



Key takeaways
• Detection is commoditized; intent is the moat. YOLO-class detectors run at 15–60 FPS on the edge. The differentiator in 2026 is reasoning — what is the person doing, why, and what should we do about it.
• Stack, don’t swap. Production systems run a three-tier pipeline: YOLO + tracker on the edge, a vision-language model (VLM) for scene captioning, and an LLM for intent reasoning — not one giant model on every frame.
• The cost math now works. Gemini 2.5 Pro processes a one-hour clip in low-resolution mode for around $0.30. Self-hosted Qwen2.5-VL-72B on H100 breaks even with cloud APIs at roughly 500 hours of video per month.
• The EU AI Act of August 2, 2026 changes the obligations. Real-time biometric identification is high-risk; AI-generated content must be labelled (Article 50); human oversight, transparency, and DPIAs become mandatory for surveillance products in the EU.
• Hallucinations are the new failure mode. Benchmarks like VIDHALLUC show under-55% accuracy on safety-critical classes under temporal corruption. Ensemble detection + VLM caption + LLM reasoning + human-in-the-loop is the only sane architecture for high-stakes alerts.
Why context and intent matter in 2026
Traditional video systems spot objects: a person, a car, a backpack. They draw a box. They count. That’s detection — and in most production stacks shipped before 2024, that’s where the intelligence ended. The operator was left to read the boxes and infer what was happening.
Three things changed. First, multimodal LLMs grew video-native: Gemini 2.5 Pro takes a one-hour clip directly through its File API, Qwen2.5-VL-72B handles long video on commodity H100s, and MiniCPM-V 2.6 fits an 8.1 B-parameter VLM into 5.5 GB of edge memory. Second, the cost dropped: a one-hour video processed by Gemini at low resolution costs roughly thirty cents in 2026. Third, the regulators arrived: the EU AI Act’s core framework went operational on August 2, 2026, and the rules around remote biometric identification, AI-generated content labeling, and transparency now apply directly to surveillance products.
The result is a new product category — contextual video intelligence — where the system narrates what is happening, infers intent, lets operators search by natural language, and escalates only the events worth a human’s attention. This article is the playbook we use at Fora Soft when a client asks us to build one.
Why Fora Soft wrote this playbook
Fora Soft has built video and AI products since 2005, more than 600 of them. Three streams of work feed this guide: real-time streaming infrastructure (WebRTC, MediaSoup, LiveKit, MoQ), computer-vision pipelines (YOLOv8/v9, ByteTrack, BoT-SORT, DeepSORT), and conversational/multimodal agents on top of those. Our delivery model is spec-driven agent engineering, which compresses what was a six-month build into eight-to-twelve weeks — and we price accordingly.
Three projects feed every architectural decision below. V.A.L.T. is a video-evidence platform serving 770+ US police, child-advocacy, and medical organizations — 2,500 IP cameras, 25,000 daily users, $9.7M revenue. Meetric is an AI sales-video platform (SEK 21M funded) that runs intent-detection and call-summary inference at scale. DSI Drones ships aerial surveillance with on-device threat detection. We have run every layer of the stack below in production at least once.
Sketching a contextual video product?
Bring us the camera count, the use case, and the latency target. We’ll redline a hybrid YOLO + VLM + LLM architecture and give you a delivery estimate on a 30-min call.
From detection to intent: the 60-second answer
Detection answers “what is in the frame?” Tracking answers “is it the same person across frames?” Captioning answers “what is happening in this scene?” Reasoning answers “why, and what should we do?” Contextual video intelligence is all four, layered — not a single model running on every frame.
The cheap, fast layers (detection, tracking) run on the edge at 15–60 FPS and produce embeddings and short clips. The expensive layers (VLM captioning, LLM reasoning) run in the cloud at 0.5–8 FPS and produce narrative output, intent labels, and natural-language search. The thin pipe between them carries embeddings, alert clips, and operator feedback — not raw video. That’s the architecture in one paragraph.
The reference architecture: edge CV + cloud VLM + LLM reasoning
Production systems converge on the same shape, whether built by Ambient.ai, Coram AI, Twelve Labs, or by us for clients. Three tiers, one feedback loop.
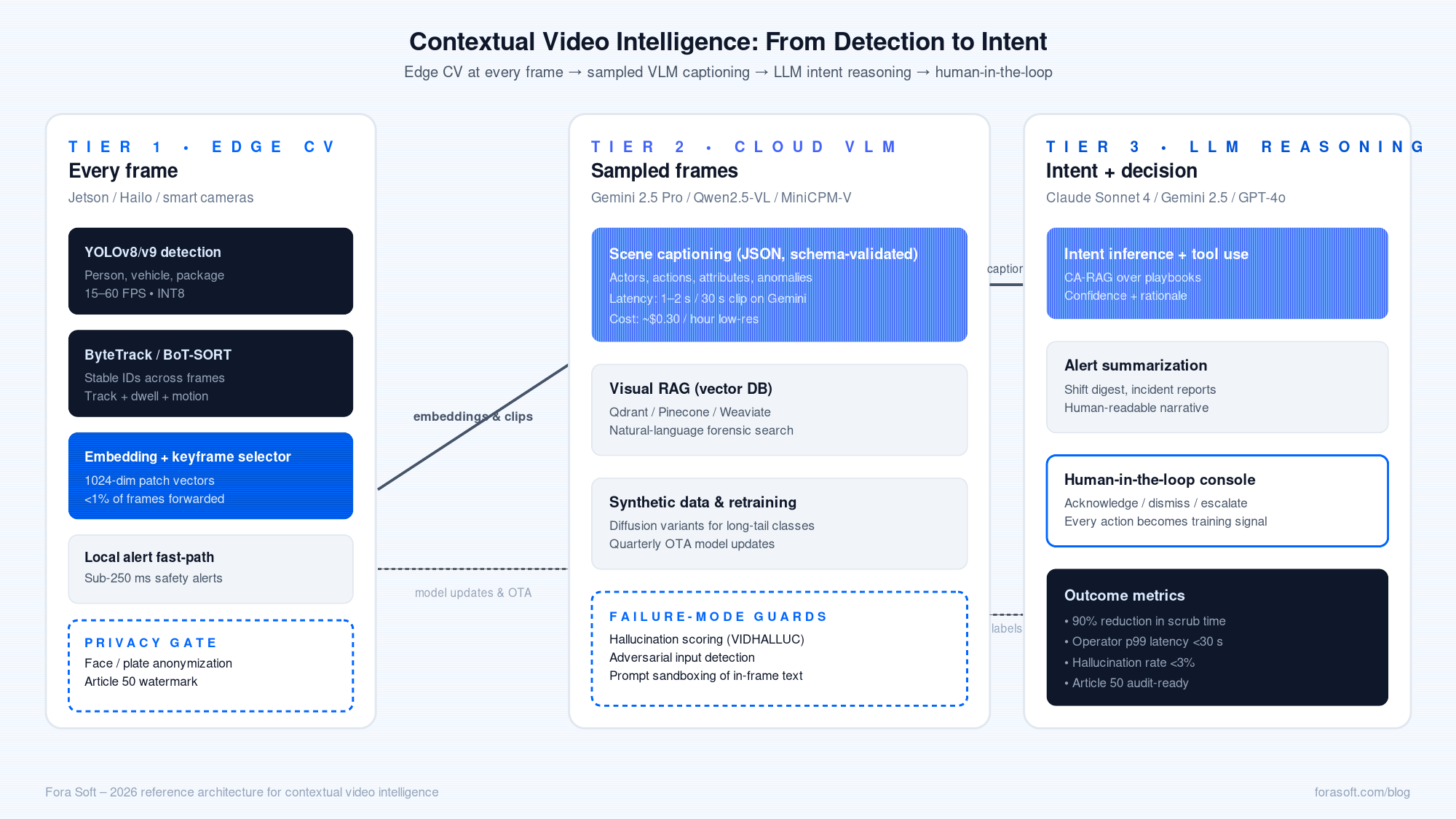
Figure 1. The 2026 hybrid reference architecture for contextual video intelligence.
Tier 1 — edge CV (every frame)
YOLOv8/v9 detection plus a multi-object tracker (ByteTrack, BoT-SORT, or DeepSORT) running on a Jetson Orin Nano, Hailo-8, or smart camera. Every detection produces a small embedding plus the temporal context (track ID, dwell time, motion vector). 99% of frames never leave the edge. Our detailed take on this tier lives in the YOLO + ByteTrack + DeepSORT guide.
Tier 2 — cloud VLM (sampled frames)
A vision-language model (Gemini 2.5 Pro, Qwen2.5-VL-72B, or MiniCPM-V 2.6) takes 1-FPS sampled clips around interesting events and emits a structured caption: scene, actors, actions, attributes. Output is JSON, low temperature, schema-validated. Latency budget: 1–2 seconds for a 30-second clip on Gemini, 5–10 seconds for a 1-minute clip on a self-hosted Qwen.
Tier 3 — LLM reasoning + agent (intent)
An LLM ingests the structured caption plus a short context window (the last N captions for this entity, the venue’s rules, prior incidents) and emits an intent label, a confidence, and a recommended action. This is where you bolt on retrieval — over operator playbooks, prior incidents, and a graph DB of entities and relationships (CA-RAG). Anything below the confidence threshold goes to a human; everything above auto-routes.
Tier 4 — human-in-the-loop feedback
Every operator action (acknowledge, dismiss, escalate) becomes labelled training data. Hard cases queue back to the cloud for re-inference with a bigger model and into the retraining set for the edge. Without this loop the system drifts. With it, accuracy compounds.
The models that matter in 2026
Pick by tier, not by hype. The detection tier wants speed. The VLM tier wants context length and structured output. The LLM tier wants reasoning and tool use. Below is the shortlist we recommend to clients today.
| Layer | Model | Where it runs | Why pick it |
|---|---|---|---|
| Detection | YOLOv8/YOLOv9 (INT8) | Edge (Jetson, Hailo, smart cam) | 15–60 FPS, mature ecosystem. |
| Tracking | ByteTrack / BoT-SORT | Edge | Stable IDs across occlusions; cheap. |
| Embedding | Twelve Labs Marengo / Florence-2 | Edge or cloud | 1024-dim vectors enable visual RAG and natural-language search. |
| VLM (cloud) | Gemini 2.5 Pro / GPT-4o-vision | Cloud API | Native video, ~1 hr context, $0.30–1.80/hour. |
| VLM (self-hosted) | Qwen2.5-VL-72B / InternVL2.5 | H100 / H200 | Open weights, MVBench leader, full data control. |
| VLM (edge) | MiniCPM-V 2.6 / LFM2.5-VL | Jetson AGX / industrial PC | 5.5 GB footprint; sub-250 ms inference at 4 FPS. |
| Reasoning LLM | Claude Sonnet 4 / Gemini 2.5 / GPT-4o | Cloud API | Tool use, structured outputs, RAG-friendly. |
Reach for self-hosted Qwen2.5-VL when: data residency forbids sending video to a US cloud, your monthly volume exceeds ~500 hours, or you need to fine-tune on your domain (ATM lobbies, pharmacy aisles, oil-and-gas catwalks).
Real-time vs near-real-time vs forensic: latency budgets
Three operating modes cover almost every contextual video product. Pick the mode per use case, not per camera, and design the pipeline accordingly.
| Mode | Target latency | What runs where | Use cases |
|---|---|---|---|
| Real-time alert | <250 ms | Edge CV + edge VLM (MiniCPM-V or LFM2.5-VL) | Intrusion, fall, weapon-vs-phone, line-stop. |
| Near-real-time | 1–5 s | Edge CV + cloud VLM + cloud LLM | Behavioral anomaly, loitering, scene narration. |
| Forensic search | Seconds–minutes | Cloud batch, vector DB | Investigations, query-by-language, daily reports. |
A real production case: a 16-camera oil-and-gas CCTV pipeline reported in ScienceDirect achieved 16.5 FPS aggregate throughput and an end-to-end alert latency of 26.76 seconds across 21 hours of continuous operation. That’s “near-real-time” in our taxonomy — well below the threshold that leaves an operator looking at a stale dashboard.
Cost economics: cloud APIs vs self-hosted GPUs
The cost discussion has three buckets. Per-hour video-token billing on cloud APIs is the most predictable. Self-hosted GPU rental is the cheapest per hour at scale. Embedding storage is essentially free in 2026.
| Stack | Cost / hour video | Notes |
|---|---|---|
| Gemini 2.5 Pro (low-res) | ~$0.30 | Best for >10-min clips; supports caching. |
| Gemini 2.5 Pro (default) | ~$0.90 | Higher recall on small objects. |
| GPT-4o-vision | ~$1.80 | Manual frame submission; reliable JSON. |
| Self-hosted Qwen2.5-VL-72B (GMI) | ~$2.10 (H100 rental) | Cheapest above ~500 h/month. |
| Self-hosted Qwen2.5-VL-72B (AWS) | $4–8 | Hyperscaler markup; only when compliance demands it. |
Two decision rules. Below 100 hours of video processed per month, cloud APIs win on TCO. Above 500 hours per month, self-hosting on a GPU-cloud provider like GMI or Lambda wins. Between 100 and 500 hours, the answer depends on whether your workload is bursty (favor APIs) or steady (favor self-host).
Use cases that GenAI unlocks
1. Scene narration. Replace bounding boxes with a one-line description an operator can read at a glance: “Two people in hard hats operating a forklift near pallets at 03:42 AM” instead of “person, person, vehicle.”
2. Intent inference. Distinguish “loitering with a phone at the fence line” from “maintenance worker on rounds.” The VERA framework reports a 30% AUC lift over baseline by replacing generic prompts with fine-grained reasoning prompts.
3. Weapon-vs-phone disambiguation. Pure object detection misclassifies the same elongated dark object differently across frames. A VLM with the surrounding context (posture, gesture, audience reaction) resolves it correctly — but only if the operator stays in the loop.
4. Query-by-natural-language forensic search. “Show me clips of someone leaving with a backpack between 3 and 5 PM yesterday.” Visual RAG over 1024-dim embeddings replaces frame-by-frame scrubbing — we typically see 90% reduction in operator search time once it ships.
5. Multi-camera correlation. Track a person of interest across a 50-camera campus. Tier-1 detection plus tier-3 LLM reasoning over re-identification embeddings does this without sending every frame to the cloud.
6. Alert summarization. Roll up a shift’s alerts into a paragraph for the morning briefing. This is what makes VLM output usable to non-technical stakeholders.
7. Synthetic data for hard cases. Generate diffusion-model variants of rare events (PPE violations, slips, fights) to balance training sets without real-world capture. We see VLM accuracy lift on long-tail classes by 10–20% when the synthetic ratio is tuned correctly.
Reach for natural-language search when: investigators or operators currently scrub recordings for hours per case — the productivity lift is the easiest ROI story to put in front of a CFO.
Implementation pattern: structured outputs & visual RAG
Two patterns are doing the heavy lifting in the products we ship. Both are simpler than they look once you see the wiring.
Structured-output VLM call
Always force the VLM to emit JSON against a schema. Temperature 0.1, validate, retry once on schema failure. The schema becomes the contract between vision and reasoning.
{
"scene": "warehouse loading dock, dusk",
"actors": [
{"id": "track-42", "role": "worker", "ppe": ["hard_hat", "vest"]},
{"id": "track-43", "role": "visitor", "ppe": []}
],
"actions": ["forklift_operation", "pedestrian_walking_in_zone"],
"anomalies": ["unauthorized_pedestrian_in_forklift_zone"],
"confidence": 0.82
}
Visual RAG
Embed every detection patch into a vector DB (Qdrant, Pinecone, Weaviate). At query time, embed the user’s natural-language query, retrieve top-K patches, send them plus the query to the VLM for re-ranking, then to the LLM for narrative output. This is the engine behind “show me all clips of someone with a backpack” and it works at meaningful scale today.
Need a VLM-grade video product without the multi-quarter build?
Our spec-driven agent engineering ships a working pilot in 8–12 weeks. Bring the use case — we’ll bring the architecture and the budget on a 30-min call.
Privacy and the EU AI Act of August 2026
As of August 2, 2026, the core EU AI Act framework is operational. Three pieces matter most for contextual video products. Real-time remote biometric identification on CCTV is high-risk under Annex III; you owe conformity assessment, fundamental-rights impact assessment, registered logging, and human oversight. AI-generated or AI-modified video must be labelled under Article 50 — this affects synthetic-data dashboards, blurred-face overlays, and any clip where the system stitches together VLM-generated commentary. Prohibited practices include emotion inference at work or in schools and untargeted scraping of CCTV/internet for face databases.
Our companion piece on 2026 AI Surveillance Trends and Ethics walks the obligations end to end. The shorthand for engineers: keep raw video on premise where possible, log every model decision with operator context, build the human-in-the-loop control plane on day one, and treat the audit trail as a first-class deliverable.
Reach for on-premise / sovereign cloud when: the deployment touches EU residents in employment, schools, healthcare, or government settings — the obligations stack up fastest there.
Failure modes: hallucinations, adversarial inputs, drift
1. Temporal hallucination. The VIDHALLUC benchmark shows VLMs at under 55% accuracy on safety-critical classes (pedestrians, traffic signs) when frames carry motion blur or sensor noise. Mitigate with fine-grained prompting, temporal consistency scoring, and an ensemble of detector + VLM where they have to agree before an alert escalates.
2. Adversarial inputs. A printed pattern on a T-shirt or sign can persistently mislead a VLM across frames. Defenses: detection-side watermark/anomaly scoring, prompt sandboxing on any text the VLM transcribes, and refusing to act on any text content lifted from inside the camera frame.
3. Action–scene mismatch. A worker walks past a smouldering pallet and the VLM narrates only the worker. The CVPR 2025 MASH-VLM line of work shows multi-task learning + confidence calibration cuts these omissions; in production we add hard rules (smoke detection, fire detection) that always escalate regardless of the VLM’s narrative.
4. Concept drift. Camera angles change, uniforms change, seasonal scenery changes. Without a retraining loop, false-positive rates climb noticeably after 12–18 months. Build the hard-case collection pipeline before launch, not after.
5. Silent regressions on model upgrades. A new VLM release can change phrasing, JSON edge cases, or tail-class behavior. Maintain a small held-out validation set per use case and rerun it on every model bump; gate the rollout on the metric.
Reach for ensemble + human-in-the-loop when: the alert can trigger a real-world action — a turnstile lock, a dispatch, an arrest. Single-model verdicts are not safe at that bar.
Mini case: V.A.L.T. — 770+ orgs, AI-driven evidence search
Situation. A US-based video evidence platform serving 770+ police departments, child-advocacy centers, and medical organizations. Investigators were spending hours scrubbing recordings frame by frame to locate moments of interest in interview rooms.
What we built. An on-camera detection layer for events of interest, plus a cloud reasoning layer that produces structured captions and embeddings for each event. Investigators now type a natural-language query (“clips where the subject says they were not at the scene”) and the system returns ranked clip references, each with a JSON rationale and a confidence score. Audit logs and human approvals are stitched into the chain of custody.
Outcome. 2,500 IP cameras under management, 25,000 daily users, $9.7M revenue. Time spent on a typical evidence review dropped sharply once the natural-language search shipped. Read the full V.A.L.T. project page or book a 30-min review if you’re building a similar evidence or compliance product.
A decision framework — pick your tier in five questions
1. Is the question “what is here?” or “why is this happening?” Object detection alone solves the first. You need a VLM and an LLM for the second.
2. What’s the latency budget? Under 250 ms forces edge VLMs (MiniCPM-V, LFM2.5-VL). 1–5 s opens the door to cloud Gemini/Qwen. Forensic search has no real-time requirement at all.
3. How much video per month? Under 100 hours — cloud API. Over 500 hours — self-host on H100. In between — depends on burst pattern.
4. What regulators apply? EU residents, schools, hospitals, law enforcement, NDAA-controlled sites — on-premise or sovereign cloud, with full audit trail and Article 50 labelling. Otherwise — commercial cloud is workable with a strong DPA.
5. Is the action automated or human-mediated? Automated alerts (turnstiles, line-stops) need ensemble certainty. Human-mediated alerts (operator triage, investigator search) tolerate VLM uncertainty if the rationale is shown.
Five pitfalls we see teams hit
1. Treating the VLM as the front door. Sending every frame to a VLM blows the budget and the latency. Detection at the edge funnels what reaches the VLM — aim for under 1% of frames.
2. Free-form natural-language outputs. A paragraph reply is unparseable. Force JSON with a strict schema; reject and retry on parse failure; log the schema violations and use them as training signal.
3. No held-out evaluation set. Without an internal benchmark, a model upgrade silently breaks behavior. We build a 200–500-clip eval per use case before any model is shipped, and rerun it on every change.
4. Skipping the operator feedback loop. If the operator’s “dismiss/escalate” clicks aren’t flowing back to retraining, you’re paying for an AI that can’t learn. The loop is cheap to build and pays for itself in the first quarter.
5. Ignoring Article 50 labelling and the FRIA. “We’ll add the compliance UI later” is what teams say in week 2 and regret in week 18 when an EU pilot stalls. Build the labelling, the watermark, and the fundamental-rights impact assessment template into the product spec from the first sprint.
KPIs to measure
Quality KPIs. mAP per class on your own validation set (not COCO). VLM JSON schema-violation rate — under 1% is healthy. Hallucination rate sampled by operator audit — under 3% on safety-critical labels.
Business KPIs. Cost per alert delivered (target under $0.10). Operator time-to-decision after alert (median under 30 seconds). Customer-reported missed events — trend down quarter over quarter.
Reliability KPIs. P99 latency from frame to operator (within budget per mode). VLM API error rate (target <0.5%). Mean time to recover after a model rollback (under 10 minutes on a healthy CI/CD).
When NOT to use GenAI on video
GenAI is the wrong tool when the question is closed-form and high-frequency. Counting cars at an intersection? YOLO + tracker. Person-vs-no-person on a doorbell camera? YOLO + tracker. Reading license plates? OCR. You don’t need a VLM; you need a tight detector and a small operations bill.
GenAI is also wrong where you can’t tolerate hallucinations and you can’t afford an operator. Fully-automated weapon classification with no human in the loop is not a 2026 product; it’s a lawsuit waiting to happen. Use detection + alert + human triage and let the VLM provide rationale, not the verdict.
Ready to validate your VLM economics and architecture?
Send us your camera count, latency target, monthly hours, and compliance footprint. We’ll redline the stack and give you a delivery estimate — agent-engineered, faster than you’d expect.
A 90-day path from pilot to production
| Weeks | Phase | Outcome |
|---|---|---|
| 1–2 | Spec & eval set | 200–500 clip eval per use case; latency budgets agreed. |
| 3–5 | Pipeline v1 | Edge YOLO + tracker; cloud Gemini/Qwen with JSON schema. |
| 5–7 | Visual RAG & search UI | Vector DB live; natural-language search ships behind a flag. |
| 7–9 | Hardening | Hallucination tests, ensemble checks, operator feedback loop, observability. |
| 9–11 | Compliance | Article 50 labelling, audit logs, FRIA template, RBAC, encryption. |
| 11–13 | Pilot & ROI report | Live customer data; before/after KPI report; rollout plan. |
This is the timeline we use with new clients on contextual video products. The compression versus traditional builds comes from agent-driven scaffolding and the fact that the model layer is now an API, not a research project.
FAQ
What’s the difference between contextual video intelligence and classical computer vision?
Classical CV answers “what is in the frame.” Contextual video intelligence layers a VLM and an LLM on top of CV to answer “what is happening, why, and what should we do.” In practice it means narrative output, intent labels, and natural-language search instead of bare bounding boxes.
Which VLM should I start with for a contextual video product in 2026?
For most clients we start with Gemini 2.5 Pro — native video, 1-hour context window, $0.30/hour low-resolution mode. For sovereign-data deployments we move to self-hosted Qwen2.5-VL-72B on an H100. For real-time edge inference, MiniCPM-V 2.6 fits in 5.5 GB and runs at 4 FPS on a Jetson AGX Orin.
How fast can a VLM realistically respond on live video?
Edge VLMs (LFM2.5-VL, MiniCPM-V) hit sub-250 ms at 4 FPS today. Cloud VLMs land at 1–2 seconds for a 30-second clip on Gemini, 5–10 seconds for a 1-minute clip on self-hosted Qwen. Beyond that you’re in the forensic-search regime, which is fine for investigations but not for real-time alerts.
Does the EU AI Act apply to my video product if I’m not in the EU?
If your system processes the data of EU residents, yes — the regulation is extraterritorial. Most B2B contextual video products end up touching EU data through one customer or another. Build for compliance from the first sprint.
How do I keep VLMs from hallucinating safety-critical events?
Don’t rely on a VLM alone. Use an ensemble: classical detection plus VLM caption plus LLM reasoning, where two of the three have to agree before the system escalates. Add hard rules on smoke, fire, and weapon detection. Keep the human in the loop for any high-stakes alert.
Cloud API or self-hosted VLM — which is cheaper at my scale?
Below ~100 hours of video per month, cloud APIs (Gemini 2.5 Pro low-res) win on TCO. Above ~500 hours per month, self-hosting Qwen2.5-VL-72B on a GPU-cloud provider (GMI, Lambda) wins. Between those numbers, burstiness and compliance decide.
What does the visual RAG architecture actually look like under the hood?
Edge devices push 1024-dim patch embeddings (Twelve Labs Marengo or Florence-2) into a vector DB (Qdrant, Pinecone). At query time, we embed the user’s natural-language query, retrieve top-K patches, send them to the VLM for re-ranking, then to an LLM for narrative output. It’s a three-call pipeline that scales horizontally.
How long does a contextual video build take with Fora Soft?
A working pilot — 5–10 cameras, edge detection, cloud VLM with structured output, basic search UI — typically takes 8–12 weeks because we use spec-driven agent engineering. Production rollout depends on certifications, integrations, and camera count. Bring us a scope and we’ll give you a number on a call.
What to Read Next
Surveillance architecture
YOLO + ByteTrack + BoT-SORT + DeepSORT 2026 Guide
The detection and tracking stack that feeds every contextual video pipeline.
Edge vs cloud
Edge AI vs Cloud AI for Video Surveillance
Latency, cost, and the EU AI Act — where to put your inference.
Privacy & trust
2026 AI Surveillance Trends: Data Quality & Ethics
EU AI Act, GDPR, and the trust playbook for biometric video products.
Agentic video
Video AI Agents in 2026: Architecture & Economics
Latency budgets, per-minute economics, and the agent stack for live video.
Engineering practices
Real-Time Video Processing with AI: Best Practices
Architecture patterns and latency budgets from 250+ shipped video projects.
Ready to ship contextual video intelligence?
The 2026 answer for serious video products is the layered stack: YOLO and a tracker on the edge, a vision-language model for scene captioning, an LLM for intent reasoning, and a human in the loop for the high-stakes calls. Detection is commoditized; the moat is everything that turns boxes into narrative, queries, and decisions.
If you’re scoping a custom contextual video product — surveillance, industrial monitoring, sports, sales intelligence, healthcare — the technology choices are well-understood. The hard part is fitting them to your latency budget, monthly volume, and regulatory exposure. That’s the conversation we have with prospective clients on a 30-min scoping call — bring the constraints and we’ll bring the architecture and a delivery estimate.
Talk to a team that has shipped 600+ video and AI products
Edge inference, VLM captioning, LLM intent reasoning, EU AI Act-ready data flows. We do this for a living — and faster than you expect, because of agent engineering.









