



Key takeaways
• 1M concurrent viewers is a CDN problem, not an SFU problem. WebRTC SFUs cap around 500–2,000 viewers per node and cost $20k–$80k a month at 100k. CDN-delivered LL-HLS or MoQ scales to millions for the same egress dollars per gigabyte.
• The hybrid is the default. WHIP into a small WebRTC mesh for hosts and contributors; LL-HLS or MoQ to fan out to the audience; HLS at the edge for legacy players. Discord, Hopin, and the largest sports broadcasters all run a variant of this stack.
• 1M viewers for one hour at 4 Mbps is roughly 4.5 PB of egress. At $0.05/GB typical CDN list price, that’s about $225,000 in bandwidth alone — before transcoding, DRM, SSAI, ingest, and incident response.
• Reliability fails before bandwidth does. Netflix’s November 2024 Tyson–Paul fight peaked at 65M concurrent and saw 100k+ failure reports. Thundering herds on manifests, regional hot-spots, and ingest skew break before egress capacity does.
• The architecture jump points are well known. Under 10k — LL-HLS + CDN. 10k–100k — cascading SFU + LL-HLS. 100k–1M — CDN-primary with WebRTC contribution and DRM. 1M+ — petabyte CDN with predictive cache warming and tested failovers.
Why scaling real-time video to 1M viewers is still hard in 2026
If you’ve never run a 1M-viewer event, your instincts are probably wrong about where it breaks. The bandwidth is solved — AWS recorded 268 Tbps peak egress in November 2025, enough to push HD video to roughly 45M concurrent viewers. The CDNs have the pipes. What breaks is everything else: real-time segment scheduling, manifest cache coordination, regional hot-spots, ingest path failover, DRM token bursts, ad-marker timing across the bitrate ladder. The Netflix Tyson–Paul fight in November 2024 peaked at 65M concurrent and still produced 100k+ failure reports. Capacity wasn’t the problem. Coordination was.
This article is the playbook we use at Fora Soft when a client asks us to build (or rescue) a streaming product targeting six- or seven-figure audiences. We focus on the architectures that work, the costs that show up on the bill, and the reliability tactics that survive a real audience — not the slideware that survives a vendor demo.
Why Fora Soft wrote this playbook
Fora Soft has shipped video and AI products since 2005 — over 600 of them. Real-time and large-audience streaming sits at the centre of our practice: WebRTC, MediaSoup, LiveKit, Janus, Wowza, RTMP, SRT, LL-HLS, MoQ. We use spec-driven agent engineering to compress streaming-stack builds into 8–12 weeks where traditional shops quote two quarters.
Three reference projects ground this guide. BrainCert is a WebRTC virtual-classroom LMS at $3M revenue with 100,000+ customers. Sprii is a live-video shopping platform that has driven over €365M in sales through interactive broadcasts. Worldcast Live ships sub-second HD concert streams to global audiences. We’ve made every architectural decision below in production at least once.
Sizing a real-time streaming build for big audiences?
Bring the audience target, the latency budget, and the contributor model. We’ll redline a hybrid WebRTC + LL-HLS + MoQ stack and a cost model on a 30-min call.
The 60-second answer
Three protocols carry the load. WebRTC delivers sub-second interactive video to a small group; it caps somewhere between 10k and 100k viewers depending on stack and budget. LL-HLS and MoQ deliver to millions through a CDN with 1–3 seconds of latency. The default architecture for a serious 1M-viewer product in 2026 is hybrid: WHIP-based WebRTC ingest for hosts and contributors, LL-HLS or MoQ as the broadcast trunk, HLS at the edge as a long-tail fallback.
Pick the trunk by latency budget. Sub-second — MoQ where deployable, WebRTC where not. 1–3 seconds — LL-HLS. Higher latency tolerable — standard HLS or DASH, cheap and ubiquitous. The rest of this article is the math, the cluster sizes, and the reliability rules behind that recommendation.
The reference architecture for 100k–1M concurrent
Five tiers. Contribution, ingest, packaging, distribution, monetization. Build them as independent layers with clean interfaces so you can swap a tier without redoing the rest.
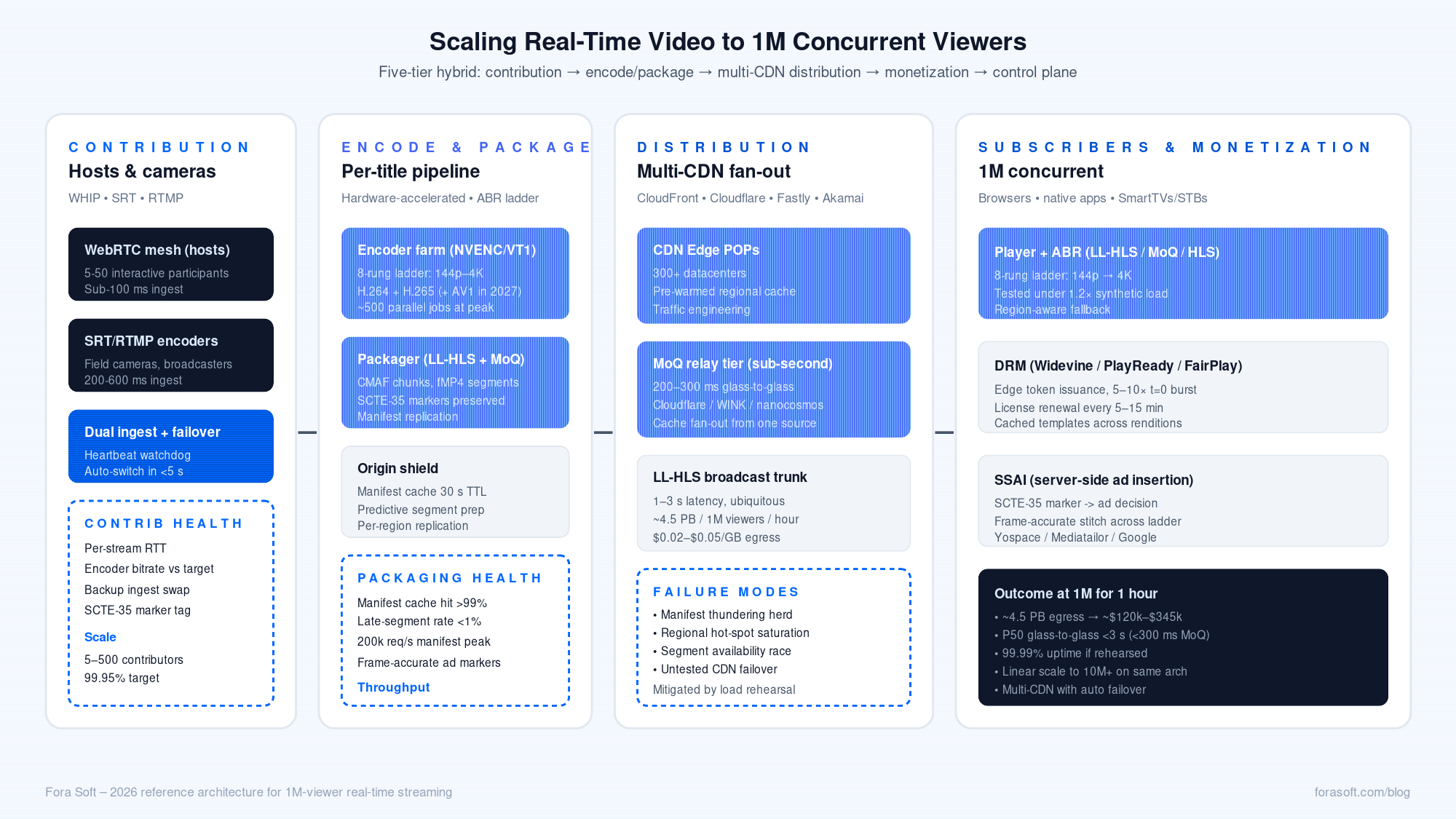
Figure 1. The five-tier reference architecture for 100k–1M concurrent live streaming.
Contribution
Hosts, presenters, contributors, and field cameras. WebRTC over WHIP is the modern ingest path — sub-100 ms upstream, single-request handshake, ICE included. Pair it with SRT or RTMP for legacy encoders.
Encoding and packaging
A small interactive WebRTC mesh for the hosts; a per-title encoder that emits a multi-rendition ladder; a packager that produces LL-HLS and MoQ tracks. Hardware acceleration (AWS VT1, NVENC, dedicated transcoder appliances) pays for itself above ~50 parallel encodes.
Distribution
Multi-CDN by default. AWS CloudFront, Cloudflare, Fastly, and Akamai for the broadcast tier. Pre-positioned cache nodes in the regions that will dominate the audience. Manifest replication so 200k requests/second don’t hammer a single origin.
Monetization
DRM (Widevine, PlayReady, FairPlay) tokens issued at the edge. SSAI for ad insertion against SCTE-35 markers in the source feed. These are the line items that often get bolted on at the end of the build — budget for them in week one.
Control plane
Observability per tier — manifest cache hit rate, late-segment rate, DRM token issuance rate, P99 glass-to-glass latency by region. The control plane is the difference between a 99.9% night and a 99.99% night.
Architecture jump points: 10k, 100k, 1M, 10M
| Concurrent viewers | Architecture | Where it breaks if you get it wrong |
|---|---|---|
| Up to 10k | Single LL-HLS origin + CDN; or single SFU mesh | Single origin saturates around 50k req/s without manifest cache. |
| 10k–100k | Cascading SFU mesh + LL-HLS hybrid; multi-region CDN | SFU $/min outpaces revenue; TURN bills explode. |
| 100k–1M | CDN-primary; WebRTC for contribution only; per-title encoding; DRM; SSAI | Manifest origin thundering herd; regional hot-spot saturation. |
| 1M+ | Multi-CDN, predictive cache warming, predictive ingest failover, traffic engineering | Untested failover; segment availability race conditions. |
Reach for CDN-primary the moment your peak forecast crosses 50k. Re-engineering at 200k is a quarter you don’t have during launch.
WebRTC SFU at scale: where the economics break
A single SFU node handles 500–2,000 viewers depending on the resolution mix, simulcast layers, and CPU model. Modern stacks — LiveKit, MediaSoup, Janus, Pion — all sit in that band. To serve 100k concurrent you need 50–100 SFU nodes in a cascading mesh, plus TURN relays for the 10–20% of viewers behind symmetric NAT.
The bills add up fast. Managed offerings (LiveKit Cloud, Daily, Twilio) charge in the $0.003–$0.024 per minute range depending on resolution. At 100k concurrent for a one-hour event, that’s on the order of $18,000–$144,000 in minutes alone — before TURN, before storage, before recording. DIY SFU clusters are cheaper at scale but introduce operational overhead that small teams underestimate.
The decisive number: above 100k concurrent, WebRTC SFU $/viewer-hour exceeds CDN-delivered LL-HLS by a factor of 5–15. The protocol still wins for low-latency contribution, conversational segments, and interactive stages with bounded participants — just not for the audience.
LL-HLS and DASH at CDN scale
Cloudflare Stream, Mux, Akamai, AWS Elemental + CloudFront, and Bitmovin all support Low-Latency HLS today. Glass-to-glass latency lands in the 1–3 second band on commodity CDNs — close enough to interactive for sports, esports, live commerce, and concerts where the audience is one-way. Standard HLS still has its place: 3–8 seconds, broadly compatible, regulator-friendly.
The economics are CDN economics: you pay for egress at $0.005–$0.085 per GB depending on volume tier and contract. List prices in 2025 sit around $0.05/GB for hyperscale CDNs, often half that on negotiated commits, and as low as $0.01–$0.04/GB on budget CDNs (Bunny, KeyCDN). At 1M concurrent for a one-hour event, you’re moving roughly 4.5 PB — about $225,000 at the $0.05/GB rate, less on a serious commit.
Reach for LL-HLS first when: your audience tolerates 1–3 seconds of latency and you need maximum browser, app, and SmartTV compatibility today — that covers ~95% of one-to-many streaming products.
Where MoQ fits in the 1M-viewer stack
Media over QUIC is the protocol that closes the 1–3-second LL-HLS gap. WINK Streaming and Cloudflare are running production MoQ at 200–300 ms glass-to-glass. WebTransport hit Web Platform Baseline in March 2026, so all major browsers can play MoQ without flags. We covered the protocol in depth in Building Applications with Media over QUIC.
For 1M-viewer products, MoQ is a sub-second alternative to LL-HLS with broadly similar CDN economics. It’s production-ready for one-to-many distribution at the architectures Cloudflare, nanocosmos, and WINK have shipped. Premium DRM integration, FCC-style broadcast compliance, and server-side ABR are still maturing — if you need any of those, run MoQ alongside LL-HLS as a low-latency lane and serve the legacy compliance lane separately.
What 1M concurrent for one hour actually costs
| Component | Driver | Range (USD) |
|---|---|---|
| CDN egress | ~4.5 PB at $0.02–$0.05/GB | $90k–$225k |
| Per-title encoding + packaging | 8-rung ladder, hardware-accelerated | $8k–$20k |
| WebRTC SFU cluster (contribution + interactive) | Bounded mesh of hosts + small audience | $5k–$30k |
| Origin / ingest | Redundant ingest, SCTE-35 marker injection | $5k–$15k |
| DRM | Edge token issuance, multi-DRM | $1k–$5k |
| SSAI / ad stitching | Per-impression decision + stitch | $2k–$10k |
| Engineering / on-call | War-room staffing for the event | $10k–$40k |
Total per event: roughly $120k–$345k for true 1M concurrent. Most teams hit $50k–$150k because they don’t actually peak at 1M on day one. The right plan is to engineer the stack so the architecture doesn’t change between 100k and 1M — only the capacity does.
Want a cost model on your numbers?
Send us your peak audience, bitrate ladder, and target latency. We’ll model CDN egress, transcoding, DRM, and SSAI on a 30-min call.
Capacity planning: clusters, regions, headroom
SFU sizing. 500–2,000 viewers per node. Plan for 65% utilization at peak so a regional failover doesn’t cascade. For 100k concurrent on the contribution side, that’s 50–100 nodes plus a 50% buffer.
Edge cache sizing. Manifest requests dominate at scale. With a 5-second segment cadence and 1M viewers, you’re seeing roughly 200,000 manifest requests per second. Target 30-second TTL on manifests, replicate per region, and invalidate by version on rollover.
Regional distribution. Place ingest in the broadcaster’s nearest region (NYC, Frankfurt, Tokyo). Spin up CDN edge in the regions that will dominate the audience. For US-prime sports, that’s East-1 + East-2 + Central + West with hot-warm pre-positioning.
TURN sizing. 10–20% of WebRTC viewers will need TURN relay. At 100k contribution-side concurrent, plan for 10k–20k relayed peers at 1 Mbps each. The bandwidth is real; the bill is real.
Reliability at scale: the four failure modes that bite
1. Manifest thundering herd. 1M clients re-fetch the manifest every few seconds. Untreated, the origin sees a 50k–200k req/s spike. Mitigation: 30-second cache TTL, per-region replication, invalidate-on-rollover, never serve a manifest from the origin without a CDN in front.
2. Regional hot-spot saturation. 40% of US-prime viewers will hit the same East-Coast POP. Pre-warm the regional cache with the first segments before the event starts; route the spillover deliberately.
3. Ingest path failure. Broadcaster’s uplink drops, RTMP times out, the encoder blue-screens. Without a tested second ingest path, the entire event drops. Mitigation: dual WHIP ingest with automatic failover, redundant encoders, monitored heartbeats.
4. Segment availability race. Encoder finishes segment at t=2.5 s; clients request at t=2.0 s; the CDN returns 404 and triggers retry storms. Mitigation: predictive segment generation, generous segment grace windows, 503-friendly retry on the player side.
Reach for full-load rehearsal when: the event matters and the audience exceeds 100k. Untested failover is the most expensive thing on the line item.
Encoding ladder, codec choice, and hardware acceleration
A typical 2026 ladder is 8 rungs from 144p up to 2160p, encoded once per source and served via ABR. Codec choice matters at 1M scale.
| Codec | Bitrate vs H.264 | Hardware encode (live) | Use it when |
|---|---|---|---|
| H.264 | Baseline | Universal NVENC / Apple / VT1 | Maximum compatibility, broad audience. |
| H.265 / HEVC | ~30% lower bitrate | Widely available | Premium audiences with modern devices. |
| AV1 | ~40–50% lower bitrate | Limited live HW; emerging | VOD today; live in 2026–2027 as silicon arrives. |
For most 2026 builds, ship H.264 across the full ladder and add HEVC for premium devices. AV1 live is technically possible — YouTube uses it for >75% of VOD — but the real-time hardware encode story is still arriving.
DRM and SSAI at scale
DRM tokens. Multi-DRM (Widevine, PlayReady, FairPlay) is non-optional for licensed sports and movies. Issue tokens at the edge so the spike on event start doesn’t hammer a single token service. Plan for a 5–10× baseline burst at minute zero.
SSAI. Server-side ad insertion against SCTE-35 markers in the source feed is the dominant pattern for live. The complexity is in keeping ad timing frame-accurate across the full bitrate ladder — mismatched markers across renditions cause black frames or skipped ads.
Mini case: Sprii — interactive live shopping at scale
Situation. A live-shopping platform that needed sub-second video for the host on stage and broadcast-class delivery to a buying audience that scales by an order of magnitude during peak campaigns — with payment flows, inventory holds, and ad insertion all running at the same time.
What we built. A hybrid stack: WebRTC mesh for hosts and guest contributors with WHIP ingest, an LL-HLS broadcast tier on a multi-CDN egress, edge token issuance for purchase auth, and predictive cache pre-positioning before campaign launches. We instrumented manifest hit rate, P99 glass-to-glass, and the end-to-end purchase funnel as a single live dashboard.
Outcome. Over €365M in lifetime sales driven through the platform’s live broadcasts. The architecture handles spikes from a few thousand concurrent in normal hours to large-campaign peaks without re-engineering. Read the Sprii project page or book a 30-min review if you’re building a similar product.
A decision framework — pick your trunk in five questions
1. What’s the audience peak? Under 10k — LL-HLS + CDN; over 100k — CDN-primary, WebRTC for contribution only.
2. What’s the latency budget? Sub-second — MoQ where deployable, WebRTC otherwise. 1–3 seconds — LL-HLS. More tolerable — standard HLS.
3. Is the audience interactive or one-way? Interactive — small WebRTC mesh; one-way — CDN trunk.
4. What licensing applies? Premium content with DRM or regulated broadcast — LL-HLS + SSAI is the proven path; reserve MoQ for unencumbered live.
5. How much engineering do you have? Two-pizza team — managed CDN + LL-HLS. Larger teams with on-call — multi-CDN with predictive cache warming.
Five pitfalls we see teams hit
1. Sizing the SFU for the audience. WebRTC SFU is for contribution and small interactive panels. Past 10k viewers, route through a CDN.
2. Single-CDN dependency. One incident on one CDN takes down the event. Multi-CDN with at-traffic failover is non-optional above 100k.
3. Skipping the load rehearsal. Capacity planning on paper is not capacity. Run a synthetic 1.2× load test against the live stack a week before.
4. Ignoring DRM token spikes. 1M viewers hitting the token endpoint at minute zero is a DDoS by accident. Edge issuance and burst-aware capacity planning fix it.
5. Treating SSAI as an afterthought. Ad timing across the bitrate ladder is the most common reason ads play silent or black. Validate frame-accurate marker handling before launch.
Reach for a multi-CDN egress when: the audience is the moneymaker, the event is one-shot, and the cost of a five-minute outage is bigger than the cost of a second contract. That’s most production live events above 100k.
KPIs to measure
Quality KPIs. P50 and P99 glass-to-glass latency by region. Rebuffering ratio (target under 0.5%). Manifest cache hit rate (target above 99%).
Business KPIs. Cost per viewer-hour all-in. Audience peak and 90th-percentile sustained concurrency. Customer-reported failure rate per 100k viewer-hours.
Reliability KPIs. Uptime against the SLA (target 99.99%). MTTR after an ingest failover. Successful DRM token issuance rate at minute zero.
When NOT to engineer for 1M concurrent
Most products will never see 1M concurrent. Building for it on day one is a great way to spend two quarters on capacity you don’t need. Build for the audience you have plus a 5× buffer; design the architecture so the jump from 100k to 1M is more capacity rather than a different stack.
There’s an exception. If your launch is tied to a known event — a championship final, a global product reveal, a celebrity-driven concert — treat the first event as the architecture target and rehearse the failover modes. The cost of an under-engineered launch is days of refunds and headlines.
Need a reference architecture and a load-rehearsal plan?
We deliver a working hybrid pilot — WebRTC contribution, LL-HLS broadcast, multi-CDN egress, observability — in 8–12 weeks. Bring the audience target.
FAQ
Can WebRTC scale to 1M concurrent viewers?
Not economically. Cascading SFU meshes can reach into the hundreds of thousands, but $/viewer-hour at that scale exceeds CDN-delivered LL-HLS by 5–15×. The right pattern is WebRTC for contribution and small interactive segments, LL-HLS or MoQ as the broadcast trunk.
What latency can I get with LL-HLS or MoQ at 1M scale?
LL-HLS lands at 1–3 seconds glass-to-glass on commodity CDNs. Production MoQ deployments (Cloudflare, WINK) hit 200–300 ms. Both scale to millions of concurrent viewers with the same egress economics; MoQ is the lower-latency lane where production-readiness allows.
How much does 1M concurrent really cost?
Around $120k–$345k for a one-hour event, depending on CDN contract terms, codec mix, DRM, SSAI, and on-call staffing. Most of it (60–80%) is CDN egress. Negotiated commits and multi-CDN strategies move the bill materially.
Should I use a managed service or build my own?
Below 100k concurrent — managed (Cloudflare Stream, Mux, AWS Elemental) is faster to ship and operationally cheaper. Above 100k with regular events — a hybrid where you control packaging and origin while leasing CDN capacity is usually best. Pure DIY at multi-million scale is the YouTube/Netflix playbook and requires a dedicated platform team.
How do I avoid the Netflix Tyson–Paul outcome?
Rehearse failover under full synthetic load. Add multi-CDN with traffic engineering. Cache manifests aggressively at the edge. Pre-warm regional caches before the event. Monitor manifest hit rate and segment availability in real time, with on-call escalation for thresholds. None of this is exotic; all of it has to be tested before the audience arrives.
When is MoQ the right choice over LL-HLS?
When you need the 200–300 ms latency band and your audience can play through WebTransport (browsers since March 2026 Baseline) or native QUIC. LL-HLS still wins for legacy SmartTV/STB compatibility, FCC-style regulated broadcast, and DRM-heavy premium content in 2026.
How long does a Fora Soft scaling engagement take?
A working hybrid pilot — WebRTC contribution, LL-HLS broadcast trunk, multi-CDN egress, monitoring — lands in 8–12 weeks via spec-driven agent engineering. Full production rollout with DRM, SSAI, multi-region failover, and load rehearsal is typically 12–20 weeks. Bring us the scope and we’ll quote on a call.
What about cost-per-GB at hyperscale — is $0.05 the right number?
List prices for AWS CloudFront, Fastly, and Akamai sit around $0.04–$0.085/GB depending on volume tier in 2025–2026. Negotiated commits at scale routinely move that to $0.01–$0.03/GB. Budget CDNs (Bunny, KeyCDN) sit at $0.01–$0.04/GB list. Use $0.05/GB for back-of-envelope; expect to negotiate down materially.
What to Read Next
MoQ deep dive
Building Applications with Media over QUIC
Architecture, latency, costs, and a hybrid migration playbook for live media.
DevOps
Traefik v3 — The Practical Reverse Proxy Guide for Docker in 2026
Traefik v3: the practical reverse-proxy guide for Docker.
Backend
How to Implement RabbitMQ Delayed Messages in 2026 (with Code)
RabbitMQ delayed messages, with working code examples.
WebRTC trade-offs
WebRTC vs Agora: Architecture Trade-offs
Build vs buy for the contribution side of your live stack.
Hiring
Hire a WebRTC Development Company vs Build In-House
A buyer’s guide for streaming and real-time video founders.
Build vs buy
Wowza Custom Development in 2026
A build-vs-buy analysis for low-latency streaming platforms.
Engineering practices
Real-Time Video Processing with AI
Architecture patterns and latency budgets from 250+ shipped video projects.
Ready to design for a 1M-viewer audience?
The protocols are well understood. The hard parts are the coordination, the failover, and the cost discipline. Build the hybrid — WebRTC for contribution, LL-HLS or MoQ for distribution, HLS for the long tail — size each tier honestly, rehearse the failure modes under load, and instrument the control plane so you find the issue before the audience does.
If you’re scoping a streaming product targeting six- or seven-figure audiences, the technology choices are shared. The architecture has to fit your audience curve, your latency budget, and your monetization. That’s the conversation we have with prospective clients on a 30-min scoping call — bring the constraints, leave with an architecture, a cost model, and a delivery estimate.
Talk to a team that has shipped 600+ video products
WebRTC, LL-HLS, MoQ, multi-CDN, DRM, SSAI — we know which tool fits which job at which scale. Bring the use case; we’ll bring the architecture and a delivery estimate.









