



Key takeaways
• WebRTC is the default transport for OpenAI’s Realtime API in 2026. WebSocket and SIP still ship, but WebRTC delivers 220–400 ms time-to-first-audio versus 350–700 ms on WebSocket round-trips.
• An SDK wins below ~2 million participant-minutes per month. LiveKit Cloud, Agora and Daily Bots ship a working ChatGPT streaming integration in days, not quarters.
• Custom WebRTC pays off above ~5 million minutes/month or under strict compliance. Self-hosted LiveKit OSS or mediasoup on Hetzner/AWS lands closer to $0.001–$0.002 per minute.
• Latency is not the differentiator. Control is. Both routes hit conversational latency; the choice is about codecs, observability, HIPAA boundaries and unit economics.
• You almost never need to fork a transport. Most teams ship faster by tuning VAD thresholds, barge-in handling and TURN placement than by rewriting an SFU.
Why Fora Soft wrote this playbook
We’ve been shipping real-time video and voice products since 2005, with 250+ live products, including LiveKit, mediasoup, Agora and Twilio stacks. In the last 18 months we’ve embedded OpenAI’s Realtime API into live shopping, telehealth, courtroom interpretation and AI tutoring products. The same question keeps coming up in scoping calls: do we wire ChatGPT into a managed WebRTC SDK, or build our own transport?
This playbook is the answer we wish we’d had two years ago. It synthesises what we learned shipping Sprii’s live shopping platform (€365M+ in sales, 21M products sold), BrainCert’s WebRTC LMS (100K+ customers, $3M ARR), TransLinguist’s NHS-grade interpretation, and Career Point’s Oxford-backed AI coaching MVP.
If you’re evaluating ChatGPT streaming integration for your product, the rest of this article gives you the verdict first, then the math, the architecture and the pitfalls. Skip to the five-question decision framework if you’re short on time.
Wiring ChatGPT into your live product?
Bring your architecture sketch — we’ll tell you in 30 minutes whether to build custom WebRTC or stay on an SDK.
The ChatGPT streaming integration decision in one paragraph
Pick a managed WebRTC SDK (LiveKit Cloud, Agora Conversational AI or Daily Bots) plus OpenAI’s Realtime API if you’re below ~2 million participant-minutes per month, you don’t need novel codecs or custom turn-taking, and your compliance team is happy with a third-party SFU in the path. Pick custom WebRTC (LiveKit OSS, mediasoup or Pion) when you cross ~5 million minutes/month, when audit logs need to live entirely on your infrastructure, or when your product depends on non-standard signalling, mixing or AV1. Everything in between is a judgement call that comes down to the five questions in section 13.
A useful sanity check: at the SDK price point of roughly $0.004 per audio track-minute (LiveKit Cloud) the SFU bill is rounding error next to OpenAI’s ~$0.06–$0.10 per voice-minute on the gpt-realtime-2.1 family. Optimising the SFU before you’ve optimised tokens is almost always premature.
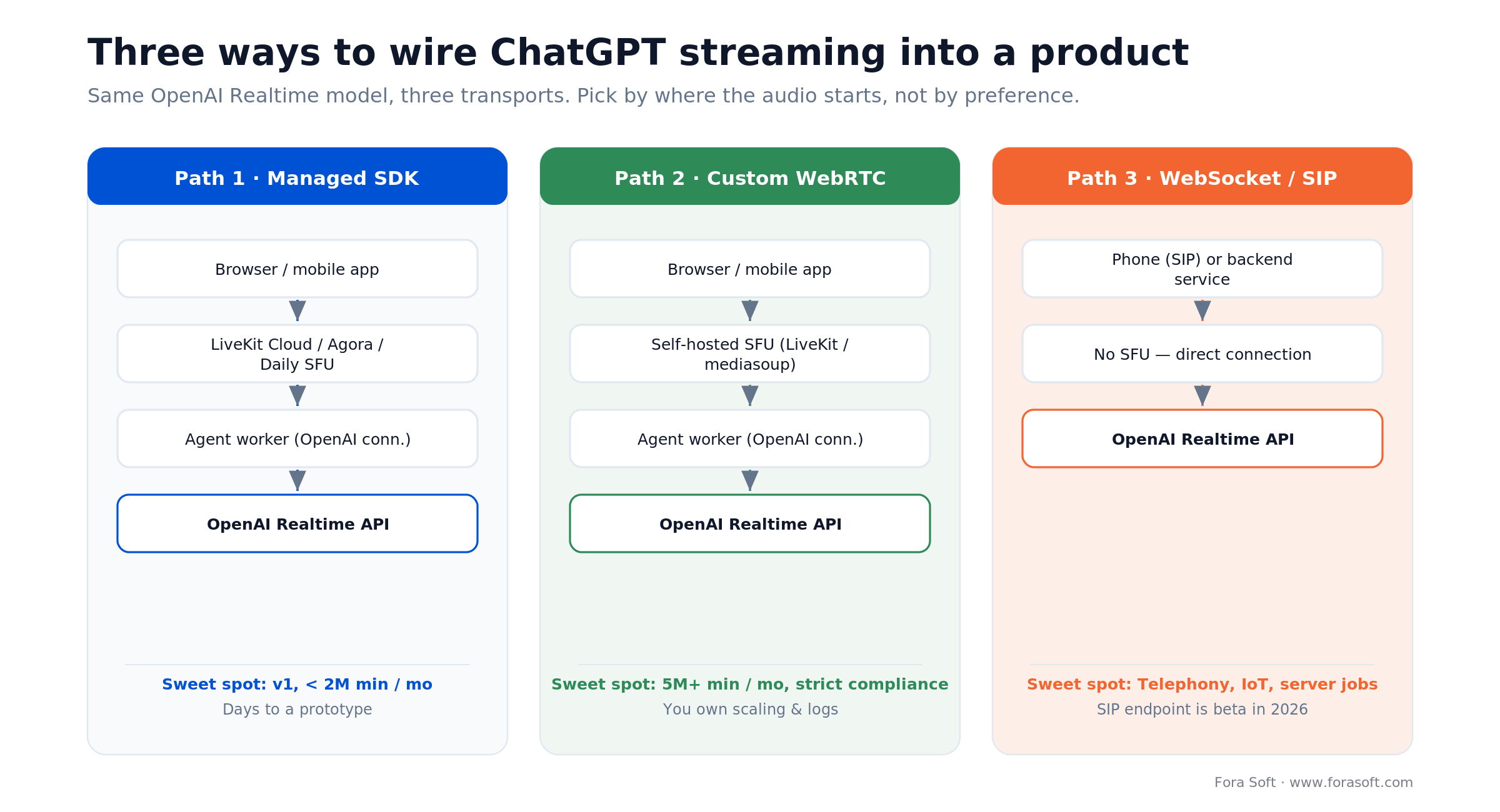
Figure 1. The three ChatGPT streaming integration paths and where each one fits.
What “ChatGPT streaming integration” actually means in 2026
Three different things hide under the same phrase, and conflating them is the most common reason for bad scoping calls.
1. Token streaming over HTTP. The classic chat completion endpoint, returning text chunks as they generate. Useful for chat UIs and copilots, and it’s the SSE token-streaming most people first picture when they hear “ChatGPT streaming.” This article is about the real-time voice kind instead.
2. Realtime API over WebSocket. A single bidirectional WebSocket between your server and OpenAI, carrying audio frames and JSON events. Perfect for server-side telephony bridges, IVR replacements and any case where the user isn’t on a browser.
3. Realtime API over WebRTC. A peer connection negotiated between the user’s browser/app and OpenAI’s edge, with audio packets travelling over UDP/SRTP. This is what you want for any in-app voice feature, AI co-pilot inside a video call or live shopping host with a ChatGPT-powered second brain. OpenAI documents the SDP handshake in its Realtime WebRTC guide.
Reach for the WebRTC mode when: the human is on a browser or mobile app, you need barge-in within 200 ms, and you can stomach a thin client-side SDK that exchanges SDP with OpenAI.
Why low-latency transport matters for ChatGPT streaming
For voice agents, the published research (and our own A/B tests) keeps converging on the same threshold: under ~550 ms of end-to-end latency a conversation feels natural; above ~800 ms users start repeating themselves. WebRTC’s SRTP path keeps you in the lower band; a WebSocket round-trip from a mobile client to your backend and back to OpenAI usually doesn’t. If terms like SRTP and Opus are new, our digital video and audio foundations primer is a fast catch-up.
Latency budgets we use as defaults when scoping a ChatGPT streaming integration:
- Mic capture & encoding: 20–40 ms
- Client → SFU → OpenAI edge: 40–120 ms (depends on TURN placement)
- Voice activity detection & turn detection: 80–200 ms (configurable)
- Model first-token: 150–300 ms on gpt-realtime-2.1, <100 ms on gpt-realtime-2.1-mini
- Audio decoding & playout: 20–60 ms
That’s a 310–720 ms range before you’ve added any retries or jitter. WebRTC keeps you safely on the left side of that range; HTTP-only or chained WebSocket bridges push you to the right.
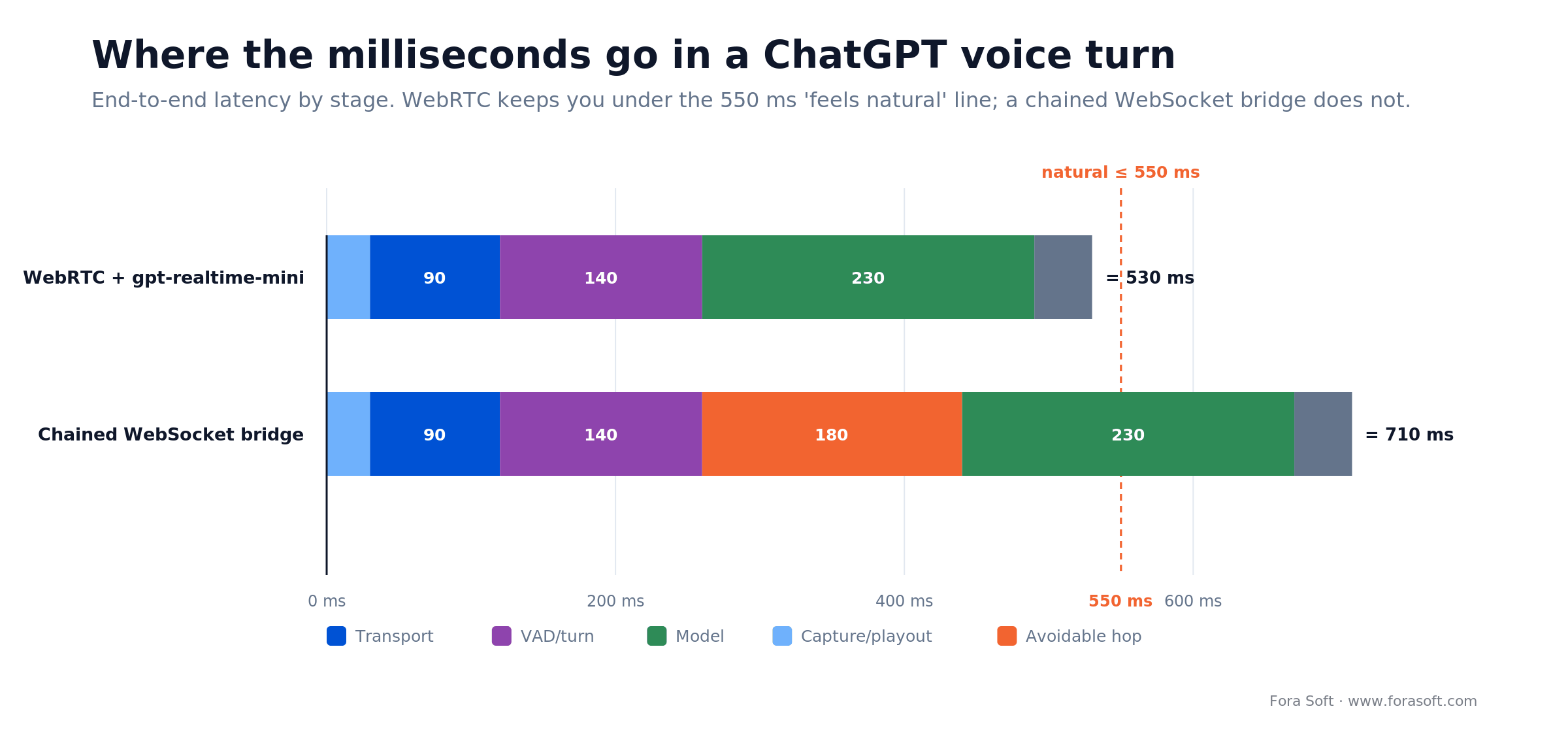
Figure 2. Stage-by-stage latency: WebRTC stays under the 550 ms conversational line; a chained WebSocket bridge does not.
Need a latency budget for your stack?
We can map your current architecture, identify the stages costing you 100 ms+ each, and quote a hardening plan in one call.
The three integration paths compared
Every ChatGPT streaming integration we’ve shipped fits one of three patterns. Each gets its own H2 below; this section is the at-a-glance summary. For the transport-level wiring itself, see our OpenAI Realtime WebRTC, SIP & WebSockets integration guide.
Path 1 — SDK in the path. A managed WebRTC vendor (LiveKit Cloud, Agora, Daily) does the heavy lifting. You write a thin agent worker that holds the OpenAI connection. Days of work to a working prototype.
Path 2 — Custom WebRTC. You operate your own SFU (LiveKit OSS, mediasoup, Pion) on Hetzner, AWS or GCP. Same agent worker, but your team owns scaling, TURN, recording and observability.
Path 3 — WebSocket or SIP only. No SFU. The user’s phone (via SIP) or your backend (via WebSocket) talks directly to OpenAI. Fine for telephony and server-side use cases; rarely the right call for in-app voice.
Path 1 — OpenAI Realtime + managed WebRTC SDK
This is the default 80% of teams should pick first. The managed SDK terminates the WebRTC peer connection close to the user, runs an “agent” worker (a small server process that holds the OpenAI WebSocket on the server side), and forwards audio frames in both directions. The user’s browser only knows it’s in a normal video room.
LiveKit Cloud + Agents
The most ergonomic option in 2026. The livekit-plugins-openai package gives you an AgentSession wired to a RealtimeModel that handles VAD, turn detection, barge-in and transcript synchronisation in well under 100 lines of Python. Pricing is roughly $0.004 per audio track-minute on Cloud, with a generous 5K minutes/month free tier and identical APIs whether you stay on Cloud or self-host. The current worker API is documented in the LiveKit Agents docs.
Agora Conversational AI Engine
Strongest pick when speakerphone audio quality matters: Agora’s noise suppression and selective-attention locking outperform open-source DSP in noisy retail or in-car settings. Pricing is competitive at roughly $0.99 per 1,000 participant-minutes (about $0.001/min) for audio, in the same ballpark as LiveKit Cloud once you account for participant-vs-track billing. The noise stack is the real reason to reach for it.
Daily Bots
A bring-your-own-keys orchestration layer. You wire OpenAI Realtime, Cartesia for TTS, Deepgram for STT and Daily for transport, and the framework keeps them in sync. Worth it when you want to swap models without rewriting your client.
Reach for an SDK when: you’re shipping a v1 in <90 days, you don’t have a WebRTC ops team, and your monthly minutes are below seven figures.
Path 2 — OpenAI Realtime over custom WebRTC
Same architecture as Path 1, but the SFU runs on hardware you control. The agent worker still talks to OpenAI over a server-side WebSocket; what changes is who pays the SFU bill and who carries the audit logs.
LiveKit OSS
Apache 2.0, written in Go, ships the same agent SDK as the Cloud version. A four-node cluster on Hetzner AX-series easily handles 1,000+ concurrent voice agents. The path of least resistance for teams who like the Cloud DX but want to own the data plane. Read our deeper take in the LiveKit AI Agents step-by-step guide and the 2026 voice AI guide.
mediasoup
Best raw performance: roughly 500 consumers per CPU core, twice what an unoptimised LiveKit cluster delivers. Worth the extra integration effort when you’re building large multi-party rooms with several AI participants per call.
Pion (Go)
A WebRTC library, not an SFU. Use it when you’re building a niche topology (one-to-many radio, mesh of small rooms, custom muxing) and don’t want LiveKit’s opinions. Plan on at least one experienced WebRTC engineer.
Reach for custom WebRTC when: you cross ~5M minutes/month, your auditors require all media-plane logs on infrastructure you control, or your product needs codecs/topologies an SDK won’t bend to.
If you’re comparing this path to your current SDK bill, the Agora.io alternative breakdown and the build-vs-buy video platform guide cover the migration mechanics in detail.
Path 3 — OpenAI Realtime over WebSocket or SIP
Skip the SFU entirely. Two flavours matter:
WebSocket bridge. Your backend opens a single WebSocket to OpenAI, accepts audio chunks from the user’s app over your own protocol, and forwards them. Lowest infrastructure cost, but you eat one extra network hop and lose WebRTC’s loss-recovery (RTX, FEC, NACK) on the user-facing leg.
SIP bridge. OpenAI’s Realtime API now accepts SIP INVITEs natively (the SIP endpoint is in beta in 2026, so a bridge pattern is the safe production default). Pair it with Twilio Programmable Voice or Telnyx and your AI agent picks up phone calls without you operating a single SFU. We’ve shipped two production systems on this pattern; latency is dominated by the PSTN leg, not OpenAI.
Reach for WebSocket/SIP when: the user reaches you by phone, by IoT device or through a backend integration — not through a browser or mobile app.
For deeper SIP and telephony patterns, see our AI call assistants API guide.
Comparison matrix — latency, cost, compliance, DevOps
All numbers below assume mono Opus audio, gpt-realtime-2.1-mini for latency-sensitive paths and gpt-realtime-2.1 for premium voices. Costs are infrastructure-only; OpenAI tokens add roughly $0.06–$0.10 per voice-minute for flagship voices (or $0.02–$0.05 on the mini tier) on top of every row.
| Stack | TTFA p50 | Infra $/min | Compliance fit | DevOps load | Sweet spot |
|---|---|---|---|---|---|
| LiveKit Cloud + Agents | 250–350 ms | ~$0.004 | SOC 2, GDPR; HIPAA via Enterprise | Low | v1, <1M min/mo |
| Agora Conversational AI | 280–380 ms | ~$0.001 base + tiers | SOC 2, HIPAA, GDPR | Low | Noisy retail, in-car, healthcare |
| Daily Bots | 260–360 ms | ~$0.005 | SOC 2, GDPR, BAA on request | Medium | Multi-vendor model swap |
| LiveKit OSS self-hosted | 240–320 ms | ~$0.001–$0.002 | Full data residency | High | 2M+ min/mo, regulated verticals |
| mediasoup self-hosted | 230–300 ms | ~$0.001 | Full data residency | Very high | 5M+ min/mo, ultra-scale rooms |
| WebSocket / SIP only | 350–700 ms | ~$0.0005 + telco | Depends on telco | Medium | Telephony, IoT, server jobs |
The matrix isn’t a leaderboard. It’s a fit table. The right row depends on your minutes/month, your auditors and your engineering bench.
Reference architecture for a ChatGPT streaming agent
Whether you choose SDK or custom, the production-grade architecture for a ChatGPT streaming integration looks the same in spirit. The pieces:
- Client SDK — LiveKit/Agora/Daily Web SDK or your own WebRTC wrapper. Handles SDP, ICE, mic capture, playback.
- SFU — Cloud or self-hosted. Routes audio between user and the agent worker.
- Agent worker — A small Python or Node service holding the OpenAI Realtime WebSocket. Runs as one process per active conversation.
- OpenAI Realtime API — Speech-to-speech model, function calling, transcript stream.
- Function-call gateway — HTTP service that the agent calls to read your DB, run RAG, charge a card, etc.
- Recording & transcript pipeline — Egress to S3/GCS plus a transcript event stream for analytics, compliance and replay.
- Observability — OpenTelemetry traces tying client mic-on → SFU forward → OpenAI response → client playout.
# Minimal LiveKit Agents worker for OpenAI Realtime (2026 API)
from livekit.agents import Agent, AgentSession, JobContext, WorkerOptions, cli
from livekit.plugins import openai
async def entrypoint(ctx: JobContext):
await ctx.connect()
session = AgentSession(
llm=openai.realtime.RealtimeModel(
model="gpt-realtime-2.1",
voice="alloy",
turn_detection={"type": "server_vad", "threshold": 0.55},
)
)
await session.start(
room=ctx.room,
agent=Agent(instructions="You are a helpful streaming co-host."),
)
await session.generate_reply()
if __name__ == "__main__":
cli.run_app(WorkerOptions(entrypoint_fnc=entrypoint))
That worker plus the LiveKit Cloud SFU is a working ChatGPT streaming integration in under a hundred lines. Everything beyond is hardening: RAG, function calls, recording, billing, fall-backs.

Figure 3. The seven-piece reference architecture, identical whether the SFU is managed or self-hosted.
Want this architecture pressure-tested?
We’ll review your reference diagram, flag the parts that won’t survive 1,000 concurrent agents, and hand back a hardening checklist.
Cost model — when custom beats the SDK bill
A worked example we’ve run with three of our 2026 clients. Assume an AI co-host platform: 100,000 voice-minutes per day, two participants per call (one human, one agent), simple function calling, no recording.
| Cost line | LiveKit Cloud + OpenAI | Self-hosted LiveKit + OpenAI |
|---|---|---|
| Audio track-minutes (3M/mo) | $12,000 | $0 (covered by infra) |
| SFU compute (4 nodes, Hetzner AX or AWS c7i) | included | ~$1,200/mo |
| Agent worker compute | ~$400/mo | ~$400/mo |
| TURN egress (assume 30% of traffic relayed) | included | ~$1,800/mo (Cloudflare R2 egress equivalent) |
| OpenAI Realtime tokens (~$0.07/min average) | ~$210,000/mo | ~$210,000/mo |
| Total | ~$222,400/mo | ~$213,400/mo |
At 3M minutes/month the SDK premium is roughly $9K/mo, meaningful but small next to the OpenAI bill. Below 1M minutes/month the SDK premium is <$3K/mo and self-hosting rarely pays back the engineering time. Above 5M minutes/month the gap widens past $30K/mo and the migration starts to look obvious.
A useful heuristic we use in scoping: if the SFU bill is <5% of your OpenAI bill, leave it alone. The $0.07/min token line above assumes flagship voices; a mini-first build lands nearer $0.02–$0.05/min and shrinks the OpenAI bill, the dominant cost, accordingly. Spend the engineering hours on prompt and function-call optimisation — that’s where the 30%+ savings live. (Any cost figures here are conservative defaults; we always re-quote against your actual concurrency and minutes profile.)
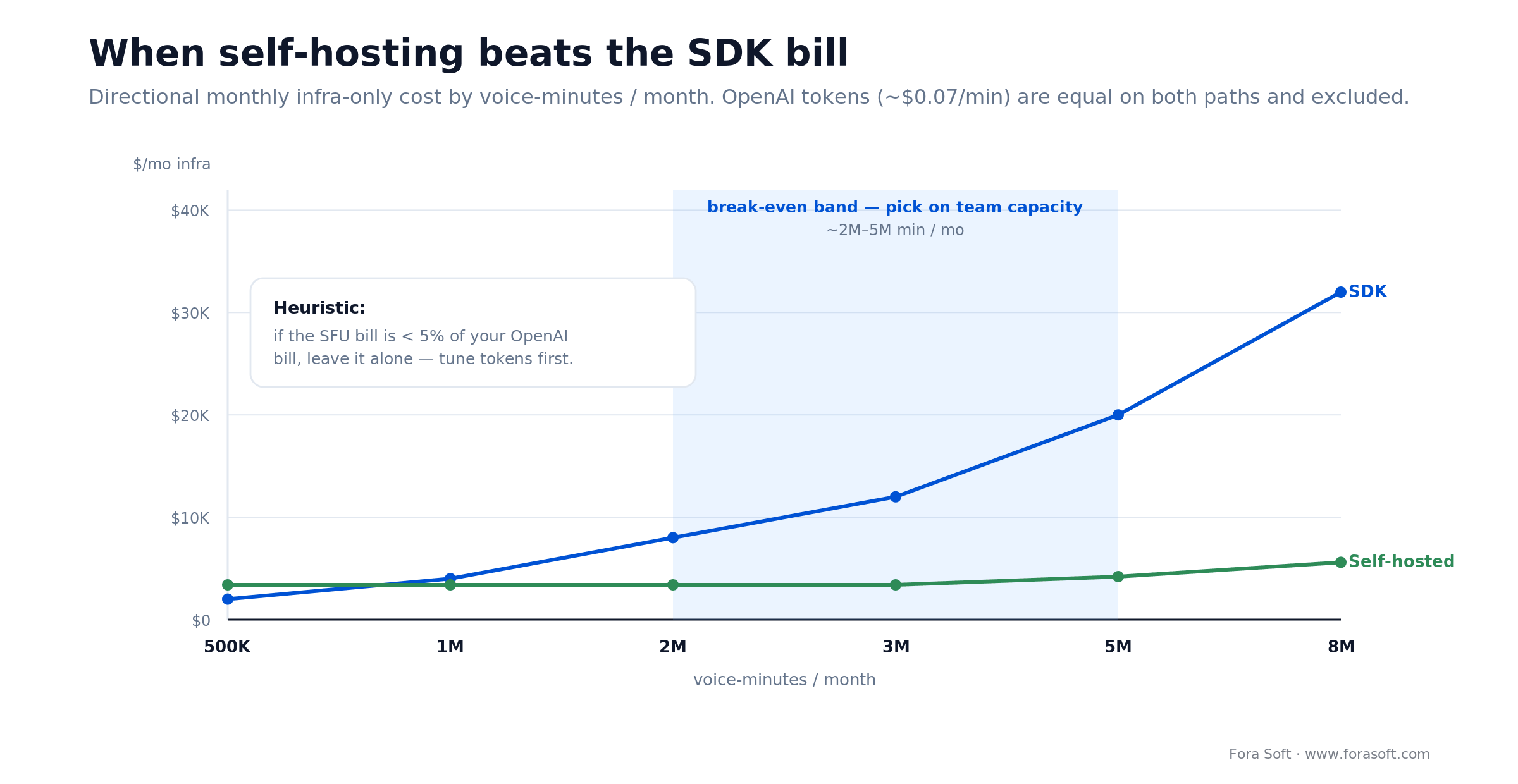
Figure 4. Infra-only cost by minutes/month: self-hosting pays off once you clear the break-even band.
Mini case — what 12 weeks of ChatGPT streaming shipped for us
Situation. A career-coaching platform — the team behind Career Point, an Oxford-collaboration product that closed $1.4M in funding — needed to ship an AI coaching MVP that felt as natural as a human session. The first prototype was a chat-only ChatGPT wrapper. Engagement was below 35% session completion.
12-week plan. We chose Path 1: LiveKit Cloud as the SFU, gpt-realtime-2.1 over WebRTC, a Python agent worker per session, server-side function calling into the user’s coaching plan and progress data. Weeks 1–3 went into prompt design and turn-detection tuning. Weeks 4–7 added function calling, the recording pipeline and EU data residency wiring. Weeks 8–10 covered observability and load testing to 800 concurrent agents. Weeks 11–12 were a controlled cohort rollout with A/B vs the chat baseline.
Outcome. Median time-to-first-audio landed at 290 ms (p95 410 ms). Session completion rose from 35% to 71%. Average session length doubled. The team did not need to operate a single SFU node. Want a similar 12-week assessment for your stack? Book a 30-min architecture review.
A different shape of the same playbook is running in production at Sprii (live shopping co-host) and TransLinguist (NHS UK contract, 30,000+ interpreters, 75+ languages). Same agent worker pattern, different transports.
A decision framework — pick your path in five questions
1. How many participant-minutes per month at steady state? Below 2M, default to a managed SDK. Between 2–5M it’s a tie — pick on team capacity. Above 5M, custom WebRTC starts to print money.
2. Where do the auditors need the audio to live? If your DPO insists on EU-only or on-premise media plane, custom WebRTC isn’t an option — it’s a requirement. SDKs offer regional clusters, but the SFU is still theirs.
3. What’s your latency target? Sub-300 ms TTFA needs WebRTC, full stop. Sub-200 ms typically needs gpt-realtime-2.1-mini and TURN colocated with the SFU. WebSocket-only architectures rarely clear 350 ms.
4. Do you have at least one engineer who has shipped WebRTC at production scale? If no, custom is a nine-month detour. The honest answer beats the optimistic one every time.
5. What’s your switching cost out of the SDK in 18 months? If your client SDK is a thin LiveKit/Agora wrapper, switching is weeks. If you’ve built proprietary signalling on top, it’s quarters. Pick a path you can leave.
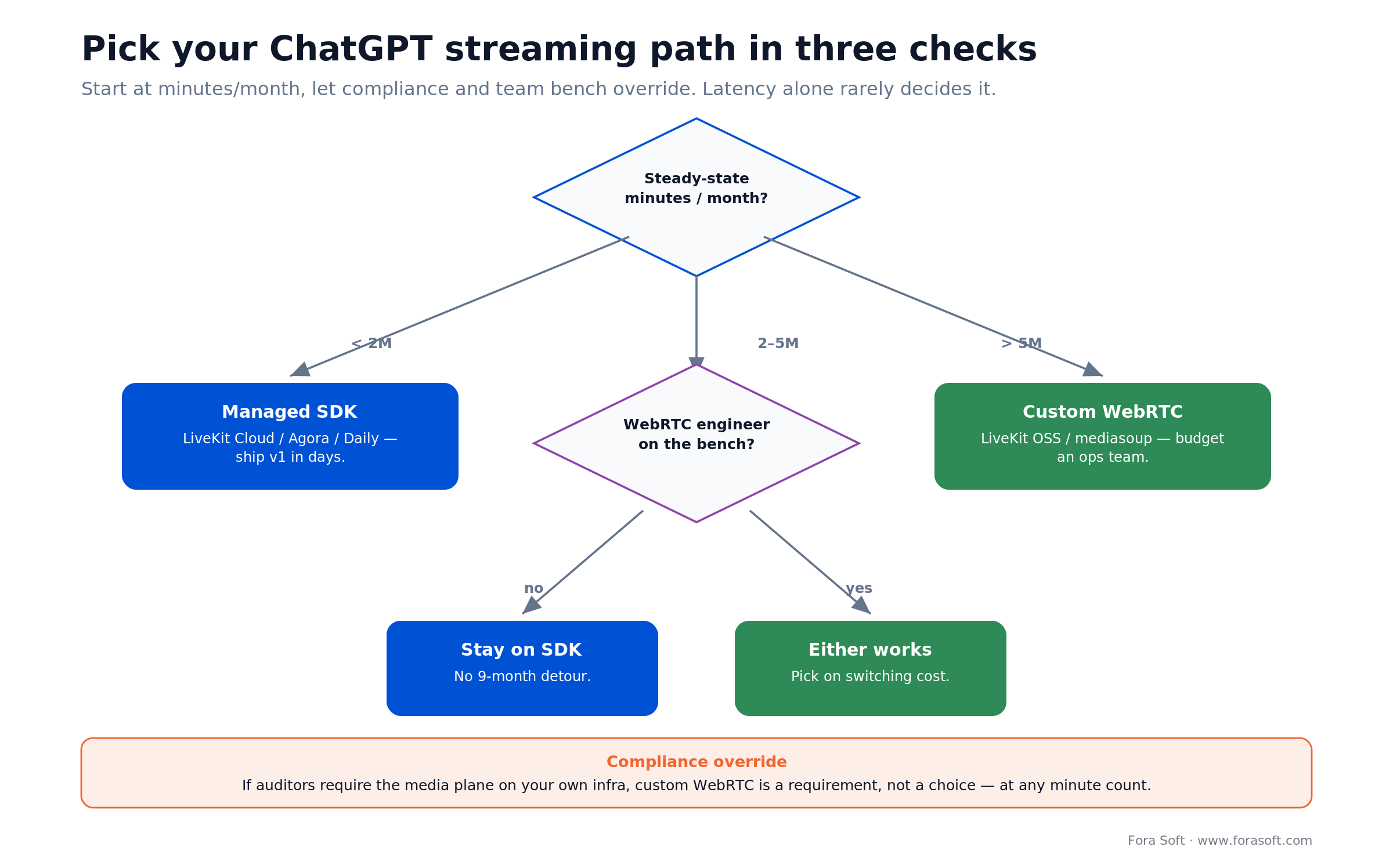
Figure 5. A three-check decision tree for choosing your ChatGPT streaming path.
Five pitfalls we see every month
1. Chained WebSockets pretending to be real-time. Browser → backend → OpenAI over two WebSockets adds 80–200 ms of avoidable latency and removes WebRTC’s loss recovery. If the user is on a browser, terminate the peer connection at an SFU.
2. Default VAD thresholds. The 0.50 default catches background noise as speech in cafes, cars and open-plan offices. Push to 0.55–0.65 and feed the agent your noise profile. Custom turn detection beats default VAD in noisy environments by 20–30 percentage points on false-trigger rate.
3. No barge-in playback truncation. When the user interrupts, the client must stop the current TTS frame within 100 ms. Most SDKs handle this automatically; custom clients regularly miss it and double-talk for half a second.
4. TURN servers in the wrong region. A US TURN relay for an EU user adds 90 ms of one-way latency you’ll never recover. Place TURN within 50 ms RTT of your largest user clusters or pay an SDK to do it for you.
5. No backpressure on function calls. The agent will happily call your DB three times before you’ve answered the first request. Wrap function tools in a small queue with a 1.5-second timeout and a graceful fallback.
KPIs — what to measure before and after launch
Quality KPIs. Time-to-first-audio (target p50 <350 ms, p95 <500 ms), MOS or POLQA >4.0, word error rate on your domain <3%, false barge-in rate <5% of turns. These tell you whether the conversation feels alive.
Business KPIs. Session completion rate, average session length, function-call success rate, conversion or retention lift versus the non-AI baseline. If these don’t move within 30 days of launch, you have a UX problem, not a model problem.
Reliability KPIs. Connection success rate (target >99.5%), agent-restart-per-session, ICE failure rate by network type, OpenAI 5xx rate, p99 token-stream stall >1 s. Wire these into PagerDuty before your first paying customer joins.
Security and compliance for AI streaming
HIPAA. OpenAI offers a BAA on the Enterprise plan with a 0-day data retention option. LiveKit, Agora and Daily all sign BAAs on their enterprise tiers. The weakest link is usually your own recording pipeline, not the model or SFU.
GDPR. Use the EU residency option on OpenAI Enterprise and pin your SFU to an EU region. Your DPA with each vendor needs to list the model name, data categories and retention windows; we maintain a template our enterprise clients reuse.
SOC 2. Both LiveKit and Agora ship Type II reports. OpenAI’s SOC 2 covers the API but not your prompts — those are your responsibility, including PII redaction in logs.
E2EE. True end-to-end encryption breaks any in-room AI agent — the agent needs cleartext to listen. The compromise we recommend is per-session media encryption with a clear “AI is listening” consent flow and recording controls scoped to the user.
When NOT to use ChatGPT streaming integration
Three patterns where you should pump the brakes:
Async use cases. If the user can wait 5+ seconds (summaries, content generation, batch transcription), you’re paying real-time premiums for nothing. Use the standard chat or batch APIs.
Strict E2EE products. Messengers and healthcare consult tools that promise mathematical privacy can’t put a server-side model in the path. Either drop the AI feature in those flows or run a smaller on-device model.
Workloads dominated by a single non-realtime function call. If 80% of the latency budget is your CRM lookup, no transport will save you. Fix the lookup first.
Need a second opinion on SDK vs custom?
We’ll review your minutes profile, compliance constraints and team bench — then send a written recommendation within 48 hours.
FAQ
Does OpenAI’s Realtime API actually support WebRTC, or do I have to bridge?
Yes. As of 2026 you exchange SDP with OpenAI over a small HTTPS handshake and the resulting peer connection carries Opus audio in both directions. WebSocket and SIP transports are still supported, but WebRTC is the default for in-browser and in-app voice.
What latency can I realistically promise users?
A well-tuned ChatGPT streaming integration over WebRTC delivers p50 time-to-first-audio of 250–350 ms and p95 under 500 ms on broadband. Mobile networks add 50–120 ms; congested LTE adds more. Aim for <550 ms p95 to keep conversations natural.
How much does ChatGPT streaming integration cost per minute?
OpenAI’s gpt-realtime-2.1 family lands at roughly $0.06–$0.10 per voice-minute for the flagship voices; the gpt-realtime-2.1-mini tier is cheaper, around $0.02–$0.05 per minute with prompt caching. SFU costs add ~$0.001–$0.005 per minute on top, so total is usually $0.07–$0.11/min. Cache long system prompts to cut input audio cost roughly in half. For a full token-math teardown, see our OpenAI Realtime API pricing guide.
Can I run ChatGPT streaming inside my existing Agora or Twilio video product?
Yes. Agora’s Conversational AI Engine and Twilio’s ConversationRelay both bridge to OpenAI Realtime out of the box. The work is on your agent worker (prompts, function calls, tool integrations), not on the transport.
When is custom WebRTC actually faster than an SDK?
In our benchmarks, custom only wins on latency when you co-locate TURN with the SFU and the agent worker in the same datacenter as the user. That’s 30–50 ms of savings: meaningful for some products, invisible for most. Pick custom for cost or compliance, not raw latency.
How do I handle barge-in correctly?
When VAD detects user speech, send response.cancel to OpenAI and stop client audio playback within 100 ms. LiveKit, Agora and Daily handle both halves automatically; if you’re on custom, audit the playback path with frame-level timing logs.
Is LiveKit better than Agora for ChatGPT streaming?
For most teams, yes — LiveKit Cloud is cheaper, the agent SDK is more ergonomic and the OSS path keeps the door open. Agora wins on noise suppression and on regions where its data centres are closer to your users than LiveKit’s. We compare the two in detail in our Agora alternative breakdown.
What does a realistic engineering timeline look like?
An MVP ChatGPT streaming integration on a managed SDK takes a small team 4–6 weeks. A production-grade rollout with function calls, recording, observability and SOC 2 evidence is 10–14 weeks. Custom WebRTC adds a quarter on top. With Agent Engineering on our side we’ve compressed several of those phases by 30–40%.
What to Read Next
SDK vs custom
Agora.io alternative in 2026: custom WebRTC with LiveKit, mediasoup, Jitsi & Janus
A side-by-side cost and capability comparison for teams considering a migration off Agora.
Voice AI
Build voice AI that actually sounds human with LiveKit
A practical playbook for VAD, turn-detection and prompt design on top of LiveKit Agents.
Multimodal
2026 LiveKit multimodal agents guide: voice, vision & production
Where to put the camera and microphone when your agent needs to see and hear.
Build vs buy
Build vs buy: switching from SDK to custom video platform
The migration playbook we use when an SDK bill outgrows the engineering investment.
Telephony
AI call assistants: a practical guide to third-party APIs for business software
SIP, telephony providers and how to wire them into the same OpenAI Realtime stack.
Ready to ship your ChatGPT streaming integration?
If you’re below 2M minutes/month, start on a managed SDK plus OpenAI’s Realtime API over WebRTC. Above 5M minutes/month or under hard data-residency rules, plan a custom WebRTC build — LiveKit OSS or mediasoup — and budget for the ops team. The latency story is essentially the same on both paths; the unit economics and audit posture are not.
The five-question framework above will tell you which path to take. The pitfalls section will keep you out of the most common holes. The KPI bucket will tell you whether the integration is actually working. Everything else is execution, and that’s where our AI integration team comes in.
Let’s scope your ChatGPT streaming integration
30-minute architecture review with a senior engineer who has shipped this stack — you leave with a written recommendation.








