts never touch the cloud.
Real-time dubbed livestreams. ElevenLabs and HeyGen already dub in near real time in studio. Over 2026-2027 that plugs into live protocols (LL-HLS, WebRTC) for simultaneous multi-language podcast livestreams.
Semantic discovery. Transcript-indexed vector search turns a catalog from “browse by show” into “ask a question, get a clip list.” Snipd and independent players are already here; platforms that hold listener data will follow.
Audio-description automation. Twelve Labs Marengo, Gemini 2.5 Pro, and Claude 4.6 can draft audio descriptions from video frames now. One human reviewer per hour keeps cost sane, and WCAG 2.2 success criterion 1.2.5 gets easier to meet.
FAQ
Do I need a transcript if Apple already auto-generates one?
Yes. Apple's auto-transcript is a baseline, not a ceiling. You cannot correct it, it does not cover every language, and it only appears inside Apple Podcasts. A creator transcript delivered through <podcast:transcript> overrides Apple's and renders everywhere Podcasting 2.0 is supported, including Spotify since late 2025.
Does Spotify accept creator transcripts now?
Yes, since late 2025. Spotify supports the Podcasting 2.0 <podcast:transcript> tag, displays RSS-linked transcripts in-app, and lets creators edit and re-upload them. With Apple, Spotify, and Pocket Casts all rendering RSS transcripts, three of the five biggest apps now show your file if you ship one.
VTT or SRT: which format should I ship?
Ship both. WebVTT is web-native and CSS-styleable; SRT has the broadest platform and LMS compatibility. Add JSON if you want the richest experience on Spotify and to feed semantic search. Converting between them is trivial and costs a few kilobytes per episode.
What word error rate is good enough?
Under 10% on a representative sample is a strong 2026 target. Regulators speak in terms of “effective equivalence” to the spoken content; in practice auditors accept captions at roughly ≥95% word accuracy on a sampled review. Expect raw ASR at 12-20% on hard audio, so budget a human correction pass on your most-listened episodes.
Is voice cloning allowed for dubbing episodes into other languages?
Only with verifiable consent from the speaker, and from 2 August 2026 the EU AI Act Article 50 requires you to disclose the audio is AI-generated, with machine-readable marking phased in by 2 December 2026. Use ElevenLabs Professional Voice Cloning, Respeecher, or Resemble AI with documented consent records.
How do I handle multi-speaker panels with overlapping speech?
Use a diarization layer trained on multi-party audio (pyannote 3.1, or the integrated diarization in Deepgram and AssemblyAI) and expect to correct roughly 10% of speaker labels by hand on panels of four or more. Build that review step into the workflow rather than pretending the model gets it right.
Do I need to re-transcribe my entire back catalog?
Not all of it, but prioritize the top 20% by listens (usually 80% of engagement) plus any episode that still sells ads or ranks in search. Bulk back-catalog transcription runs about $0.15-$0.26 per hour, and the search payoff often justifies the full sweep.
How long until transcript changes reach the apps?
RSS aggregators poll on 15-minute to 24-hour cycles. Podping (WebSub) cuts that to minutes for participating apps. Otherwise plan for same-day propagation on most clients, and always publish the transcript with the episode, not after it.
What to read next
Language
AI simultaneous interpretation
The live-audio cousin of podcast translation: same ASR stack, sub-second latency.
Video Infra
AI streaming platform playbook
CDN, DRM, CMAF, and where captions and transcripts plug in.
Accessibility
AI accessibility in UI / UX design
The WCAG 2.2 design playbook that wraps around the podcast stack.
Speech
Streaming speech-to-text API tips
Vendor pricing, latency, and integration for live captioning.
Ready to make your podcast accessible?
Podcast accessibility in 2026 is a four-layer infrastructure problem. Transcribe with Deepgram Nova-3 or AssemblyAI, enrich with diarization, translation, and AI chapters, deliver through the Podcasting 2.0 namespace (Spotify included now), and render in a WCAG 2.2 AA player that survives NVDA and VoiceOver. Do that and you clear the EAA and ADA Title II, lift completion rates, pull organic traffic from transcript pages, and reach the listeners who need the features most.
Fora Soft has shipped audio and video platforms since 2005, and our Agent-Engineered delivery compresses the full rollout into 10 to 14 weeks for most podcast products. If you are scoping EAA or ADA Title II readiness this fiscal year, we would like to be on your short list.
Ready to scope podcast accessibility?
A 30-minute call, a written teardown of your current stack afterward, and no-obligation pricing.








