


.webp)
Key takeaways
• AI in software testing accelerates QA — if you fence it. 84% of developers use AI tools, but only 29% trust the output (Stack Overflow 2025). Without controls, AI generates more flaky tests than real coverage.
• Spend AI cycles where work is enumerable. Test-case generation, self-healing locators, predictive risk scoring, and bug-triage drafting are the four highest-ROI uses. Payback runs 4–7 months once you fund the human review pass.
• Keep humans on latency, security, and compliance. Sub-500 ms paths, HIPAA/GDPR/PCI tests, and exploratory hunches stay 100% human-owned. AI simulations don’t replicate real network jitter.
• Versioned specs are non-negotiable. Tests written against precise specs (“voice latency < 300 ms p95”) survive refactors. Tests written against vague requirements drift and rot.
• Watch for the 70% problem. AI gets to a working draft fast and stalls on the last 30% — the edge cases, error paths, and cross-cutting concerns. Coverage targets need to rise from 70–80% to 85–90% on AI-generated code.
Why Fora Soft wrote this AI-in-QA playbook
We ship multimedia and AI products into production every week. Live shopping, telehealth, courtroom video, AI surveillance, e-learning — all systems where a flaky test or a missed regression turns into a customer-facing outage in seconds. We’ve built this playbook by running our own QA organization on it: AI in the seats where it pays back, humans in the seats where it can’t. Fora Soft has shipped 250+ products since 2005, and AI in software testing is now part of how we hit our defect targets.
Concrete proof: we built the QA pipeline for BrainCert (a WebRTC LMS handling thousands of concurrent learners), TransLinguist (live interpretation across 75+ languages), Sprii (a live shopping platform with €365M+ in sales), and Meetric (an AI sales video platform).
Our bias: we don’t care which AI testing vendor wins; we care about defects-per-release, mean-time-to-detect, and engineering hours saved net of test maintenance. The framework below is what survived two years of running it on real product teams.
Setting up an AI-augmented QA pipeline?
We’ll sketch the architecture, the human-in-the-loop gates, and the ROI math for your product in a 30-minute call.
The 2026 trust gap: why teams use AI but don’t trust it
The 2025 Stack Overflow Developer Survey reports 84% of developers using or planning to use AI tools, while only 29% trust the output — down 11 points from the year before. More developers actively distrust AI accuracy (46%) than trust it (33%). The dynamic in QA is the same: easy adoption, slow trust. And most of the AI in software testing that matters in 2026 is generative AI — large language models writing test cases, repairing locators, and drafting triage notes.
In testing, that distrust is earned. AI can generate thousands of test cases in an afternoon. It can also generate a regression suite that’s 70% green and 30% silent failure — tests that assert the wrong properties, hard-code timestamps, or paper over real timing bugs. GitClear’s 2025 analysis of 211 million changed lines found that code blocks with 5+ duplicated lines rose 8× during 2024, while code churn — lines revised within two weeks of authoring — roughly doubled from a pre-AI 3.3% to 7.1% in 2025. That’s technical debt the AI created, and some of it lands in your test suite.
The fix isn’t less AI in QA. It’s a clear separation of what AI does and what humans own — with the contract written down before anyone runs a test generator.
The four-level model: who owns what in an AI-augmented QA pipeline
We organize AI usage in QA across four levels. Each one defines what AI does and what humans own. The boundary is the point of the framework — without it, AI silently expands into roles it’s not ready for.
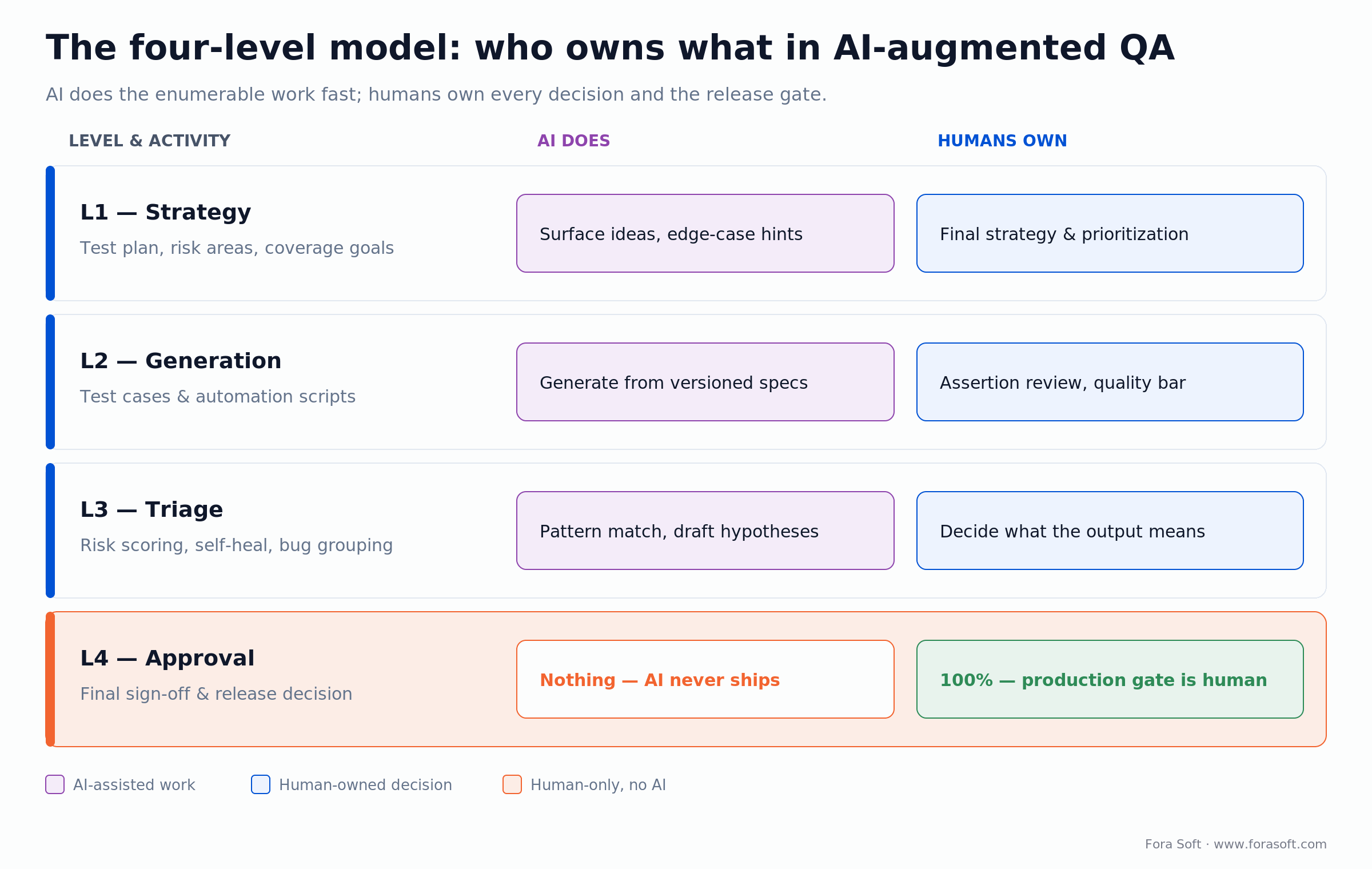
Figure 1. The four-level model. AI does enumerable work at L1–L3; humans own every decision, and the L4 release gate is human-only.
| Level | Activity | AI does | Humans own |
|---|---|---|---|
| L1 — Strategy | Test plan, risk areas, coverage goals | Surface ideas and edge-case suggestions | Final strategy and prioritization |
| L2 — Generation | Test cases and automation scripts | Generate from versioned specs | Quality criteria, assertion review |
| L3 — Triage | Risk scoring, self-healing, bug grouping | Pattern matching, draft hypotheses | Decisions about what the output means |
| L4 — Approval | Final sign-off and release decisions | Nothing — AI never owns ship/no-ship | 100% — production gates are human |
The through-line: AI earns its keep doing structured, enumerable work fast. It does not own decisions. Everything starts from written, version-controlled specifications — the same principle behind our architecture validation workflow.
Where AI genuinely moves the needle in QA
Four generative-AI use cases in software testing pay back inside two quarters on every team we’ve deployed them on. The pattern: structured input, enumerable output, human-readable artifact for review. Each one lives at L2 or L3 of the model, with a human gate right behind it.

Figure 2. The pipeline in practice. Specs feed AI generation; a human assertion-review gate sits before CI, and release sign-off stays human.
1. Test-case generation from versioned specs
Feed the AI user stories, performance targets, and compliance requirements; get back functional tests, edge cases, negative scenarios, and load plans — in plain language a QA engineer can review and extend. On one authorization module we shipped, AI generated 312 test cases from 25 user stories in roughly two hours. Boundary-condition coverage went from 68% to 91% after human review, and the same pass surfaced 7 logical contradictions in the requirements before a line of code was written.
Reach for AI test generation when: your specs are versioned, you have a senior QA engineer for the review pass, and the module under test is reasonably enumerable.
2. Self-healing automation suites
In WebRTC and video apps, layouts and bitrate logic shift every sprint. Static automation breaks every time. AI tools that watch screen patterns and auto-repair locators (Mabl, Testim, Functionize, Applitools’s Eyes) report 85–95% repair success with multi-locator strategies, vs 30–50% for single-locator approaches. On one e-learning platform with weekly UI updates and up to 2,000 concurrent students, this dropped maintenance from days of rework to minutes of verification.
Reach for self-healing when: your UI changes weekly or faster, your test suite has > 200 E2E flows, and human engineers will still confirm each repair didn’t mask a real regression.
3. Predictive risk scoring
AI digests past test results, recent code changes, and production logs, then highlights where risk is highest. For a video surveillance platform running 24/7 across hundreds of organizations, this meant the team focused testing pressure on the media pipeline under 5% packet loss and mass-reconnect scenarios — not distributing effort evenly. Vague “not enough information” bug reports dropped 33% and average triage time fell from 45 minutes to 18.
Reach for predictive risk scoring when: you have observability data with at least 6 months of history and the team can act on prioritization signals quickly.
4. Smart bug triage and ticket drafting
AI reads stack traces, logs, and screenshots, proposes likely root causes, drafts tickets with reproduction steps, and groups related failures. Engineers add context and confirm before work begins. On a high-volume backend ingesting real-time social-survey data (10,000+ log lines per second through Elastic and Datadog), AI formed 3–5 probable root-cause hypotheses per incident, cutting the noise engineers had to parse before acting.
Reach for smart bug triage when: incident volume is high, observability is mature, and engineers spend > 30 minutes per incident parsing logs before they can act.
Where we deliberately don’t use AI
Latency-critical path validation. Sub-300 ms voice and sub-500 ms video are sensitive to network jitter, device variation, and background load. AI simulations don’t replicate real conditions; only engineers reviewing live telemetry can sign off. A simulation that passes is not evidence the real system will.
Security and privacy testing. End-to-end encryption, audit logging, key exchange, HIPAA, GDPR, PCI-DSS, SOC 2 — these require deep threat modeling and clear accountability. Veracode’s 2025 GenAI Code Security Report found AI introduces a security vulnerability in 45% of cases across 100+ models and 80 tasks, and Snyk’s 2025 report found 80% of teams bypass their own AI security policies. Compliance domains are not where you want a 45% miss rate. AI can suggest test scenarios; humans design, run, and validate.
True exploratory testing. AI can list scenarios; the adaptive investigation — following hunches, combining observations, asking “what would actually break this?” — is human work. On a mobile WebRTC calling app, an AI-assisted exploratory pass surfaced 42 stress cases (low-bandwidth plus screen rotation during a session drop, things like that) and 11 defects standard checklists missed. The AI proposed scenarios; engineers ran them.
Final release sign-off. AI never owns ship/no-ship. The audit trail required by clients in regulated industries (and increasingly by enterprise procurement) requires a named human signature.
The 70% problem and what to do about it
AI gets to a working first draft fast and stalls on the last 30% — the edge cases, error handling, and cross-cutting concerns where most real complexity lives. In test generation specifically, research on LLM-generated unit tests reports mutation scores well below the 80%+ a competent human-authored suite hits; systematic generators such as EvoSuite reach roughly 50–60% coverage, while raw LLM output can feel like a quick scan.
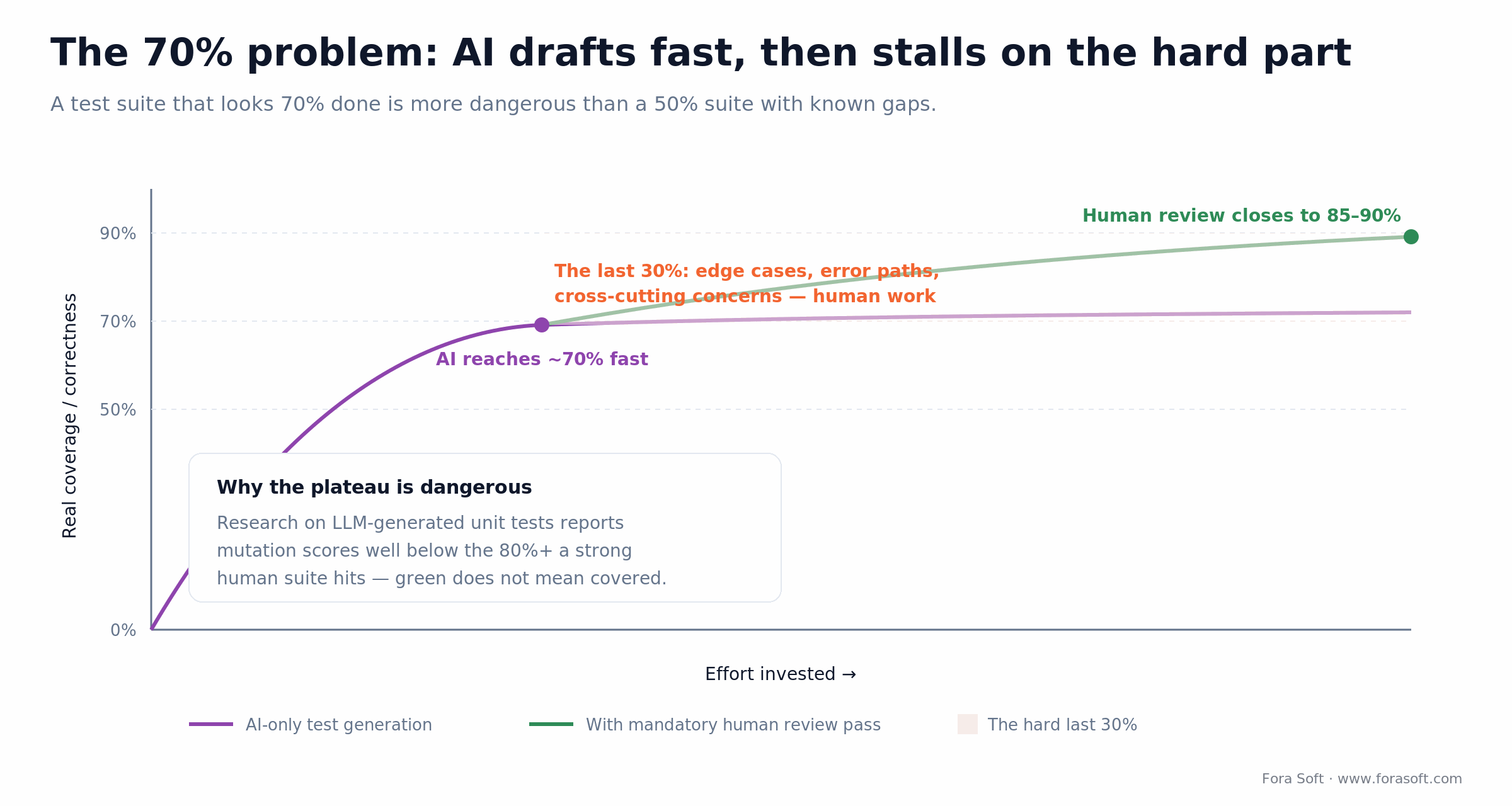
Figure 3. AI test generation rises fast to ~70% real coverage, then plateaus. The mandatory human review pass closes the hard last 30%.
A test suite that covers 70% of requirements confidently is more dangerous than a 50% suite where the gaps are known — engineers trust it more than they should. We treat this with three concrete moves:
1. Higher coverage targets on AI-authored code. Where 70–80% line coverage was the bar, we lift to 85–90% on AI-generated code, plus mutation-testing thresholds (60%+ mutant kill rate).
2. Mandatory human pass on assertions. Coverage isn’t correctness. Engineers verify what each AI-generated test actually asserts — particularly around timing, ordering, and error paths.
3. Comprehension-debt reviews. Once a quarter, an engineer who didn’t write the tests reads them cold. If they can’t explain why each test exists, the test is suspect — that’s the “comprehension debt” pattern Addy Osmani named: code that looks correct but breeds false confidence.
Worried your AI-generated tests are hiding bugs?
A 30-minute audit of your suite usually surfaces the silent-failure tests in 10 minutes. We’ll do it on a call.
Versioned specifications: the single biggest predictor of AI-QA success
If we had to pick one variable that determines whether AI in software testing pays back or accumulates debt, it’s the quality of your specifications. Tests written against precise, version-controlled specs (“voice latency must stay under 300 ms at p95,” “system must survive 5% packet loss without dropping calls”) survive refactors. Tests written against vague requirements break with every sprint and rot into noise.
A workable spec for AI input has four properties: a measurable acceptance criterion, an explicit input/output example, a failure mode the test must catch, and a version number. Without those four, the AI is guessing — and brilliant guesses still produce flaky tests.
We treat the spec corpus as a first-class artifact: it lives in Git, it gets reviewed, it changes with the same discipline as production code. When clients tell us their AI tests are flaky, the spec corpus is the first place we look — and 8 times out of 10 the answer is there.
Realtime and video products: what AI in QA can and can’t do
WebRTC and live-streaming products break the assumptions of most general-purpose AI testing tools. Latency is sensitive to network conditions the AI can’t simulate. Adaptive bitrate decisions depend on real device hardware. Multi-party synchronization — the “everyone-sees-the-same-thing-within-200 ms” constraint — sits outside the training data of every commercial QA platform.
What AI handles well in video products. Functional regression on the UI layer (login, room join, chat, billing flows). Visual diff on player chrome and controls. Load-test orchestration: AI plans realistic chaos — traffic spikes, long-duration soak runs, reconnect storms after brief outages — and we execute on real infrastructure.
What AI does not handle. Sub-500 ms latency assertions on the live path. Codec compatibility across actual devices. Cross-region jitter and packet-loss behavior. Audio echo, drift, and lip-sync — all of which need human ears.
For the engineering context your AI tests have to validate, see our AI for video engineering hub and our WebRTC hiring playbook. If you’re scaling these systems, our 1M-viewer scaling guide covers the layer your test suite is designed against.
Compliance, audit trails, and the AI black box
In regulated industries — HIPAA, GDPR, PCI-DSS, SOC 2 — auditors don’t accept “the AI passed the test” as evidence. They want a named human signature, a documented review trail, and reproducible artifacts that map each test to a specific control.
Use AI for: functional regression on non-PHI / non-PII flows, visual regression, accessibility scanning (WCAG checks), and bug-report drafting that humans then review and submit.
Keep AI off: encryption verification, audit-log integrity tests, access-control matrix validation, retention/deletion flow validation, and anything tied to a regulatory control. The audit trail must be human-authored.
For HIPAA-bound video products (telehealth, courtroom, medical imaging), we keep all PHI-touching test scenarios on a separate branch with manual sign-off, and the AI never sees the actual data — only synthetic, structurally-equivalent fixtures. That separation is the price of regulatory clearance.
The 2026 tooling shortlist
After running pilots on most of the field, six tools earn a place in the kit. We pick by what part of the four-level model they cover — and we’ll mix two or three on a given project rather than betting on one platform. Most vendors quote rather than publish, so the figures below are 2026 third-party estimates; confirm your own tier before you budget.
| Tool | Strength | Level fit | Pricing (2026, est.) |
|---|---|---|---|
| Mabl | Agentic E2E from natural-language specs | L2 generation, L3 self-heal | Quote; Starter ≈ $499/mo |
| Testim (Tricentis) | ML-based smart locators, mature self-heal | L2 / L3 | Free tier; paid on Tricentis quote |
| Applitools Eyes | Visual AI — pixel-level regression detection | L3 visual diff | Free 100 checks/mo; ≈ $399/mo for 1,000 |
| Percy (BrowserStack) | Visual diffs, generous free screenshot tier | L3 | Free 5,000 shots/mo; then per-screenshot |
| Claude Code / Cursor / Copilot | Agentic test generation in the IDE | L2 unit + integration | $20–200/seat/mo |
| Functionize | Self-healing E2E at enterprise scale | L3 | Quote (enterprise) |
For how agentic AI is changing the broader development cycle (not just QA), see our video AI agents guide. When you want a partner to wire one of these stacks into your product, that’s our AI integration service.
Cost model: what AI in QA actually costs
A worked example. A 12-engineer product team running a moderate AI-augmented QA stack — agentic test generation, self-healing E2E, visual regression, predictive risk — for a year.
| Line item | Tool | Annual |
|---|---|---|
| Agentic E2E + self-heal | Mabl or Testim | $15K–30K |
| Visual regression | Percy or Applitools | $6K–20K |
| IDE coding agents | Claude Code / Cursor / Copilot × 12 seats | $3K–30K |
| Risk scoring + observability tie-in | Datadog / Sentry / homegrown | $5K–15K |
| Total | — | ≈ $30K–95K / year |
Our own measured payback on real teams is 4–7 months once you include the human-in-the-loop overhead — the review hours that keep AI output honest. We don’t quote the four-digit ROI percentages the vendor decks like; the number that actually moves is engineer-hours saved net of test maintenance, and that only turns positive when a senior reviewer is in the loop.
The mistake we see most often is buying tooling without funding the human review pass. A $50K AI tool stack that saves a senior QA engineer’s time only matters if you actually have the engineer to do the review — otherwise you’re paying to generate technical debt at scale.
Decision framework: pick your AI QA approach in five questions
Q1. Are your specifications versioned? If no, fix that first. AI-generated tests against vague specs are noise. Versioned specs are the input that makes everything downstream useful.
Q2. What’s your release cadence? < 1 release/week: agentic E2E pays back in 6–9 months. Daily releases: self-heal plus visual regression are essential, payback in 3–5 months. Continuous deployment: full L2–L3 stack, payback < 3 months.
Q3. What’s your compliance posture? HIPAA / GDPR / PCI / SOC 2 in scope: keep AI strictly off the audit trail. Functional regression and visual diff are fine; security and privacy stay 100% human.
Q4. Do you have a senior QA engineer to own the review pass? No: don’t buy AI tooling yet. Yes: full L2–L4 model. The mid-zone — one mid-level QA — is where projects accumulate hidden debt.
Q5. Is realtime / latency-critical behavior in scope? If yes (WebRTC, video, telemetry, trading systems), your AI coverage caps at functional and visual layers; latency paths stay manual on real hardware.
Mini case: how AI cut a streaming-platform release cycle in half
Situation. A live fitness streaming platform serving thousands of concurrent users (similar in shape to Vodeo) had a 3-week release cycle dominated by manual regression. Each cycle, two QA engineers spent 5–7 days repairing broken UI tests after sprint changes. Major features were delayed or shipped without full regression coverage.
12-week plan. We replaced their static automation with Mabl-driven E2E built from versioned specs, layered Percy for visual regression, and added a homegrown risk-scoring layer that pulled signal from their Datadog/Sentry feeds. We kept latency-critical paths (sub-500 ms video start, mid-stream resolution switches) on manual plus load testing — AI never touched the live-path validation. Senior QA owned the review pass on every AI-generated assertion.
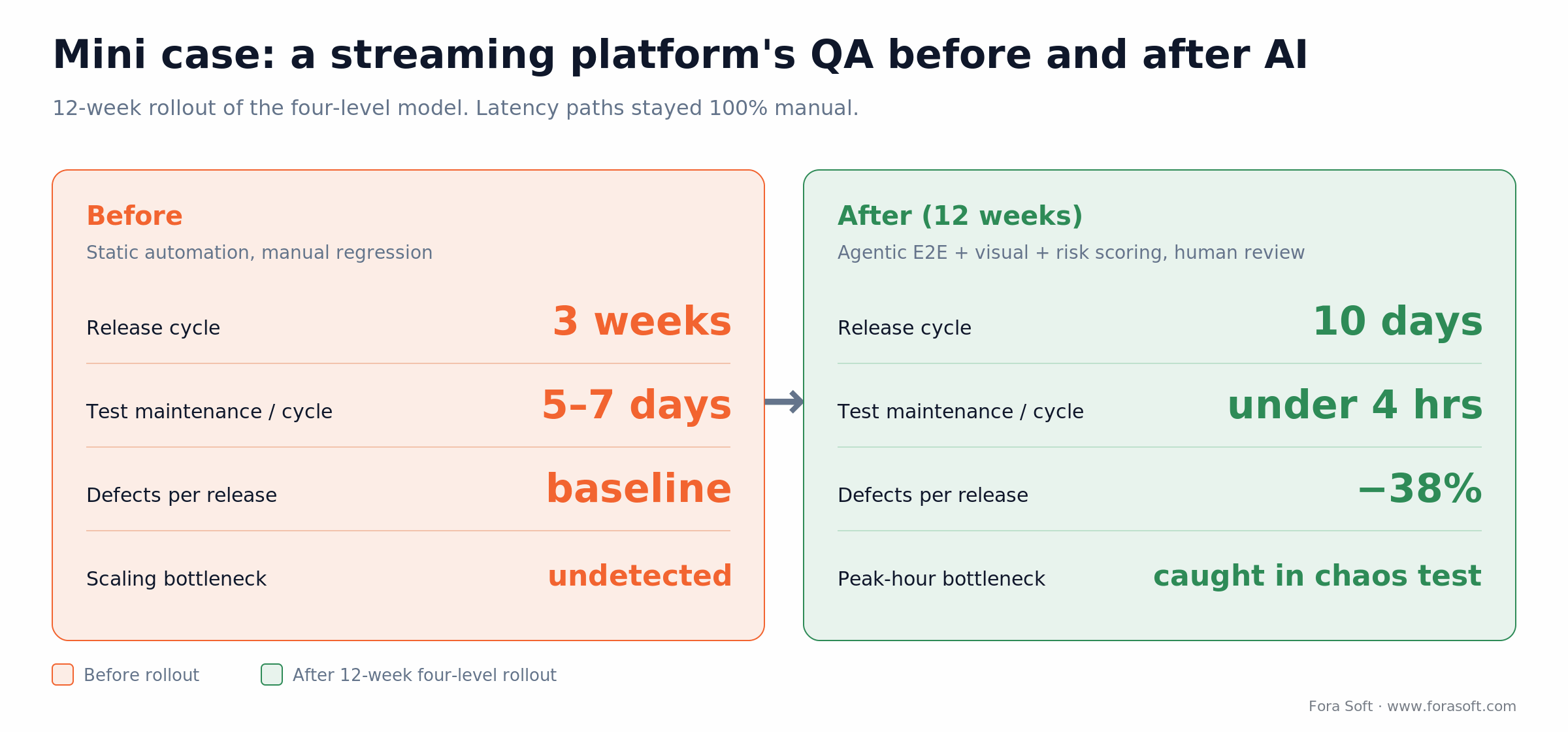
Figure 4. Before and after the 12-week four-level rollout. Latency paths stayed 100% manual throughout.
Outcome. Release cycle dropped from 3 weeks to 10 days. Test maintenance fell from 5–7 days per cycle to under 4 hours. Production defects-per-release dropped 38%. The platform caught a scaling bottleneck during AI-generated chaos testing — one that only appeared at peak workout hours when simultaneous joins combined with adaptive bitrate switching. Manual test design hadn’t surfaced the interaction. Want a similar assessment? Book a 30-minute call.
Five pitfalls we keep seeing in production
1. False confidence from green builds. AI-generated tests pass at 95%+ rate by default; that’s a property of how they’re generated, not a sign your code works. Mutation-test your suite quarterly. If you can’t kill 60% of mutants, your tests are decorative.
2. Self-heal hiding real regressions. Self-healing locators are maintenance automation, not bug detection. If a test “auto-fixed” itself by relocating to a new selector, an engineer needs to confirm the underlying behavior didn’t silently change. Otherwise self-heal becomes a regression-eraser.
3. Coverage targets without correctness checks. 90% line coverage with weak assertions ships the same defects as 50% coverage with strong assertions. Code-review the assertions, not just the count.
4. AI-authored security tests. With AI introducing a vulnerability in 45% of cases (Veracode 2025), letting AI write its own security tests creates a feedback loop of false confidence. Security tests are written, reviewed, and signed off by humans — period.
5. Buying tooling without budgeting human review hours. Every hour of AI-generated tests needs 10–20 minutes of senior-engineer review. Skip it and a productivity gain turns into accelerated debt: GitClear’s data shows AI-assisted teams saw an 8× jump in duplicated code blocks — that didn’t happen by accident.
KPIs to track once you ship
Quality KPIs. Mutation-test mutant kill rate (target ≥ 60%), production defect rate per 1,000 LOC (track the YoY trend), escape defects (caught after release vs before), and mean-time-to-detect for production incidents. These are the metrics that tell you whether your AI tests find bugs or just pass.
Business KPIs. Release cycle time (target < 50% of the pre-AI baseline), QA hours per release (target < 30% of pre-AI), tooling spend tracked monthly against hours saved, and customer-reported defect rate. If these don’t move within two quarters, the implementation is wrong — not the technology.
Reliability KPIs. Test-suite flakiness rate (target < 5%; the share of teams hitting flaky tests climbed from 10% in 2022 to 26% in 2025, per Bitrise), self-heal success rate (target > 85%), false-positive visual-regression rate (target < 15%), and time-to-triage for new failures (target < 15 minutes from first signal to actionable hypothesis).
When NOT to add AI to your QA pipeline
There are three scenarios where we tell clients to wait.
You don’t have versioned specifications yet. AI-generated tests against vague requirements drift instantly. Fix the spec process before adopting the tooling.
Your test suite is < 500 tests total. Below that scale, the human-in-the-loop overhead eats the time savings. Ship more product first, then revisit at the next inflection point.
You’re in a heavily regulated domain with no engineering bandwidth for review. Healthcare, financial trading, courtroom video — if there’s nobody senior enough to own the AI review pass, the risk-adjusted ROI is negative. Hire first, automate second.
How to benchmark your AI-augmented QA setup
Marketing demos will tell you the time saved on test generation. They won’t tell you what’s slipping past in production. Use a small held-out evaluation set — 30–50 known-bug commits from your own history — and run them through the AI-augmented suite to see how many it catches.
Detection rate target. If AI-augmented testing catches < 75% of the held-out bugs, the suite is decorative. Push past 90% before declaring victory.
Mean-time-to-detect. First signal to actionable hypothesis under 15 minutes is a healthy bar; over 60 minutes, your triage step is broken.
Maintenance cost per test. Track engineer-minutes per test per quarter. AI-augmented suites should run < 10 minutes per test per quarter; legacy automation runs 30–60.
FAQ
What is AI in software testing?
AI in software testing means using machine learning and generative AI to do the enumerable parts of QA — generating test cases from specs, repairing broken locators, scoring risk, and drafting bug tickets — while humans keep the strategy, the security and latency validation, and the release sign-off. It speeds up structured work; it does not replace judgment.
How much faster does AI make test creation?
Days to hours, in most cases. On one authorization module we shipped, AI generated 312 test cases from 25 user stories in roughly 2 hours; manual effort would have taken 2–3 days. After human review, boundary-condition coverage rose from 68% to 91%, and the same pass surfaced 7 logical contradictions in the requirements before development began.
What is self-healing in software testing?
Self-healing uses AI to detect UI changes and automatically update broken locators, fixing moved buttons, renamed selectors, and updated flows. Multi-locator strategies (Mabl, Testim, Functionize) report 85–95% repair success vs 30–50% for single-locator tools. Human engineers still review the AI’s repairs to confirm nothing meaningful changed.
Why require human final validation for latency-critical paths?
Sub-300 ms voice and sub-500 ms video are sensitive to network jitter, device variation, regional infrastructure, and background load. AI simulations are useful for modeling but cannot substitute for engineers reviewing live telemetry. Human sign-off prevents regressions that only appear at the edge of real conditions.
Can AI handle security or privacy testing on its own?
No. Security (E2EE, key exchange, vulnerability scanning) and privacy (HIPAA, GDPR, audit trails) require threat modeling, legal accountability, and human judgment about acceptable risk. Veracode’s 2025 report found AI introduces a security vulnerability in 45% of cases. AI can suggest scenarios; humans must design, execute, and validate them.
How does AI support exploratory testing without replacing human testers?
AI can suggest scenarios, propose input variations, and surface patterns from past failures, giving testers a structured starting point. The adaptive investigation — following hunches, combining observations, asking “what would actually break this?” — stays human-driven. AI contributes breadth; testers contribute judgment.
Does AI in QA actually prevent technical debt or create more of it?
Both, depending on discipline. With versioned specs, human strategy, and final review, AI catches inconsistencies before code is written, keeps test suites maintainable, and improves bug-report quality. Without those controls, GitClear’s data shows AI-assisted teams produced an 8× rise in duplicated code blocks and a doubling of code churn — debt the AI created.
What’s the typical ROI on AI in QA tooling?
Our measured payback on real teams is 4–7 months when you account for human-review overhead. A moderate stack runs roughly $30K–95K/year for a 12-engineer team. The return depends entirely on having a senior engineer in the review seat — without that, the ROI inverts and you pay to accumulate debt.
How long does it take to integrate AI into an existing QA pipeline?
A self-heal plus visual-regression layer typically takes 4–6 weeks to deploy and stabilize. A full agentic L2–L3 stack (Mabl/Testim + Percy + IDE coding agents + risk scoring) runs 8–12 weeks including team training and metric baselining. With Agent Engineering, our delivery is meaningfully faster than typical agency timelines.
What to read next
Architecture
Scale video streaming to 1 million viewers
The architectural layer your AI-augmented test suite has to validate.
Video AI
How video AI agents work in 2026
Architecture, latency budgets, and per-minute economics of video AI agents.
LiveKit
Building multimodal AI agents with LiveKit
Voice, vision, and production deployment patterns we test against.
Edge AI
Edge AI vs Cloud AI for video
Latency and cost trade-offs that drive your test architecture.
Hiring
When to hire a WebRTC development company
Build-vs-hire decision framework for the realtime layer your QA tests.
Ready to deploy AI in QA without creating debt?
AI in software testing is a force multiplier exactly when you can specify what you want. Versioned specs, the four-level model, mandatory human review on assertions, and explicit fences around latency-critical and security-sensitive paths — that’s the framework. Skip any one of those, and you’re paying SaaS prices to generate technical debt.
If you want a sanity check on your current setup — or a 12-week plan to install the four-level model on a real product team — we’ll do the work with you. Twenty-one years of multimedia and AI engineering, 250+ shipped products, 100% Upwork success, Agent Engineering for faster delivery. Bring the messy reality; we’ll bring the framework that fits.
Want a custom AI-augmented QA pipeline?
We’ll scope it, price it, and ship it — with the human-in-the-loop gates that keep production safe.









